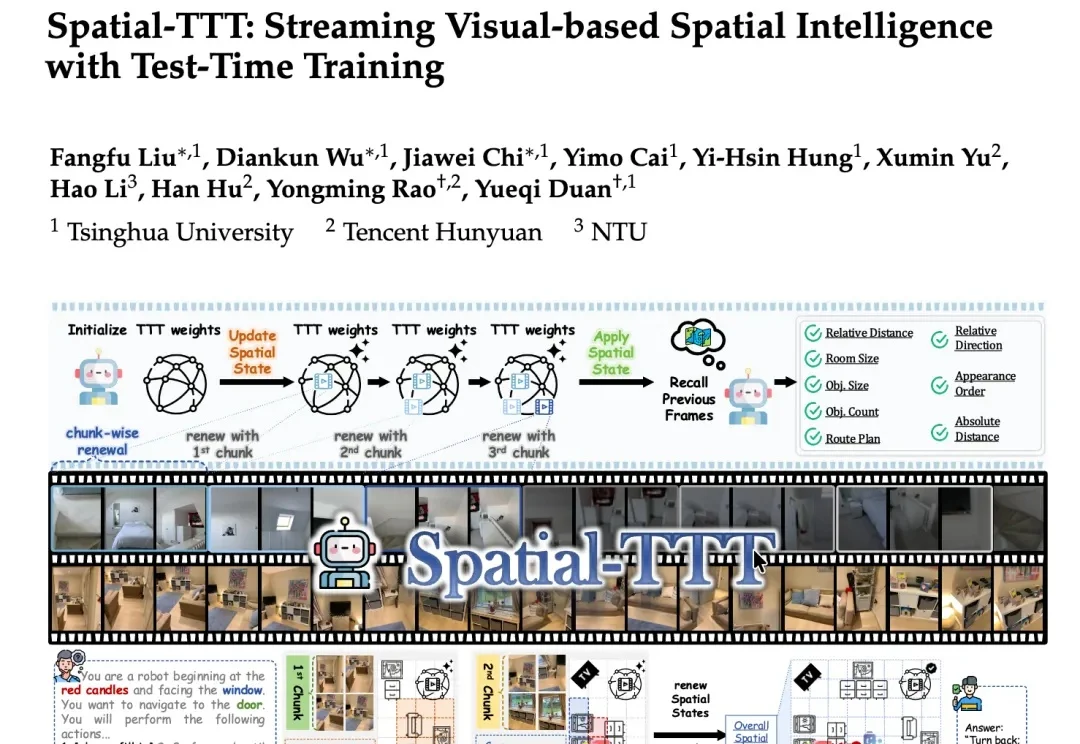
入选ECCV 2026!清华开源空间模型打败Gemini:真正的空间智能是在世界变化中持续学习
入选ECCV 2026!清华开源空间模型打败Gemini:真正的空间智能是在世界变化中持续学习在机器人、自动驾驶、AR等真实场景中,空间理解从来都不是“看一眼图像”就能解决的问题。
来自主题: AI技术研报
6176 点击 2026-06-22 15:16
 搜索
搜索
在机器人、自动驾驶、AR等真实场景中,空间理解从来都不是“看一眼图像”就能解决的问题。
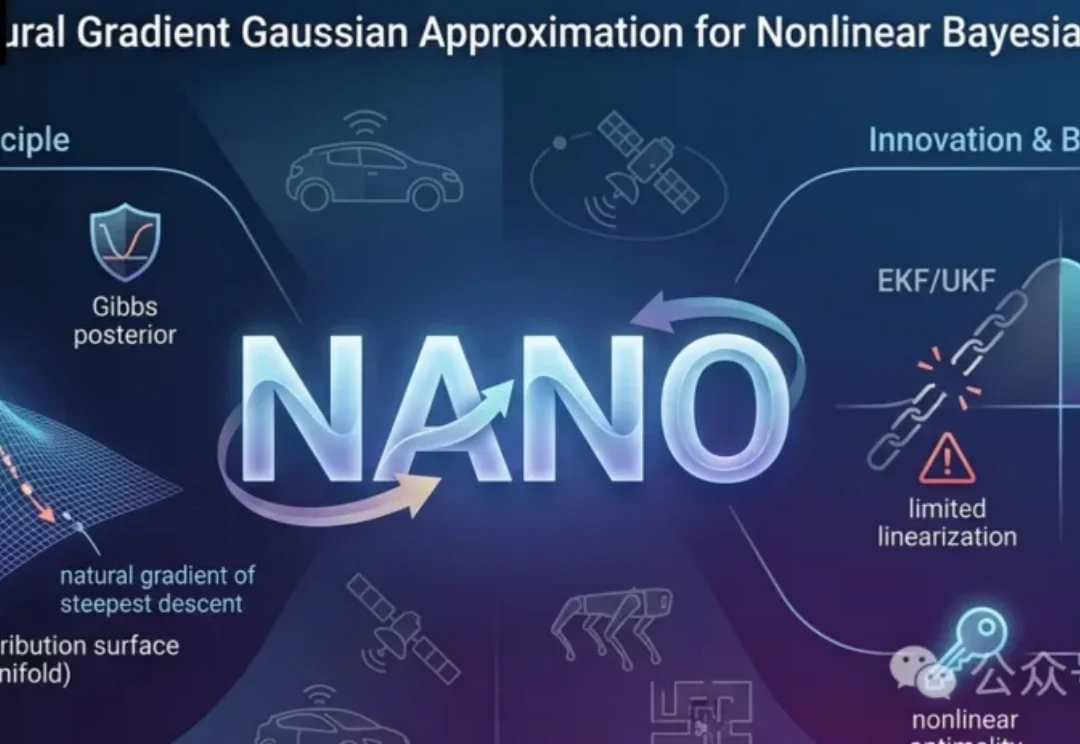
NANO滤波器是一种新的非线性贝叶斯状态估计方法,它不依赖线性化模型,而是将预测和更新步骤转化为优化问题。这种方法在高斯分布空间中使用自然梯度,更精确地逼近最优后验,同时利用Stein引理避免显式求导,提升鲁棒性。
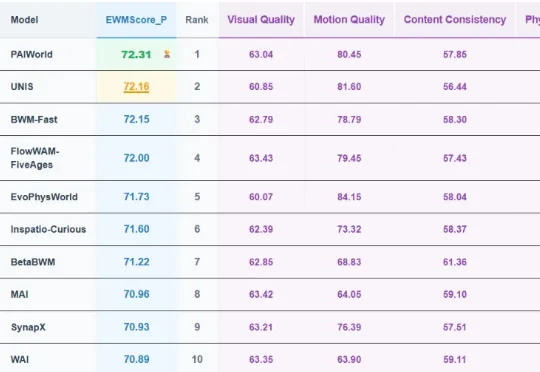
日前,世界模型国际权威榜单 WorldArena 更新排名,中国科学院工业人工智能研究所徐凯研究员带领物理智能团队(The PAI Lab)自研的世界模型 PAIWorld 登顶。WorldArena 作为目前世界模型领域最权威的评测榜单,是针对具身世界模型的全方位评价体系,涵盖视觉质量、运动质量、内容一致性、物理遵循、三维准确性及可控性六大维度

我们最近在重新思考一件事:到底什么样的 Benchmark,才值得今天继续做?

当AI神话被账本照亮,最刺眼的真相终于浮出水面。退潮时刻,狂欢结束。探照灯打过来,谁在裸泳,一目了然。

自从AI爆发以来,所有人都在追问同一个问题:AI时代的护城河到底是什么?

每月一两千,把数字员工用到起飞。
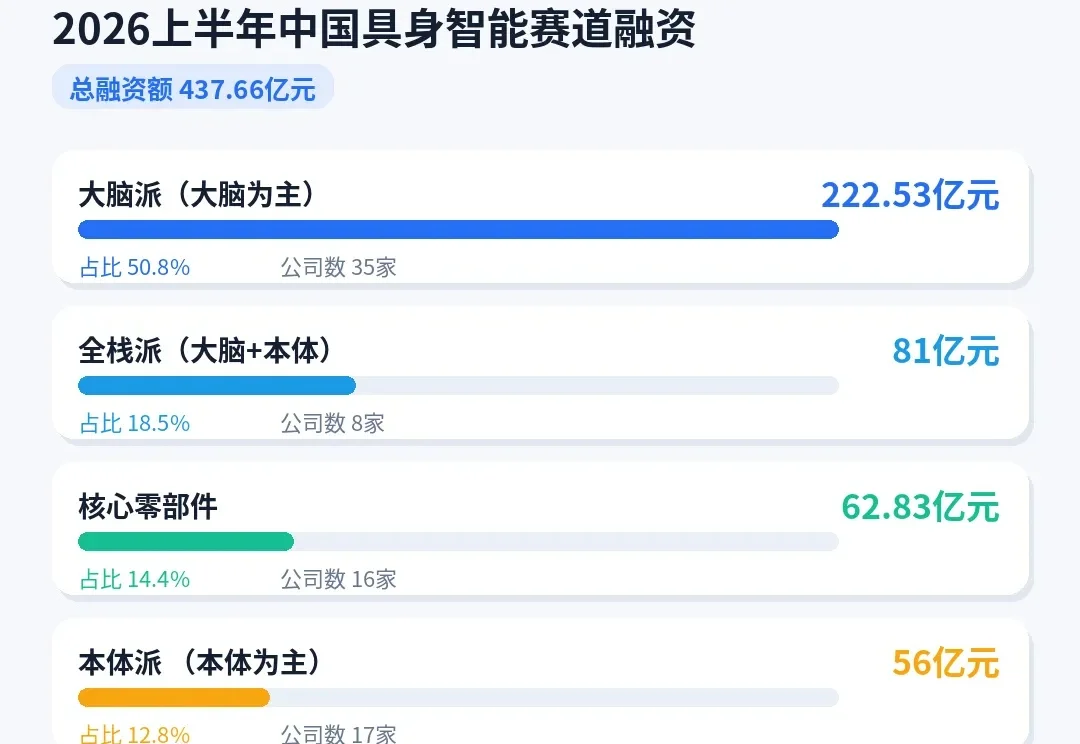
具身智能领域的资本,正在涌向机器人的“大脑”。

就在最近,OpenAI扔出一篇重磅论文。他们发现,只教AI好好看病,它写代码居然也不作弊了。方法简单到离谱:拿5%的训练数据,教模型在回答健康问题时诚实、谨慎、知错能改。

刚刚, OpenAI、Google DeepMind、Anthropic三大AI巨头CEO与G7领导人在法国阿尔卑斯山共进工作午餐,历史首次。上一次这些领导人坐在一起,讨论的是二毛、中东、全球供应链这些问题。现在AI公司的CEO被请到了同一张桌子上。