
八问八答搞懂Transformer内部运作原理
八问八答搞懂Transformer内部运作原理七年前,论文《Attention is all you need》提出了 transformer 架构,颠覆了整个深度学习领域。
来自主题: AI技术研报
10350 点击 2024-08-07 14:31
 搜索
搜索
七年前,论文《Attention is all you need》提出了 transformer 架构,颠覆了整个深度学习领域。
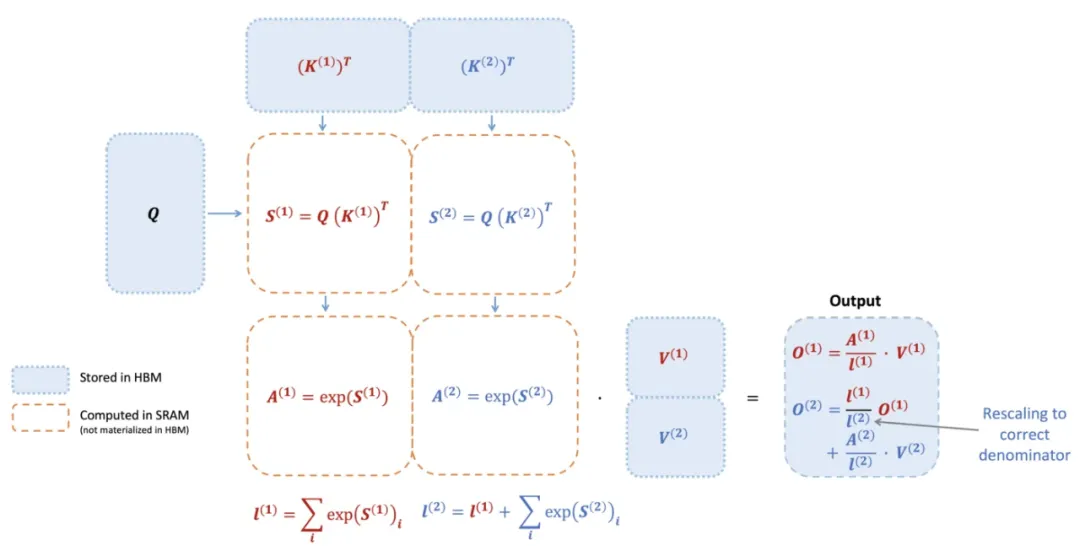
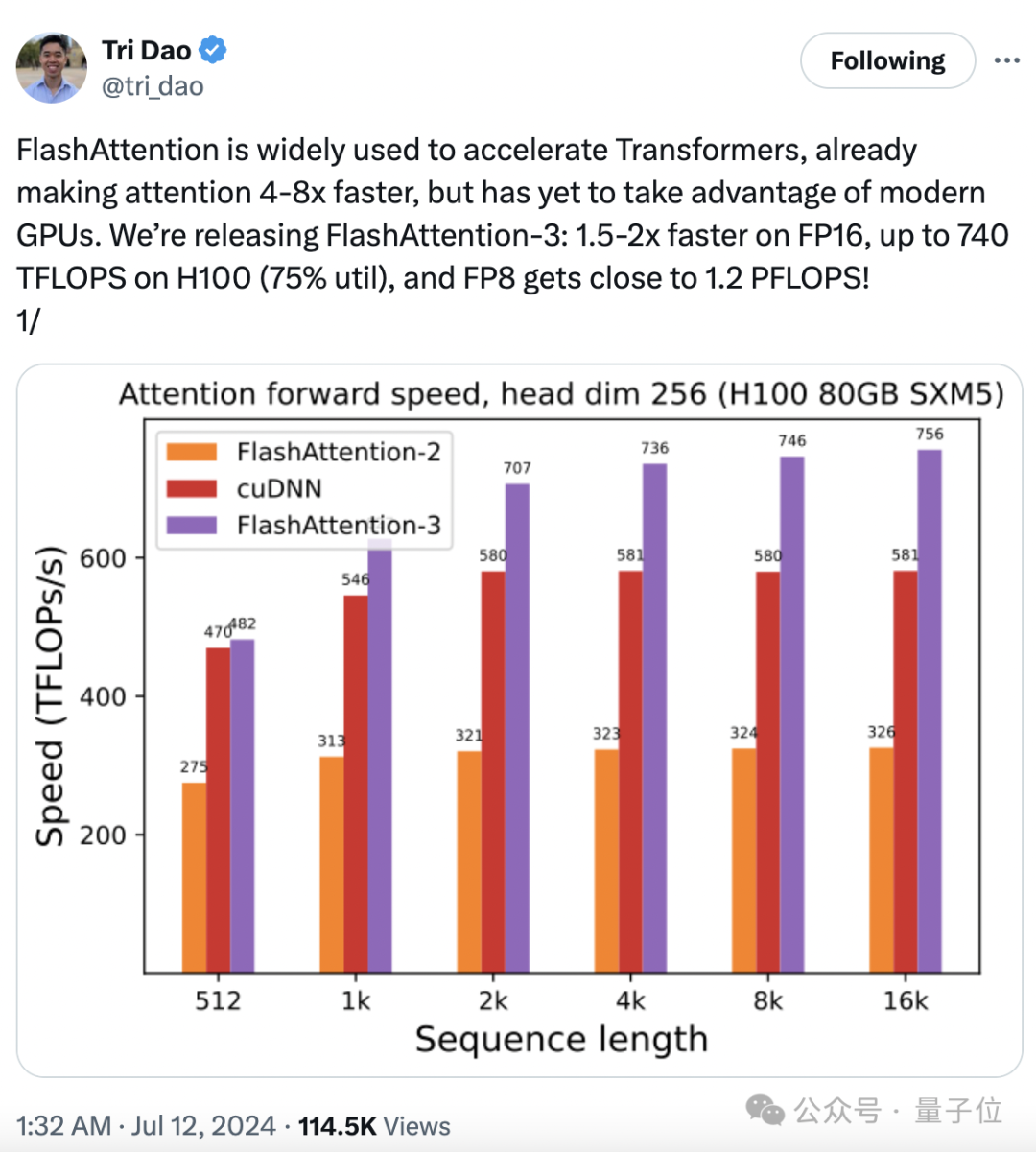
740 TFLOPS!迄今最强 FlashAttention 来了。

时隔一年,FlashAttention又推出了第三代更新,专门针对H100 GPU的新特性进行优化,在之前的基础上又实现了1.5~2倍的速度提升。
大模型训练推理神作,又更新了!
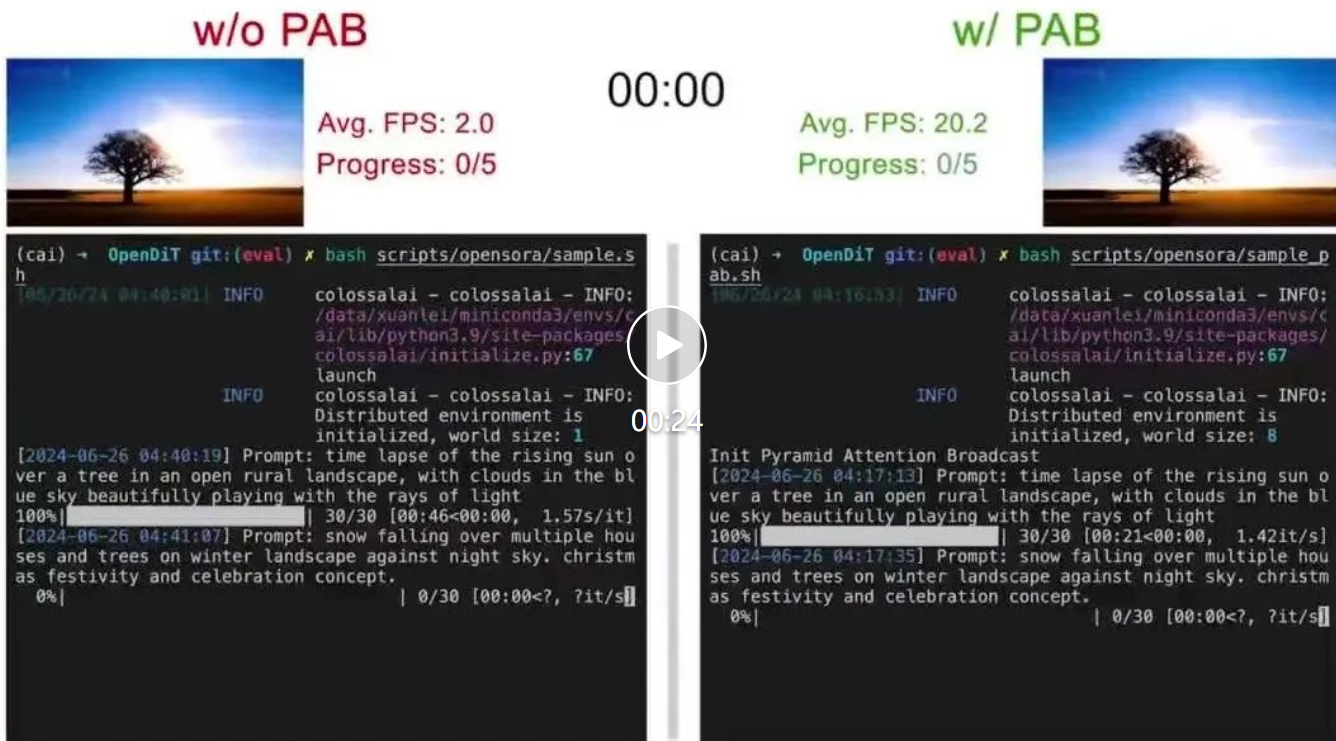
尤洋团队新作,首个基于DiT的实时视频生成方法来了!

AI算力资源越发紧张的当下,斯坦福新研究将GPU运行效率再提升一波——

如何突破 Transformer 的 Attention 机制?中国科学院大学与鹏城国家实验室提出基于热传导的视觉表征模型 vHeat。将图片特征块视为热源,并通过预测热传导率、以物理学热传导原理提取图像特征。相比于基于Attention机制的视觉模型, vHeat 同时兼顾了:计算复杂度(1.5次方)、全局感受野、物理可解释性。

众所周知,大语言模型的训练常常需要数月的时间,使用数百乃至上千个 GPU。以 LLaMA2 70B 模型为例,其训练总共需要 1,720,320 GPU hours。由于这些工作负载的规模和复杂性,导致训练大模型存在着独特的系统性挑战。

Mamba时代来了?

以大规模著称的Transformer,在实际应用中的高算力和高成本,让不少中小型企业望而却步。