
再也不怕显存爆炸了!高效重建「几何精准」的大规模复杂三维场景,中科院提出CityGaussianV2
再也不怕显存爆炸了!高效重建「几何精准」的大规模复杂三维场景,中科院提出CityGaussianV2来自中科院自动化所的研究团队提出了用于大规模复杂三维场景的高效重建算法CityGaussianV2,能够在快速实现训练和压缩的同时,得到精准的几何结构与逼真的实时渲染体验。
来自主题: AI技术研报
8805 点击 2024-12-13 14:32
 搜索
搜索
来自中科院自动化所的研究团队提出了用于大规模复杂三维场景的高效重建算法CityGaussianV2,能够在快速实现训练和压缩的同时,得到精准的几何结构与逼真的实时渲染体验。

双深科技近日获得来自上市公司富瀚微(300613.SZ)的数千万元人民币战略投资。双深科技成立于2020年,是一家致力于用AI技术颠覆传统图像和视频压缩与处理的AI创业公司。团队研发实力雄厚,核心成员均来自国内外顶尖高校,并数次在国际人工智能顶级会议CVPR夺得图像与视频编解码领域的全球冠军,奠定了公司在技术上的领先地位。
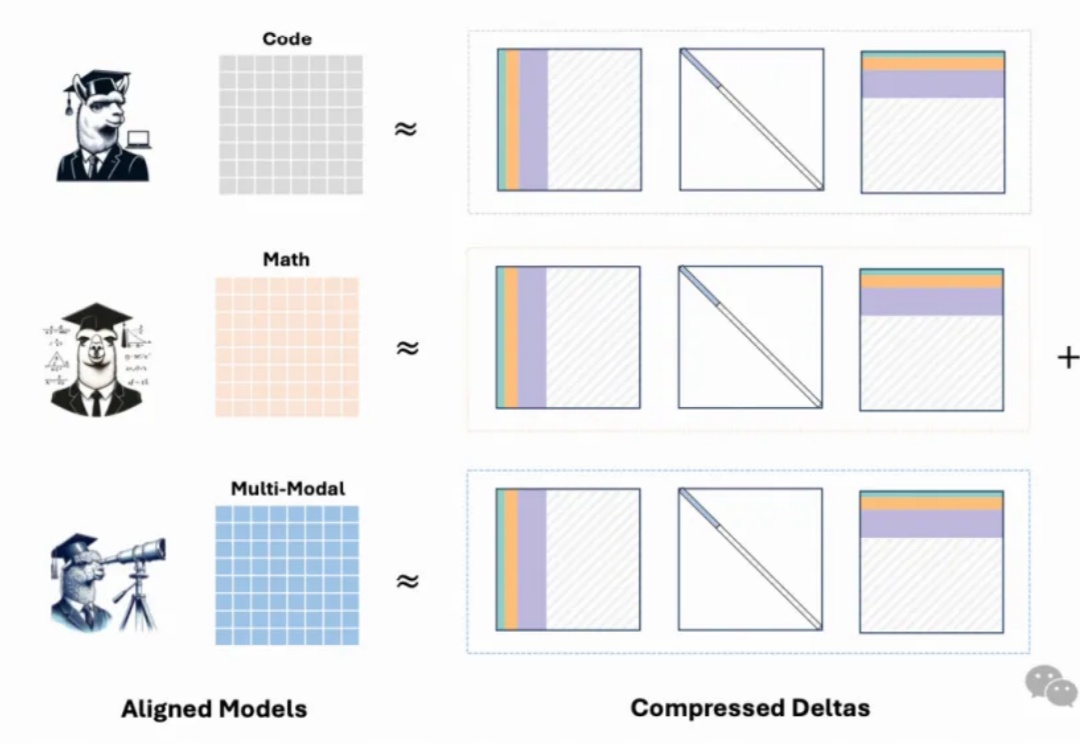
最新模型增量压缩技术,一个80G的A100 GPU能够轻松加载多达50个7B模型,节省显存约8倍,同时模型性能几乎与压缩前的微调模型相当。

近日,人形机器人公司1X公布了世界模型挑战赛的二阶段:Sampling。一同登场的还有合作伙伴英伟达新发布的Cosmos视频分词器,超高质量和压缩率助力构建虚拟世界。
Powerful AI 预计会在 2026 年实现,足够强大的 AI 也能够将把一个世纪的科研进展压缩到 5-10 年实现(“Compressed 21st Century”),在他和 Lex Fridman 的最新对谈中,Dario 具体解释了自己对于 Powerful AI 可能带来的机会的理解,以及 scaling law、RL、Compute Use 等模型训练和产品的细节进行了分享

改进KV缓存压缩,大模型推理显存瓶颈迎来新突破—— 中科大研究团队提出Ada-KV,通过自适应预算分配算法来优化KV缓存的驱逐过程,以提高推理效率。

Anthropic CEO Dario Amodei 预测,凭借强大的AI的力量,生物学和医学将加速进步,在未来5-10年内实现原本需要50-100年的成果。他称这一现象为“压缩的21世纪”,即AI能够让人类在几年内取得整整一个世纪的生物医学成就。

别说Prompt压缩不重要,你可以不在乎Token成本,但总要考虑内存和LLM响应时间吧?一个显著的问题逐渐浮出水面:随着任务复杂度增加,提示词(Prompt)往往需要变得更长,以容纳更多详细需求、上下文信息和示例。这不仅降低了推理速度,还会增加内存开销,影响用户体验。

大语言模型(LLM)正在推动通信行业向智能化转型,在自动生成网络配置、优化网络管理和预测网络流量等方面展现出巨大潜力。未来,LLM在电信领域的应用将需要克服数据集构建、模型部署和提示工程等挑战,并探索多模态集成、增强机器学习算法和经济高效的模型压缩技术。

人工智能正经历一场由大模型引发的革命。这些拥有数十亿甚至万亿参数的庞然大物,正在重塑我们对 AI 能力的认知,也构筑起充满挑战与机遇的技术迷宫——从计算集群高速互联网络的搭建,到训练过程中模型稳定性和鲁棒性的提升,再到探索更快更优的压缩与加速方法,每一步都是对创新者的考验。