
首个统一多模态模型评测标准,DeepSeek Janus理解能力领跑开源,但和闭源还有差距
首个统一多模态模型评测标准,DeepSeek Janus理解能力领跑开源,但和闭源还有差距统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。
来自主题: AI技术研报
9250 点击 2025-04-10 10:20
 搜索
搜索
统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。

基于锐炫™ A770显卡的大模型一体机,在性价比上真的是太香了。它非常适合30-50人规模的团队来使用。一个“性价比”关键词,道破了为什么大模型一体机里面会出现英特尔游戏卡。

互联网时代属于产品经理的高光,还没有在AI时代复现。
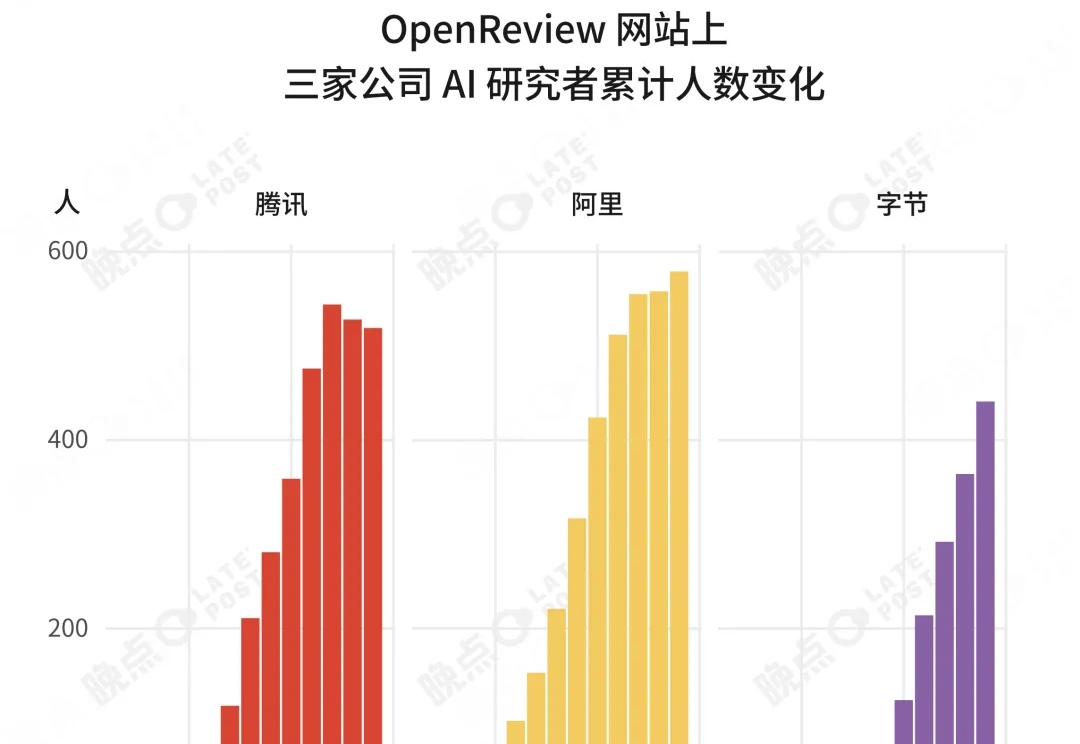
面对大模型,三家大厂有相同的目标,选了不同的路径。

截至2025年3月,全国算法备案数量已达3234个,大模型备案数量为407个,覆盖金融、医疗、教育等多个领域。为规范技术应用并鼓励企业合规发展,全国各省市纷纷出台大模型算法备案奖励补贴政策,最高补贴金额达5000万元。

刚刚,一位AI公司CEO细细扒皮了关于Llama 4的五大疑点。甚至有圈内人表示,Llama 4证明Scaling已经结束了,LLM并不能可靠推理。但更可怕的事,就是全球的AI进步恐将彻底停滞。

多点发力,协同并进,才能让AI的成长有更多道路可走
Llama 4真要被锤爆了,这次是大模型竞技场(Chatbot Arena)官方亲自下场开怼:
大家翘首以盼的 Llama 4,用起来为什么那么拉跨?
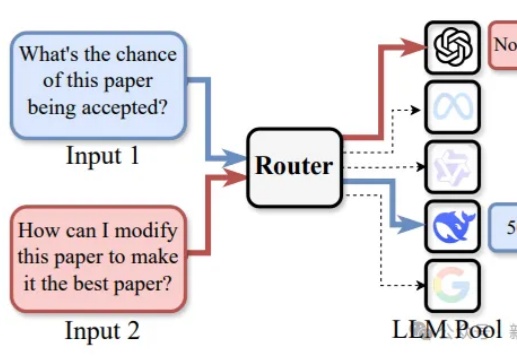
路由LLM是指一种通过router动态分配请求到若干候选LLM的机制。论文提出且开源了针对router设计的全面RouterEval基准,通过整合8500+个LLM在12个主流Benchmark上的2亿条性能记录。将大模型路由问题转化为标准的分类任务,使研究者可在单卡甚至笔记本电脑上开展前沿研究。