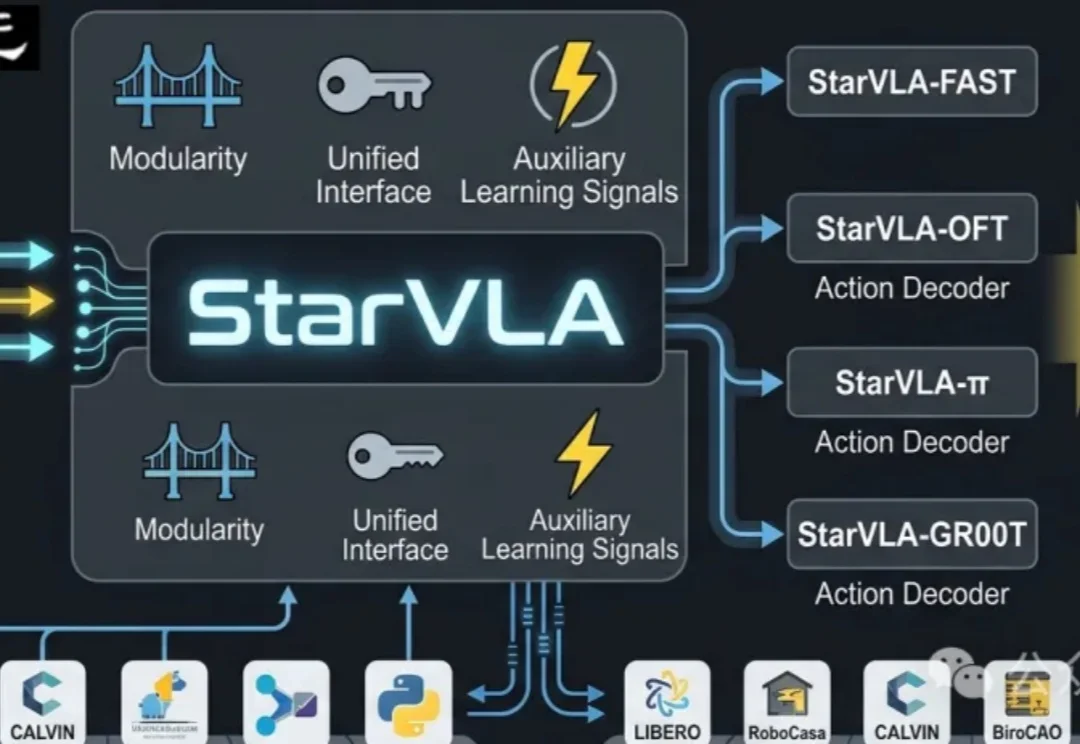
统一VLA范式!港科大开源StarVLA乐高式架构,复现成本大幅降低
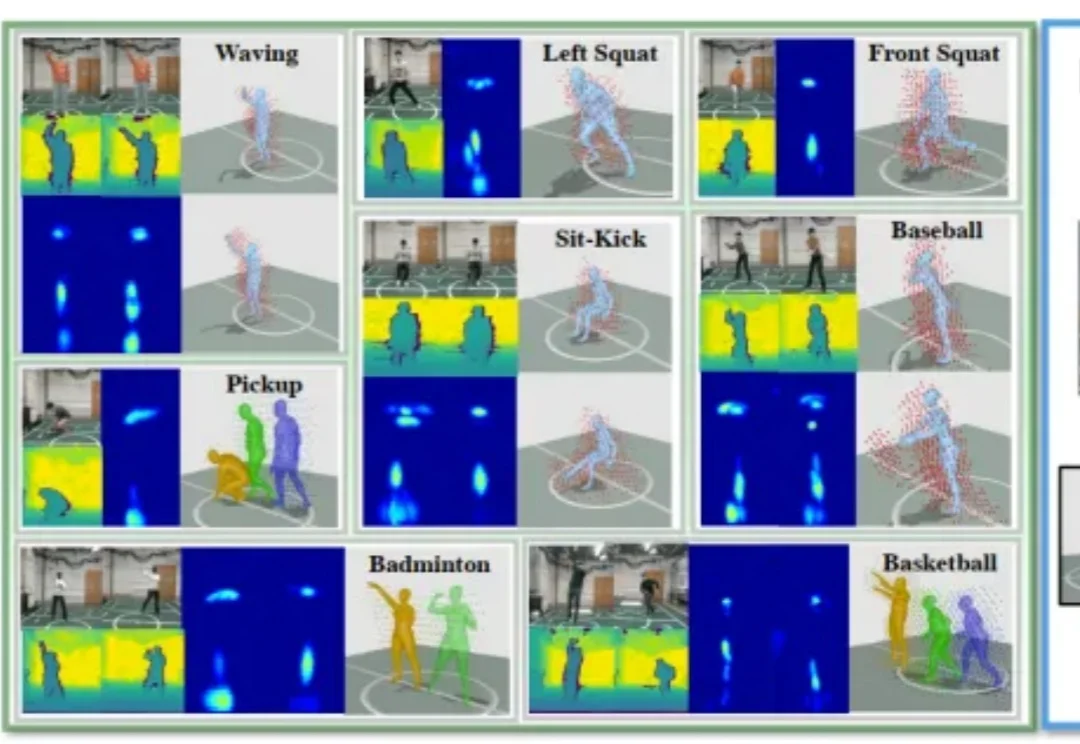
统一VLA范式!港科大开源StarVLA乐高式架构,复现成本大幅降低当前具身智能的VLA(Vision-Language-Action)赛道正陷入典型的「碎片化」泥潭:不同团队采用异构的动作解码范式、强耦合的数据管线、互不兼容的评测协议,导致方法难以横向对比,复现成本极高。
来自主题: AI技术研报
9202 点击 2026-04-14 08:42
 搜索
搜索
当前具身智能的VLA(Vision-Language-Action)赛道正陷入典型的「碎片化」泥潭:不同团队采用异构的动作解码范式、强耦合的数据管线、互不兼容的评测协议,导致方法难以横向对比,复现成本极高。
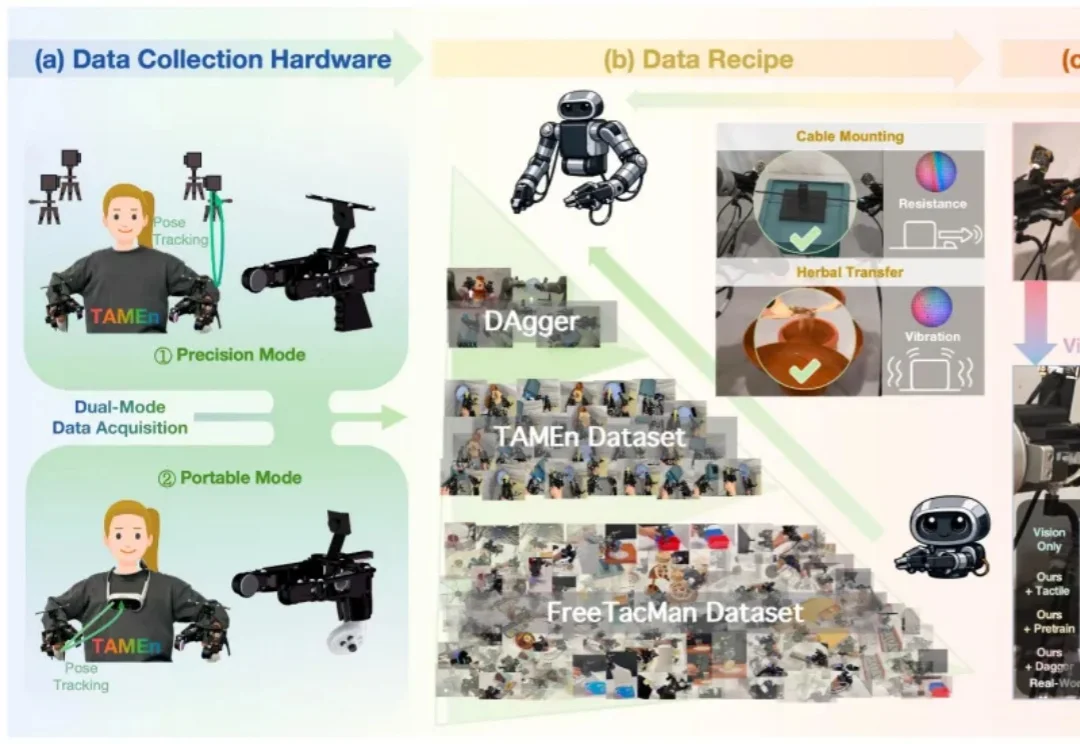
在具身智能快速发展的今天,高质量数据已成为驱动能力提升的关键基础,然而一个核心问题也随之而来: 如何让机器人数据采集更快、更稳、更有效?

让一个模型概括“这是一段什么视频”,并不难。

2026年具身智能这么热, 美国旧金山PI Robotics这家机器人创业公司, 你真得知道。

Claude最强“神话”模型,可能用到来自字节的技术?

硅谷新宠Hermes Agent一夜爆火,不仅在GitHub狂揽6.6万星,更因原生接入微信让开发者全线沸腾。如今,Hermes署名的首篇「顶会级」论文也出世了。如今,这款历经9个月打磨,一夜成名的Agent,已在GitHub上狂揽66k星,Fork有8.8k。
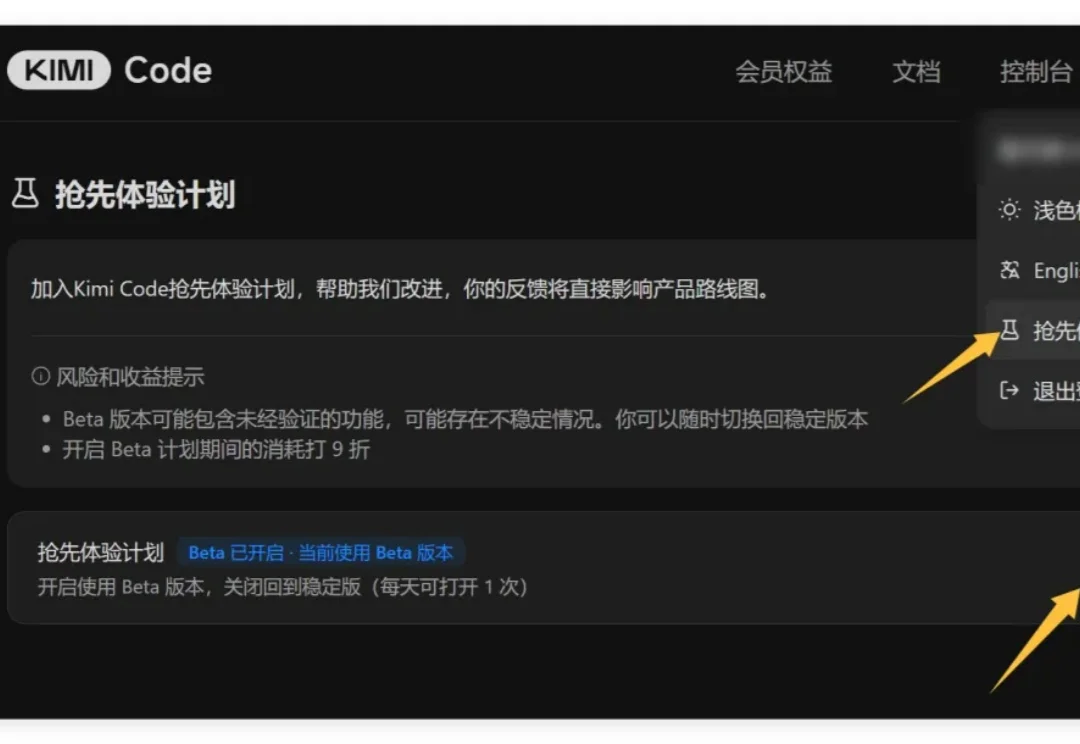
刚测完 Kimi K2.5,就拿到 Beta 版内测模型了。 一点喘息的机会都不给啊~~
前两天办完大会,然后昨天周末跟一个朋友吃饭,聊着聊着他突然放下筷子看着我说了一句,不是哥们,你怎么什么都懂一点?
想象几个并不遥远的场景: 医院的病房里,刚做完手术的患者正在练习下床、走动,智能系统通过摄像头捕捉他的动作,判断步态是否稳定、有没有跌倒风险;回到家,在卧室或浴室这样私密的空间里,老人起身、转身、洗漱,甚至意外滑倒的瞬间,也可能被视觉传感器记录,只为了让 AI 能更早发现异常;

“你好,老板,你这个视频我们用即梦Seedance 2.0 生成,这一条视频报价1235.25元人民币,我们分分钟就可以用这1609.45元做出来这条视频,这可是仅仅2235.32元人民币就能换来的视频爆款,都不知道有多划算,我们产出一条视频仅需要一天,白天开工,到了晚上您只需要支付3245.98元就可以了,现在签合同吗?”