
这一次,不比炫技,比谁更能「干活」
这一次,不比炫技,比谁更能「干活」5 月 15 日,杭州西湖云栖小镇。经过前两天雨水的洗礼,春末夏初的空气里透着清新,风也温柔。但小镇里的各大机器人,可顾不上「感受」这份惬意…… 一台四足机器人小心翼翼踩过碎石路,踉跄两步稳住身体,继续执行变电站智能巡检任务;几米外,另一台四足机器人穿过倒塌的废墟,一头钻进模拟浓烟中,展开搜救工作。
来自主题: AI资讯
8304 点击 2026-05-17 11:10
 搜索
搜索
5 月 15 日,杭州西湖云栖小镇。经过前两天雨水的洗礼,春末夏初的空气里透着清新,风也温柔。但小镇里的各大机器人,可顾不上「感受」这份惬意…… 一台四足机器人小心翼翼踩过碎石路,踉跄两步稳住身体,继续执行变电站智能巡检任务;几米外,另一台四足机器人穿过倒塌的废墟,一头钻进模拟浓烟中,展开搜救工作。
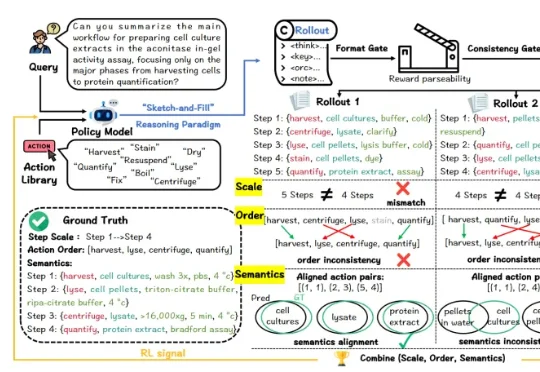
针对这一问题,上海人工智能实验室、复旦大学、上海交通大学团队提出了Thoth:一个面向生物实验protocol生成的科学推理模型。一句话概括:Thoth不是让模型“写得像protocol”,而是让模型按照实验逻辑,生成可解析、可评估、可执行的protocol。
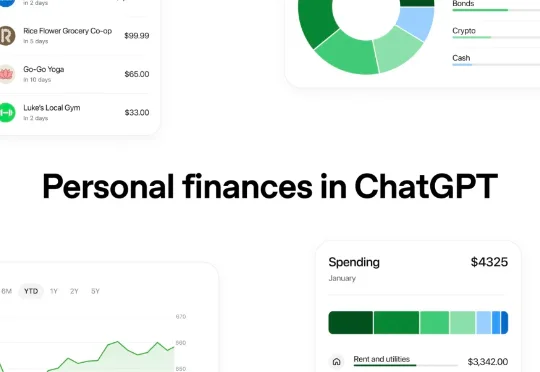
OpenAI 推出了一个让很多人「既兴奋又不安」的新功能——ChatGPT 个人理财工具。简单说,你现在可以把自己的银行账户、投资账户直接连到 ChatGPT 里了。这个功能目前仅面向美国地区的 ChatGPT Pro 用户(月费 200 美元)开放预览。
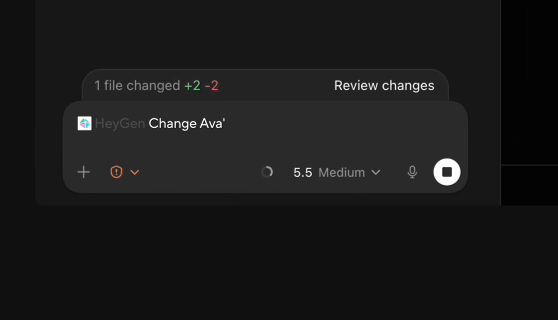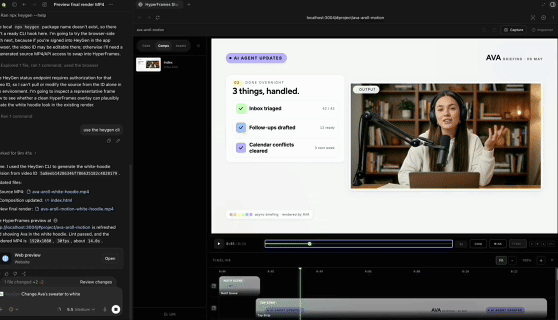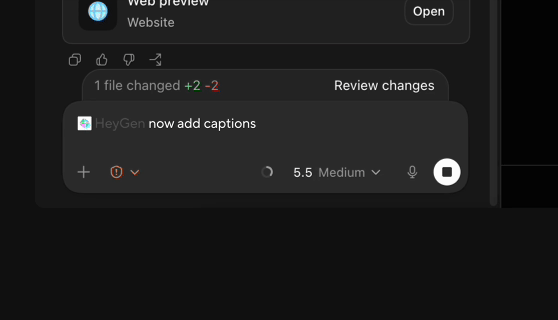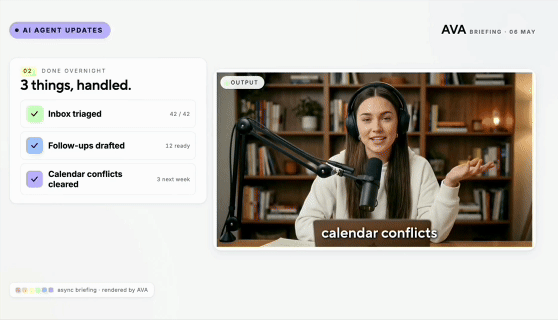
传统视频制作N个产品来回横跳的工作流模式,这次可能真的要Game Over了?因为嘛——现在你只用跟Codex说一句话,它就能把剪辑、PS、视频生成等一箩筐子的活儿全包了!!

浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。

最近一两年,AI 行业有一个很微妙的变化:大家不再满足于问 “模型会不会回答”,也不再只关心 “Agent 能不能调用工具”。越来越多的讨论开始回到一个更终极的问题:AI 到底能不能完全自动化接管工作区,理解个性化需求,像一个真实的人类劳动力一样,把一件事情从头到尾做完?

上次给大家写了《Codex教程》之后,评论区里陆陆续续冒出来好多问题。问的最多的,是土区订阅 ChatGPT Plus 的事。既然是已经存在的定价差异,还有那么多人不知道,那就写,写清楚,手把手教到会为止。
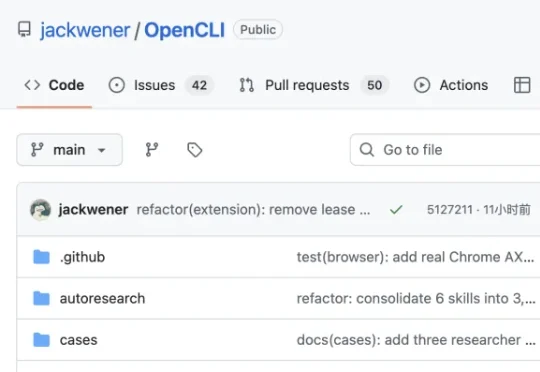
每次想让AI读个外部网站的信息,看到这句话头都要炸了。不过,GitHub有个开源项目OpenCLI把这事儿解决了:网站变命令行。Reddit讨论、B站热门、Arxiv论文,以前开浏览器一个个翻的东西,现在终端一行命令直接出结构化数据。

最近,吴恩达发了篇长文,对着「AI 就业末日论」就是一顿疯狂输出。他指出,这种过度夸大的失业恐慌不仅是不负责任的,且极具破坏性。在这场焦虑蔓延的背后,隐藏着 AI 初创公司拉高估值与传统企业掩盖决策失误的双重利益诉求。

为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。