
英伟达净利润暴增644%,黄仁勋:会在中国尽力而为
英伟达净利润暴增644%,黄仁勋:会在中国尽力而为英伟达财报显示收入和净利大增,AI芯片市场领先。
来自主题: AI资讯
9760 点击 2024-05-23 10:56
 搜索
搜索
英伟达财报显示收入和净利大增,AI芯片市场领先。

作为世界重要经济体之一的日本,在目前这轮各国竞相参与的AI革命当中几乎是悄无声息。我们基本看不到来自日本的AI模型——不仅是基础大模型,就连应用层的模型也很少。
5 月 22 日,百川智能发布新一代的基座大模型 Baichuan 4,并推出成立之后的首款 AI 应用——百小应。

风靡一时的 AI 音乐创作神器 Suno 有了融资新进展。
当我们从现在往未来看的时候,更容易看到尺度,不太容易看到方向;反之,当我们从未来往回看的时候就更容易看到方向,却不太容易看到尺度。

字节大模型团队,终于曝光! 这不是,字节刚刚启动大模型校招计划,招揽人才嘛—— 计划取名Top Seed,薪资TOP级别、算力数据管够,但仅面向应届博士生;前沿课题覆盖大模型、图像&视频生成、机器学习算法和系统以及音频生成和理解等方向。 另外还有一帮顶尖的技术导师团带队……等等,这不就是字节豆包大模型的背后团队吗?
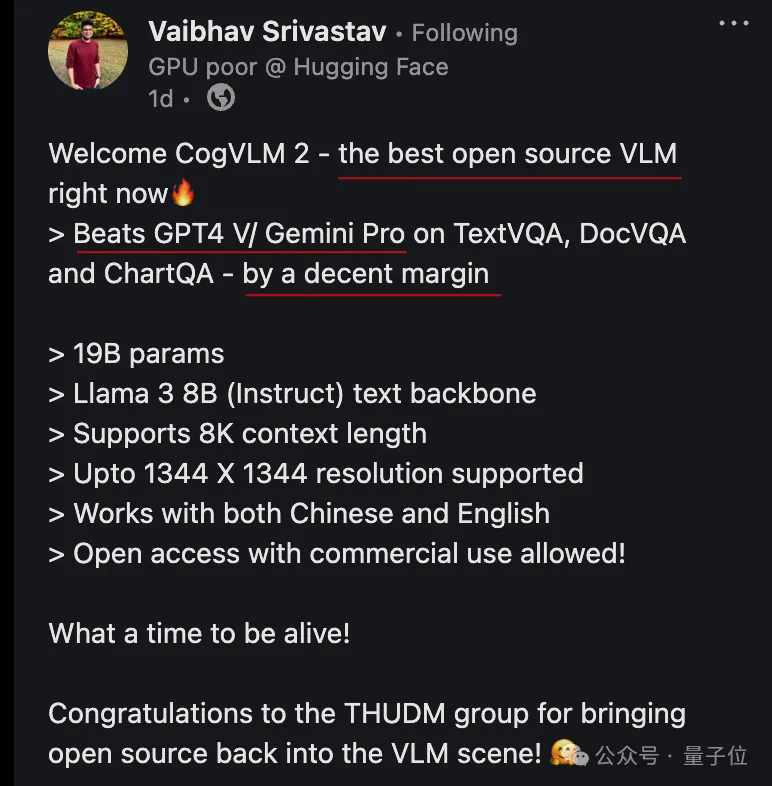
开源多模态SOTA模型再易主!Hugging Face开发者大使刚刚把王冠交给了CogVLM2,来自大模型创业公司智谱AI。CogVLM2甚至在3项基准测试上超过GPT-4v和Gemini Pro,还不是超过一点,是大幅领先。
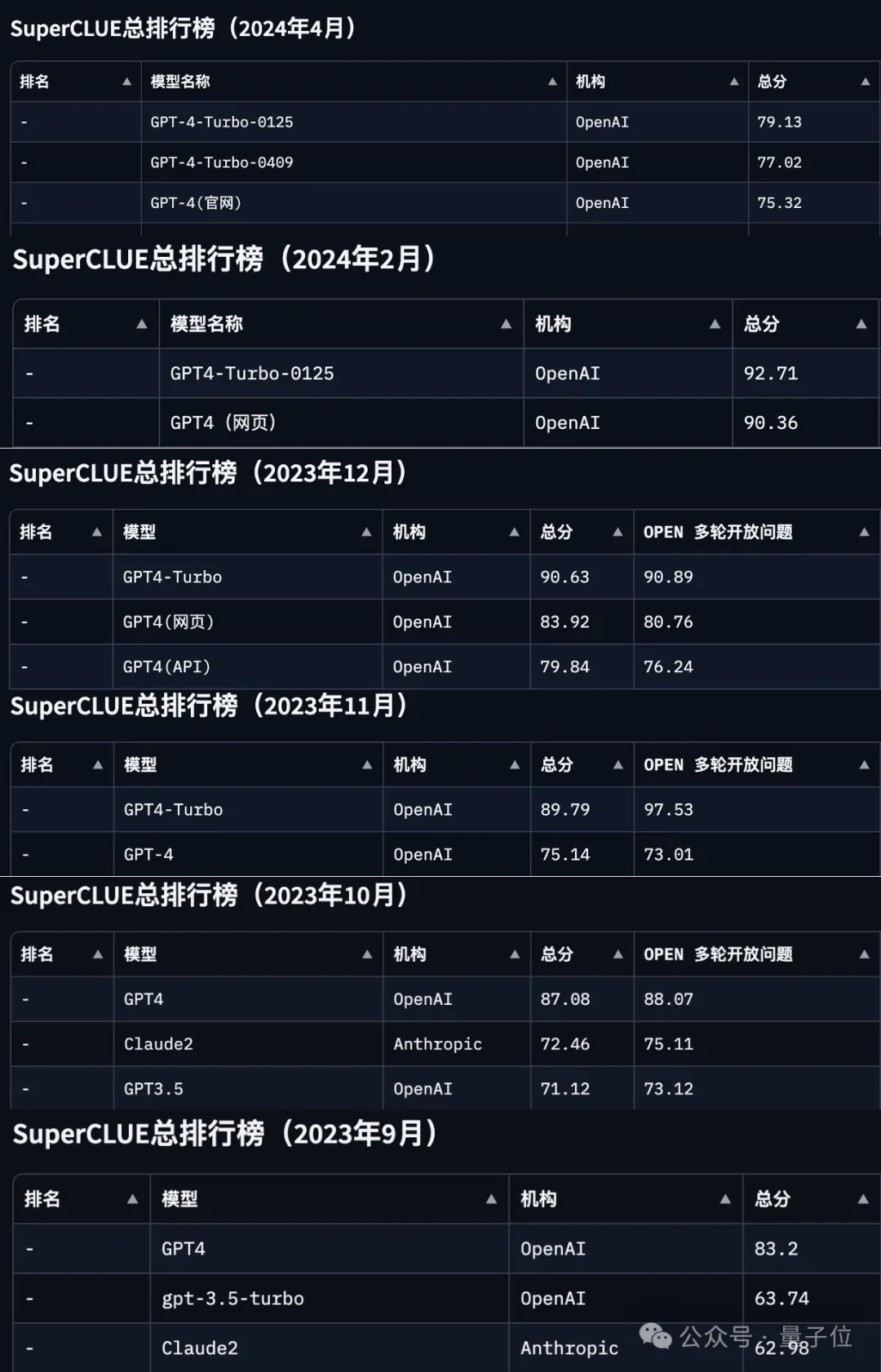
OpenAI长期霸榜的SuperCLUE(中文大模型测评基准),终于被国产大模型反将一军。

从互联网背景突进AI领域的拓荒者会很像要穿越白垩纪流星撞地球的分割点。

字节豆包低价首秀,让互联网大厂纷纷掀翻大模型地板价。