
刚刚,Seedance 2.5 正式发布,国产视频模型再次捅破天花板
刚刚,Seedance 2.5 正式发布,国产视频模型再次捅破天花板180 万亿。这是截至今年 6 月,豆包大模型的日均 token 调用量。
来自主题: AI资讯
9852 点击 2026-06-23 16:48
 搜索
搜索
180 万亿。这是截至今年 6 月,豆包大模型的日均 token 调用量。

豆包大模型2.1 Pro正式发布。但字节这次没有像某些厂商那样疯狂堆参数、刷榜单,而是把刀锋对准了一个更硬核的方向:让AI真正能“干活” 。作为本次大会发布的主力模型,豆包2.1 Pro 在 Coding(编程)、Agent(智能体)、VLM(视觉语言模型)三大核心方向实现能力跃升,多项评测表现优于Claude Opus 4.6
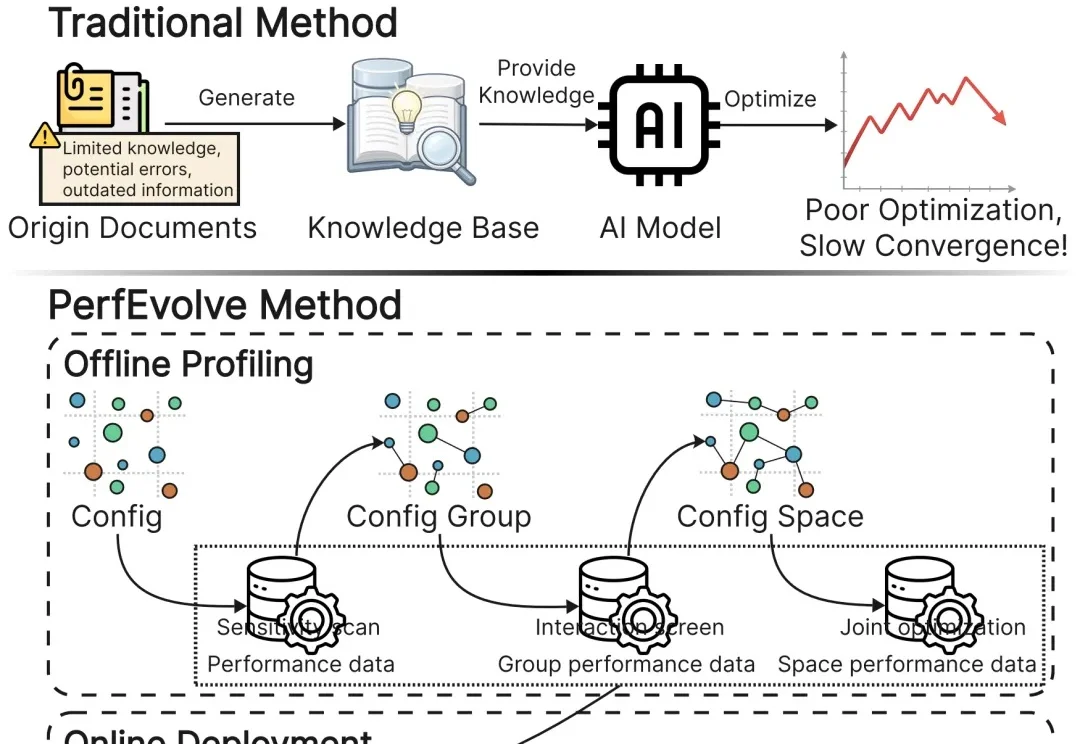
数据库自动调参,一直是大模型Agent的“看似完美、实则翻车”名场面。

好你个微软,当起大模型“倒爷”来了?!
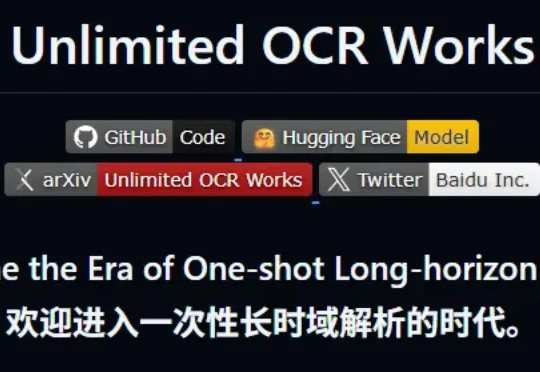
最新开源的Unlimited OCR,总参数3B,实际激活仅500M——放在大模型时代几乎是个零头。但就是这个小到离谱的模型,在OmniDocBench v1.5上拿下93.23%的综合分,v1.6更是达到93.92%,直接刷新了端到端SOTA。

当AI神话被账本照亮,最刺眼的真相终于浮出水面。退潮时刻,狂欢结束。探照灯打过来,谁在裸泳,一目了然。

银河通用团队用史上最大、整整 20 亿帧的动捕数据,训练出了全球首个人形机器人全身实时运控基座大模型,该模型零样本泛化全新动作,成功率从 MLP 架构的 76.89% 跃至 92.58%,推理延迟仅 0.39ms,效果超越英伟达 SONIC,甚至比目前业内主流 TWIST 系统速度提升至五倍。
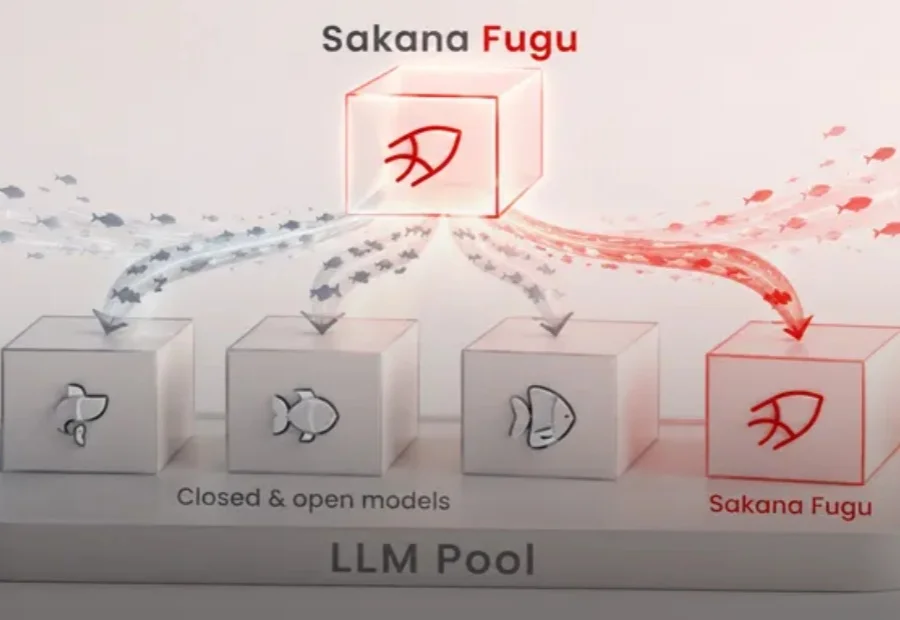
本研究由快手科技语言大模型团队完成,核心作者吕民轩、梅铁桦、杜坦隆等。快手科技与中国科学院大学联合提出 GoLongRL,一套完全开源的长上下文强化学习后训练方案,包含 23K 样本 RLVR 数据集
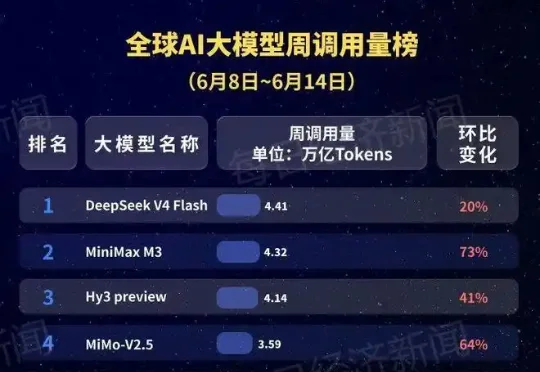
根据OpenRouter最新数据测算,上周(6月8日至14日)全球AI大模型总调用量为44.6万亿Token,较此前一周增长23.5%,连续八周上涨,大模型调用需求仍在持续释放。