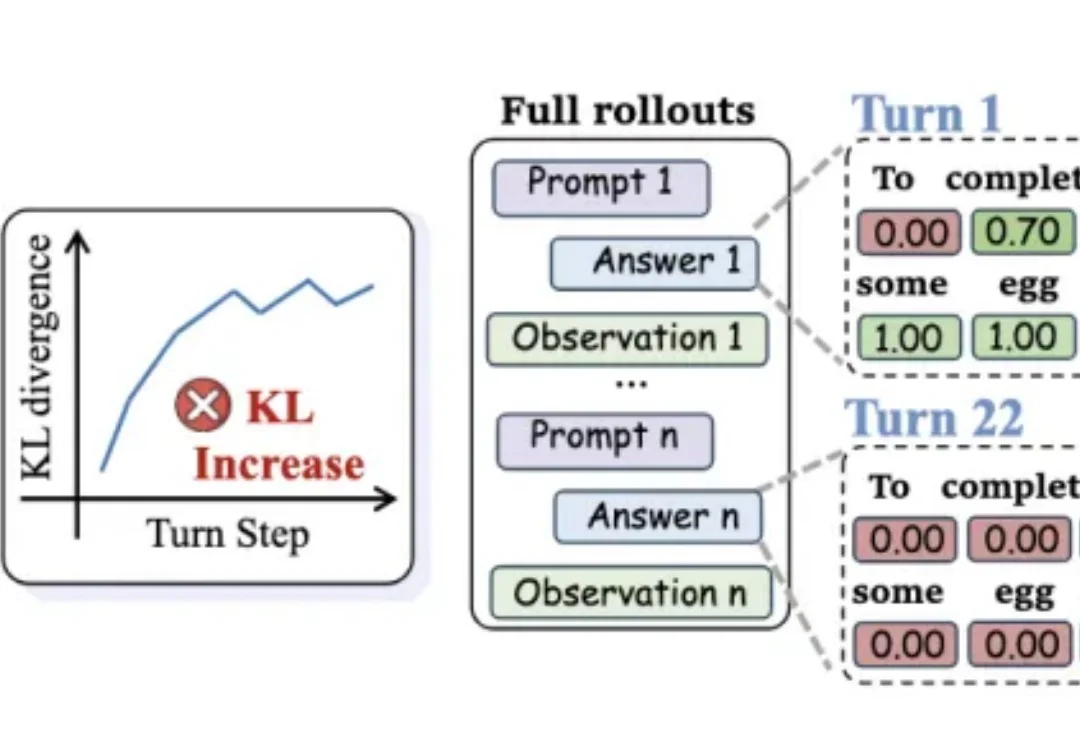
多轮Agent蒸馏终于不翻车!港中文x通义新方法成功率暴涨18点,训练还快32%
多轮Agent蒸馏终于不翻车!港中文x通义新方法成功率暴涨18点,训练还快32%把强大模型的能力“蒸馏”给小模型,听起来很美—— 但放到多轮对话Agent场景里,效果往往一塌糊涂。
来自主题: AI技术研报
8603 点击 2026-05-07 10:17
 搜索
搜索
把强大模型的能力“蒸馏”给小模型,听起来很美—— 但放到多轮对话Agent场景里,效果往往一塌糊涂。

Agent Skills不应该只以SKILL.md、README或自然语言说明文档的形式存在,而应该被转成一种机器可检索、可检查、可治理的结构化表示。这是《From Skill Text to Skill Structure: The Scheduling-Structural-Logical Representation for Agent Skills》这篇论文的核心主张。

当Agent开始真正进入生产环境,安全问题不再是「功能模块」,而是贯穿调用链、运行时与生态层的系统性风险。过去依赖提示词规则、日志审计与框架级防护的方式,正在逐步失效。来自清华大学人工智能学院、交叉信息研究院的方寸跃迁提出一套面向Agent运行全生命周期的多层安全体系。

Salesforce CEO Marc Benioff近日甩出一份招聘计划:要一口气招进1000名应届生或实习生,与他们一起搭乘AI快车。IBM更猛,北美入门级岗位直接扩招3倍,麦肯锡、Cognizant紧跟其后。智能体时代,一批10年前根本不存在的「金饭碗」正在批量诞生,应届生这个词,也将被重写。

AI 员工得能和真实的人交流,能接收文件,能在一个稳定的环境里持续运转。GenSpark 4.0 在这一层做得很到位。它可以和联系人直接对话,并且原生集成了 MyClaw,不需要用户自己去安装 OpenClaw 再配置到飞书或微信。

2026年5月4日,testingcatalog在Anthropic的Web/Mobile客户端里挖出隐藏功能Orbit。5月6日,Code with Claude大会在旧金山开幕。Orbit不等你开口就从Gmail、Slack、GitHub里替你干活了。
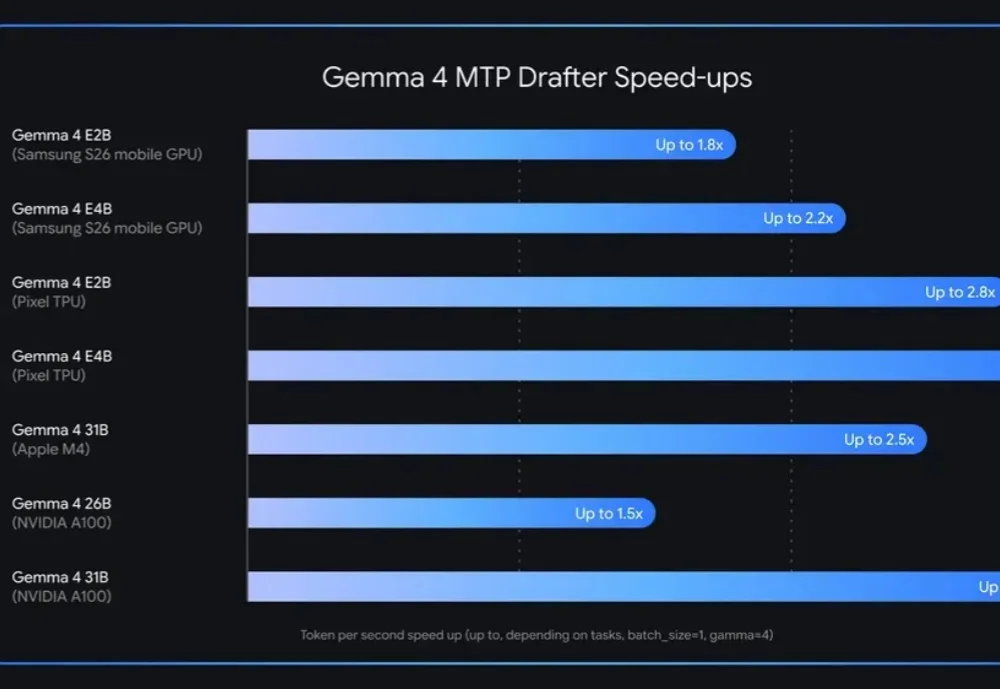
谷歌刚刚给Gemma 4家族更新了一项关键能力:Multi-Token Prediction(MTP)推测解码架构,推理速度最高提升3倍,输出质量不变。
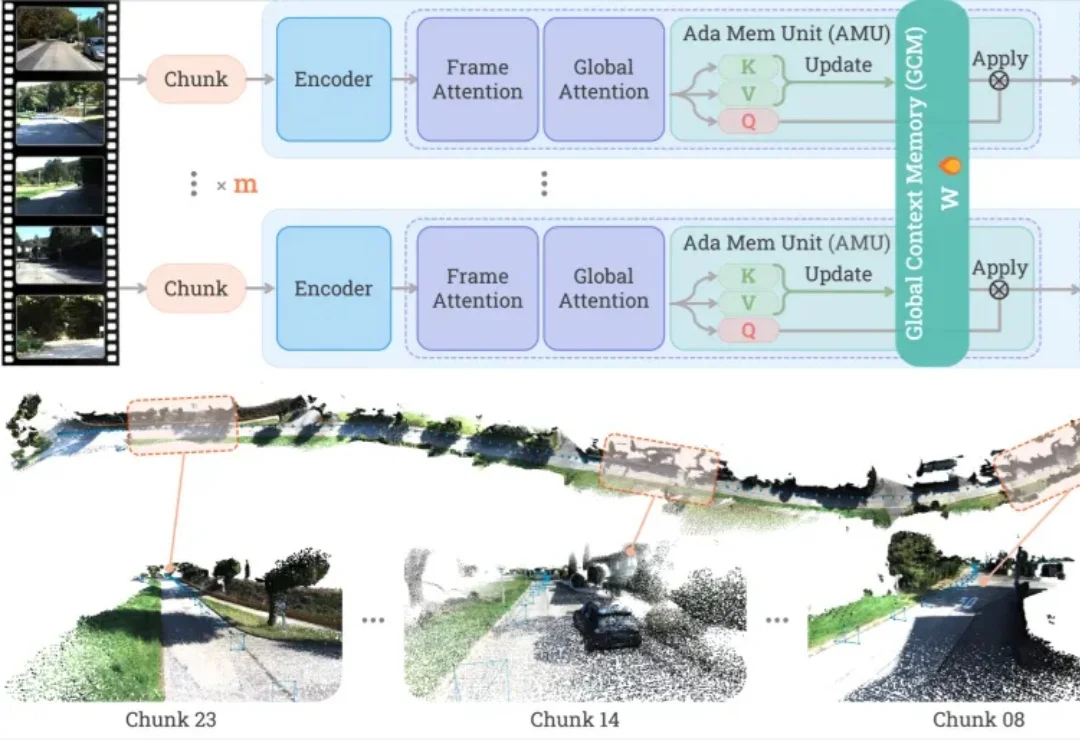
长视频 3D 重建最怕的,其实不是 "看不清"。

AI最好的用途,是改善人类健康。 如果真正把这项技术用在科学和医学上,它不仅能解决今天最难的研究问题,也会打开药物发现和疾病理解的一整串下游可能性。

用强化学习(RL)优化文生图模型的 prompt following 能力,是一条被广泛验证的路径 —— 让模型根据 prompt 用不同随机种子生成多张图片,通过 reward model 计算 reward,再利用相关 RL 算法优化模型。