
人形机器人首次打通视觉感知与运动断层,UC伯克利华人博士让宇树G1现场演示
人形机器人首次打通视觉感知与运动断层,UC伯克利华人博士让宇树G1现场演示不用提前熟悉环境,一声令下,就能让宇树机器人坐在椅子上、桌子上、箱子上!
来自主题: AI技术研报
9367 点击 2025-06-25 17:22
 搜索
搜索
不用提前熟悉环境,一声令下,就能让宇树机器人坐在椅子上、桌子上、箱子上!

上世纪 90 年代末,我还是伯克利的一名学生,目睹了当年互联网诞生期的繁荣如同一场狂热的梦一样展开。

关于大模型产生幻觉这个事,从2023年GPT火了以后,就一直是业界津津乐道的热门话题,但始终缺乏系统性的重磅研究来深入解释其根本机制。今天,伯克利的研究者们带来一个重要研究成果:让基于Transformer架构的语言模型产生幻觉的机制,恰恰也是让它们拥有超强泛化能力的关键。这就像是一枚硬币的两面,您想要哪一面,就得接受另一面的存在。
大语言模型解决不等式证明问题时,可以给出正确答案,但大多数时候是靠猜。推理过程经不起推敲,逻辑完全崩溃。

给大模型当老师,让它一步步按你的想法做数据分析,有多难?
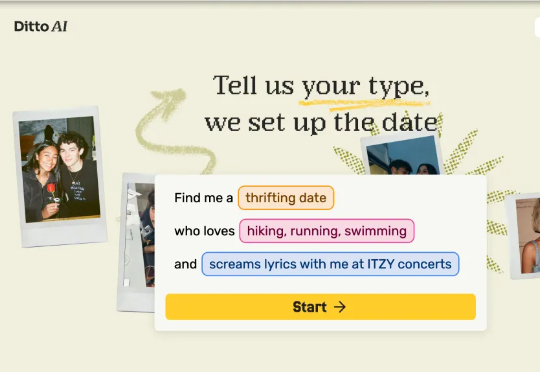
只管填个资料,AI 就帮你搞定一切:从精准匹配到约会地点的挑选,再到时间安排,甚至还附赠一张定制化「约会海报」。最后,只需要拎包出门,赴一场线下约会。这不再是科幻剧《黑镜》的剧情,而是加州大学伯克利分校两位辍学 00 后学生打造的 Ditto——一款试图用 AI 重塑恋爱方式约会应用。
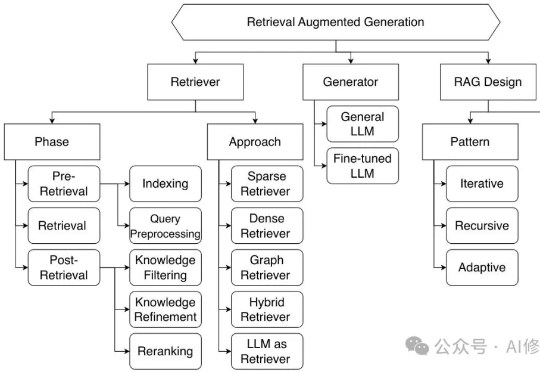
2024年,伯克利人工智能研究中心(BAIR)率先提出了一个新概念——复合人工智能系统(Compound AI Systems,简称CAIS)。这个看似简单的术语背后,蕴含着AI系统架构的根本性改变:不再依赖单一LLM的"超级大脑",而是构建多组件协同的"智能生态系统"。
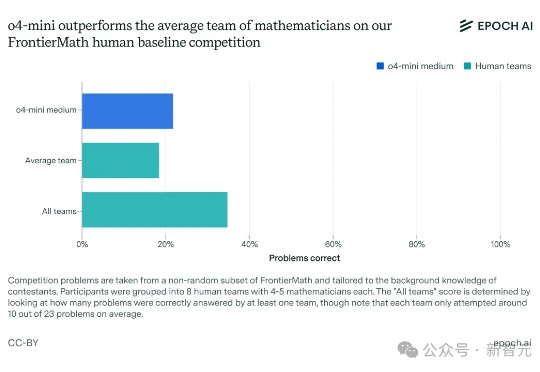
最近,30位世界顶尖数学家亲自出马,在UC伯克利对OpenAI o4-mini展开「围剿」,两天连出教授级难题,结果却当场集体「破防」!有人直言:这个AI,的确已接近数学天才的水平。曾经以为AGI遥遥无期,如今仿佛只剩临门一脚了……

来自华盛顿大学、AI2、UC伯克利研究团队证实,「伪奖励」(Spurious Rewards)也能带来LLM推理能力提升的惊喜。

而马毅是那类觉得不够的人,他于无声处开始提问:智能的本质是什么?自 2000 年从伯克利大学博士毕业以来,马毅先后任职于伊利诺伊大学香槟分校(UIUC)、微软亚研院、上海科技大学、伯克利大学和香港大学,现担任香港大学计算与数据科学学院院长。他和团队提出的压缩感知技术,到现在还在影响计算机视觉中模式识别领域的发展。