
全球掀DeepSeek复现狂潮!硅谷巨头神话崩塌,30刀见证啊哈时刻
全球掀DeepSeek复现狂潮!硅谷巨头神话崩塌,30刀见证啊哈时刻就在刚刚,网上已经出现了一波复现DeepSeek的狂潮。UC伯克利、港科大、HuggingFace等纷纷成功复现,只用强化学习,没有监督微调,30美元就能见证「啊哈时刻」!全球AI大模型,或许正在进入下一分水岭。
来自主题: AI资讯
10108 点击 2025-01-26 13:30
 搜索
搜索
就在刚刚,网上已经出现了一波复现DeepSeek的狂潮。UC伯克利、港科大、HuggingFace等纷纷成功复现,只用强化学习,没有监督微调,30美元就能见证「啊哈时刻」!全球AI大模型,或许正在进入下一分水岭。

研究者提出了FAST,一种高效的动作Tokenizer。通过结合离散余弦变换(DCT)和字节对编码(BPE),FAST显著缩短了训练时间,并且能高效地学习和执行复杂任务,标志着机器人自回归Transformer训练的一个重要突破。
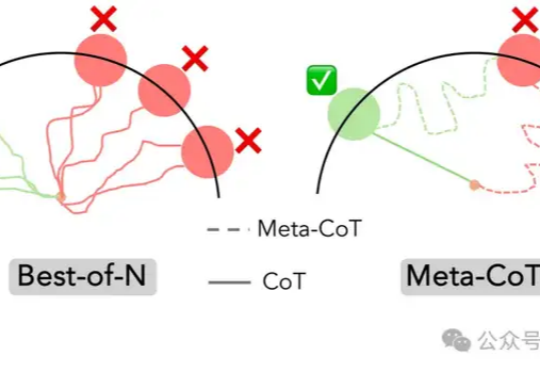
o1背后的推理原理,斯坦福和伯克利帮我们总结好了!
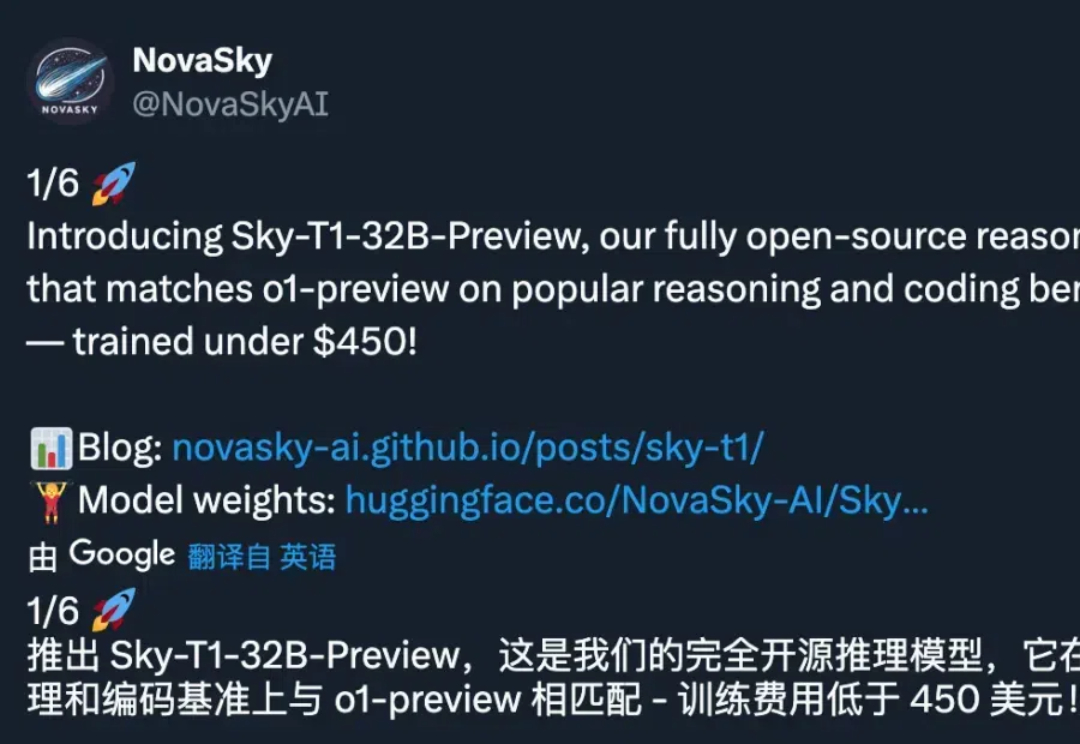
450 美元的价格,乍一听起来不算「小数目」。但如果,这是一个 32B 推理模型的全部训练成本呢?

LLM 强大的语言能力,使其被广泛部署于 LLM 应用系统(LLM-integrated applications)中。此时,LLM 需要访问外部数据(如文件,网页,API 返回值)来完成任务。

通用语言模型率先起跑,但通用视觉模型似乎迟到了一步。究其原因,语言中蕴含大量序列信息,能做更深入的推理;而视觉模型的输入内容更加多元、复杂,输出的任务要求多种多样,需要对物体在时间、空间上的连续性有完善的感知,传统的学习方法数据量大、经济属性上也不理性...... 还没有一套统一的算法来解决计算机对空间信息的理解。

LLM 规模扩展的一个根本性挑战是缺乏对涌现能力的理解。特别是,语言模型预训练损失是高度可预测的。然而,下游能力的可预测性要差得多,有时甚至会出现涌现跳跃(emergent jump),这使得预测未来模型的能力变得具有挑战性。

代码模型可以自己进化,利用自身生成的数据来进行指令调优,效果超越GPT-4o直接蒸馏!

如果给LLM做MBTI,会得到什么结果?UC伯克利的最新研究就发现,不同模型真的有自己独特的性格

半年两次大融资后,这家具身智能黑马再次获得融资!作为柏睿资本首次投资的具身智能企业,千寻智能不仅拥有出身自伯克利系联创,在技术、硬件、商业化上,也让人极有信心。