
速递|英特尔获Google大单:代工超300万颗TPU,2028年交付
速递|英特尔获Google大单:代工超300万颗TPU,2028年交付The Information 周一报道称,Google 在数月测试这家芯片制造商的技术后,决定委托英特尔生产部分张量处理单元(TPU)。该媒体指出,由于台湾芯片制造商台积电的产能持续供不应求,英特尔正从 Google 等企业获得订单。
来自主题: AI资讯
8940 点击 2026-06-14 10:43
 搜索
搜索
The Information 周一报道称,Google 在数月测试这家芯片制造商的技术后,决定委托英特尔生产部分张量处理单元(TPU)。该媒体指出,由于台湾芯片制造商台积电的产能持续供不应求,英特尔正从 Google 等企业获得订单。

2026年6月,个人AI助手Town完成5500万美元A轮融资,由a16z领投,Forerunner、First Round、Conviction等机构跟投。在Agent赛道高度拥挤的背景下,这笔融资释放了一个明确信号
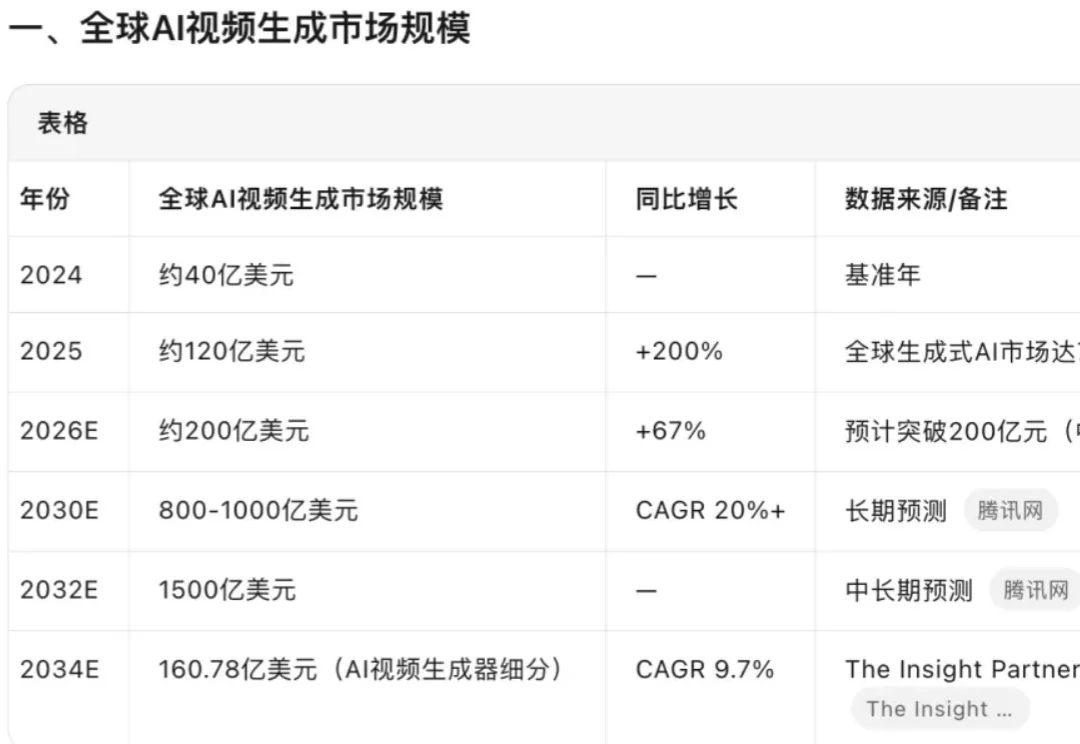
我最近专门调研了一下AI短视频🧐。发现市场规模是越来越大。
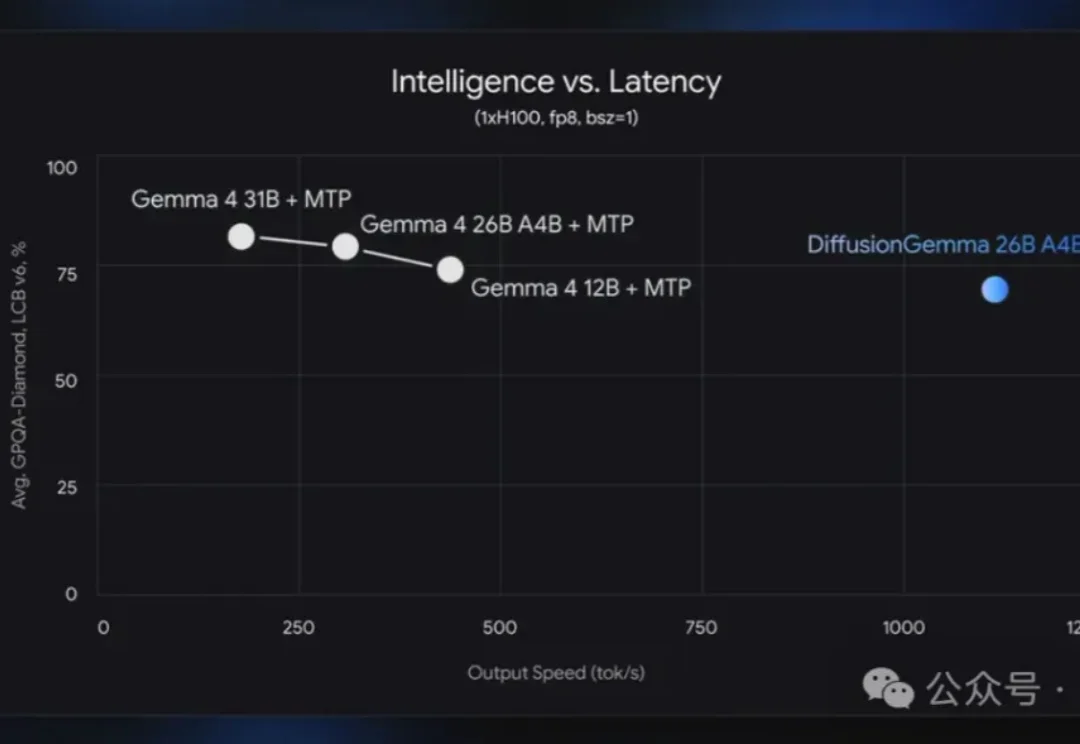
就在刚刚,谷歌闷头干了件大事:把生成图片的扩散模型,拿来写文字了,而且一出手就是4倍加速。 新模型名为DiffusionGemma,它直接抛弃了传统自回归那套“逐Token生成”的打字机模式,而是像“印刷机”一样工作——

Dario Amodei 又写长文了。
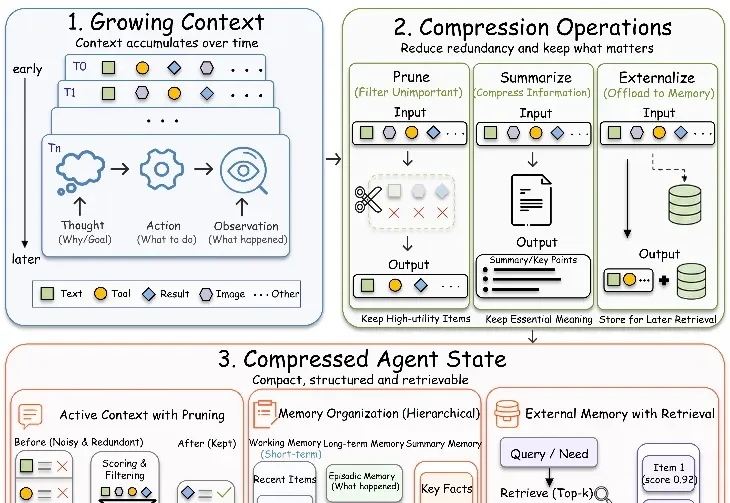
LLM Agent 做长任务时,真正让人头疼的往往不是模型不会推理,而是上下文开始失控:前几步还很清楚,后面就忘约束、丢状态、重复试错,最后把任务跑成事故现场。

今天一早,谷歌又发新模型了!

靠盘活4600个节点,做到“中国第一”。
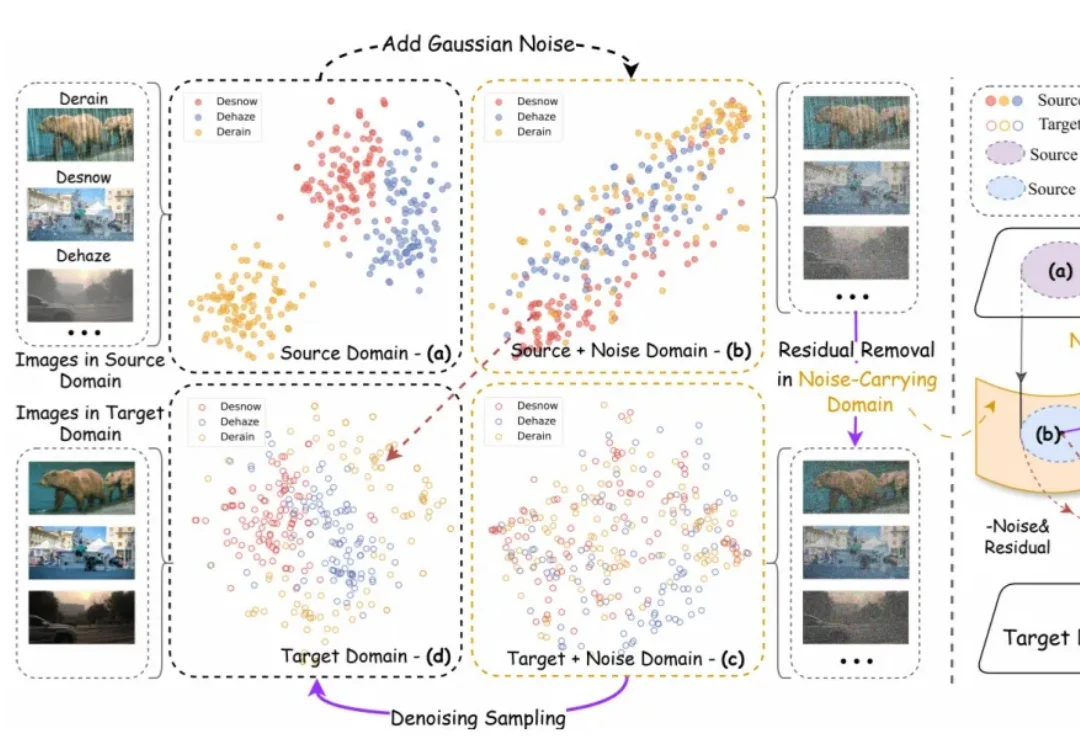
在图像到图像翻译(Image-to-Image Translation, I2I)这个任务上,扩散模型过去几年几乎形成了一套默认逻辑:先把输入图像和噪声混合,再一步步去噪,把目标图像 “还原” 出来。

顶级AI编码一日千里,到了生物学领域却频频翻车,并非模型不够聪明,而是科学数据库至今只为人类点鼠标而生。