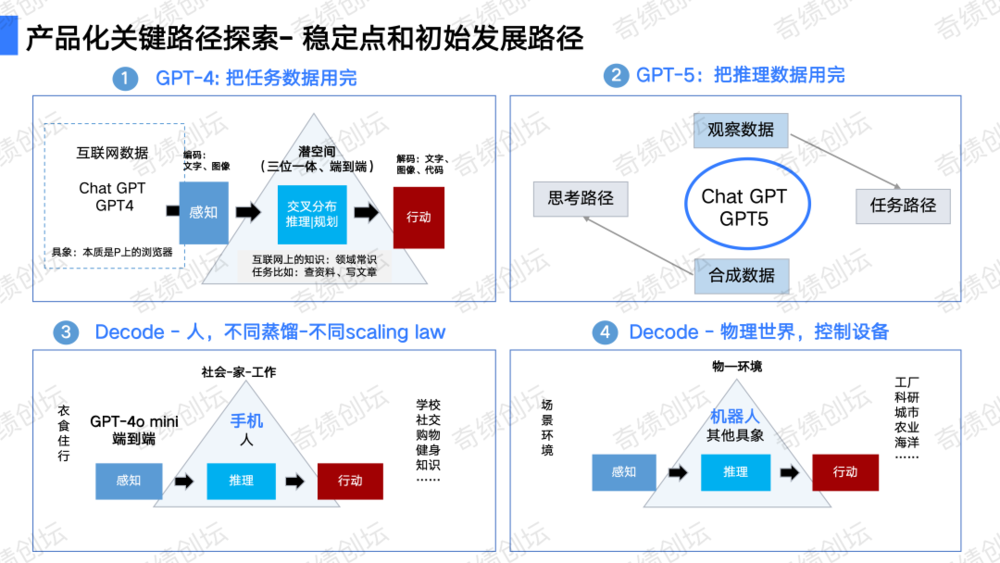
如何设计一个大模型产品?
如何设计一个大模型产品?本文简述了大模型产品化的挑战与策略,特别关注OpenAI的实践,如ChatGPT的用户接受度和GPTs的数据限制。
来自主题: AI资讯
11482 点击 2024-09-02 08:58
 搜索
搜索
本文简述了大模型产品化的挑战与策略,特别关注OpenAI的实践,如ChatGPT的用户接受度和GPTs的数据限制。

该论文作者均来自于华南理工大学马千里教授团队,所在实验室为机器学习与数据挖掘实验室。论文的三位共同第一作者为博士生郑俊豪、硕士生邱圣洁、硕士生施成明,主要研究方向包括大模型和终生学习等,通讯作者为马千里教授(IEEE/ACM TASLP 副主编)。
开学将至,该收心的不止有即将开启新学期的同学,可能还有 AI 大模型。

还能玩纸牌游戏。
可灵影像风,即梦动画风

AI从技术卷向场景。

AI应用贴脸营销,广告平台赚翻了。

长时间交通状况预测,可以用大模型实现了。

大模型竞技场规则更新,GPT-4o mini排名立刻雪崩,跌出前10。

本文第一作者为香港大学博士研究生谢知晖,主要研究兴趣为大模型对齐与强化学习。