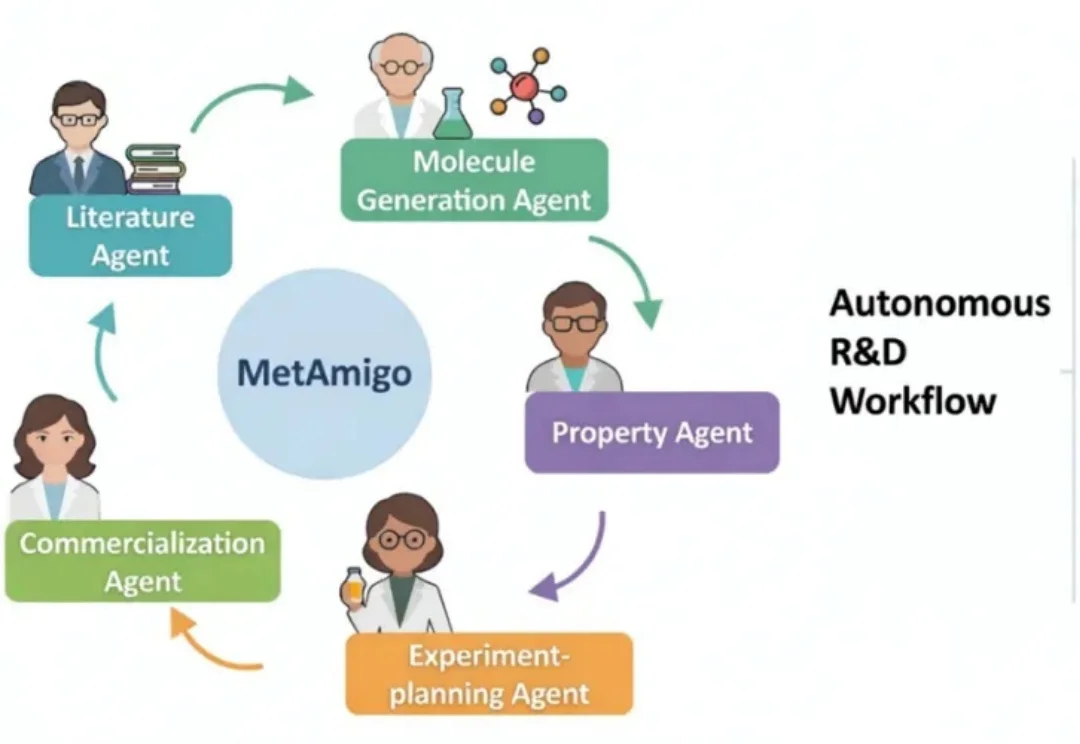
首个千万美金ARR的AI4S公司,完成AI设计新分子商业应用
首个千万美金ARR的AI4S公司,完成AI设计新分子商业应用2026 年伊始,AI 的进化逻辑正从「单一工具赋能」转向「场景深度共生」,当大模型在各领域持续突破,前沿科研与新材料研发领域,正迎来一场由 Agentic AI 驱动的效率革命。
来自主题: AI资讯
7011 点击 2026-03-11 16:58
 搜索
搜索
2026 年伊始,AI 的进化逻辑正从「单一工具赋能」转向「场景深度共生」,当大模型在各领域持续突破,前沿科研与新材料研发领域,正迎来一场由 Agentic AI 驱动的效率革命。

当前,大语言模型(LLMs)和视觉语言模型(VLMs)在语义领域的成功未能直接迁移至物理机器人,归根结底在于其互联网原生的基因。
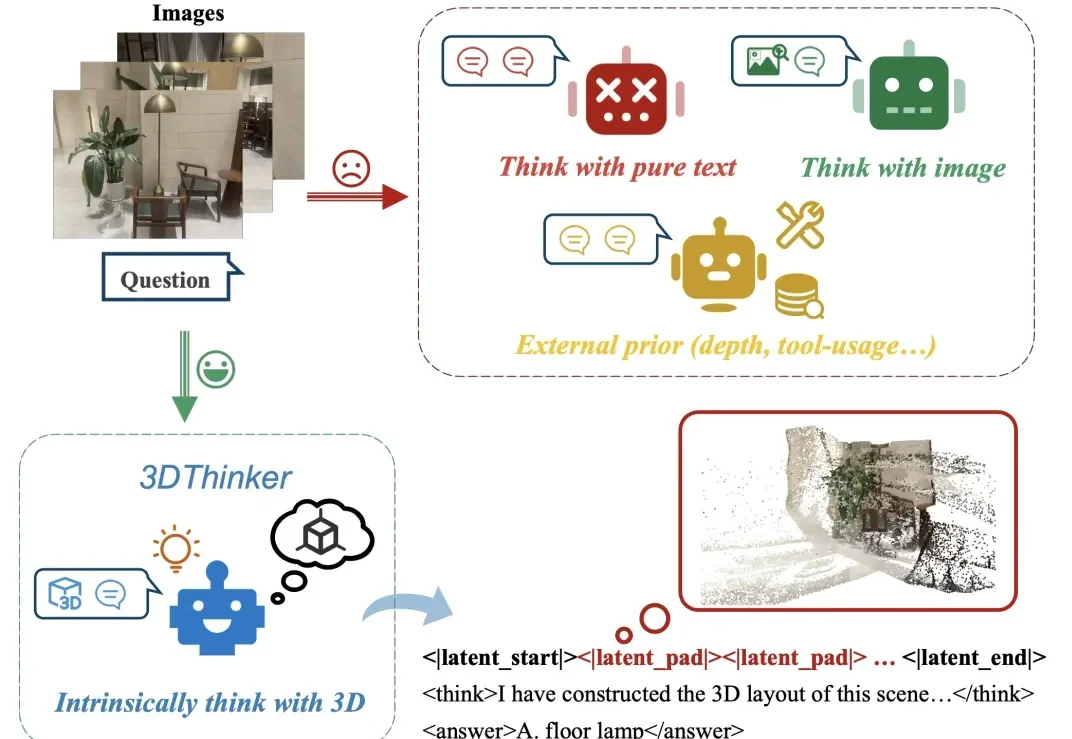
大家是否有这样的感觉?给定几张场景中拍摄的图片,往往能够在脑海中想象出这个场景的三维布局,然而当前的多模态大模型还停留于纯文本或者 2D 视觉的推理表示,限制了图像中隐含几何结构的表达能力。
如果你在过去一年关注过大模型训练的技术,大概率听过 Muon 这个名字 —— 这个在月之暗面 K2 模型的相关讨论中走红的优化器,被视为是可能挑战 Adam 的新秀。它的思路很直接:对动量矩阵进行正交化,让各个奇异方向上的更新速率一致,提升训练效率。
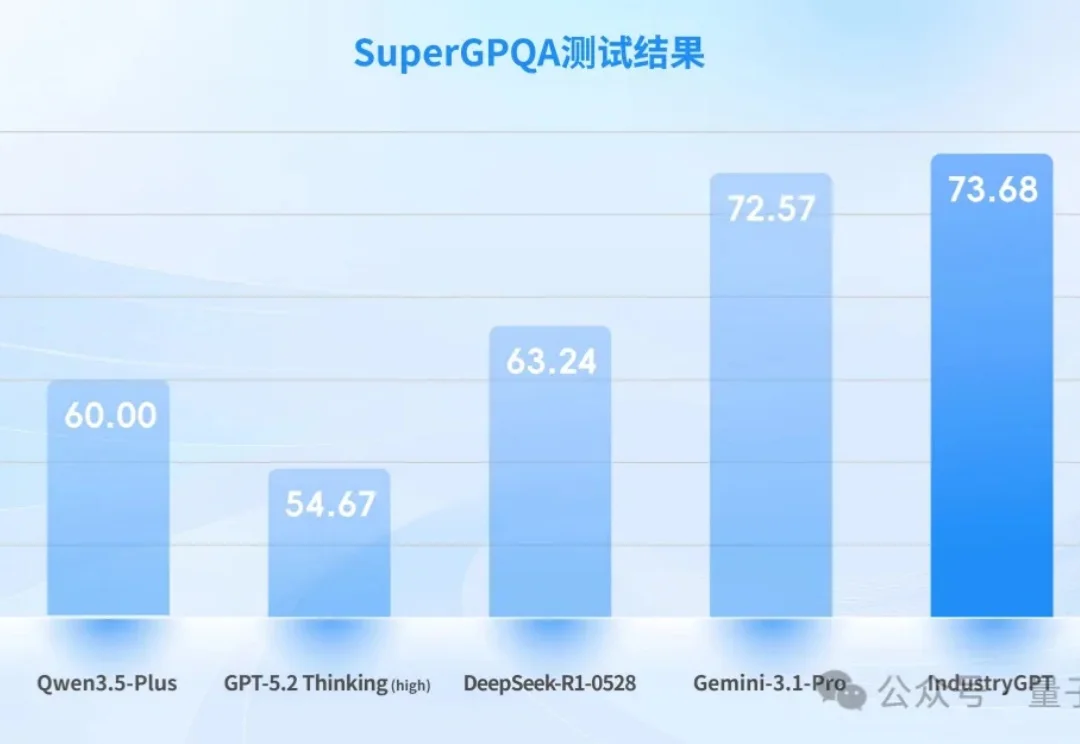
最近,一批顶级通用大模型参加了三场特殊的“工业执业考试”。
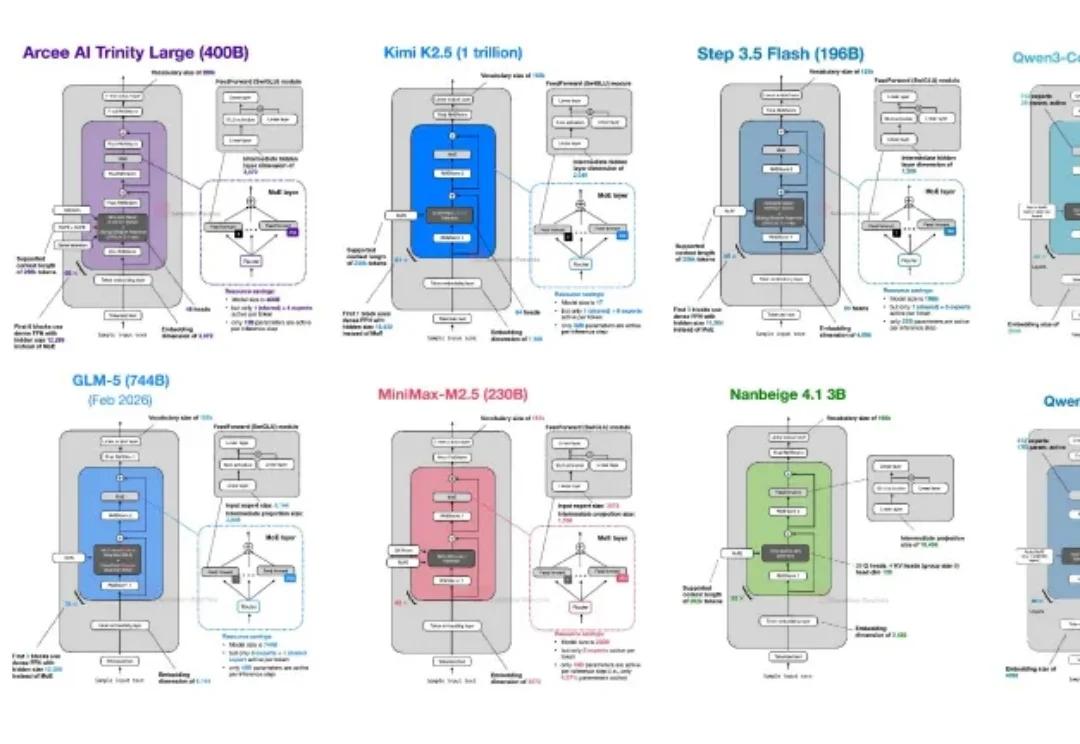
这两年,大模型大厂之间堪比军备竞赛。不论开源还是闭源阵营,为了在指标上领先对手,都在疯狂地卷 Scaling Law,卷算力,卷参数量,已经达到了近乎离谱的程度。

OpenAI的最新研究揭示了一个反直觉的真相:越强大的推理模型,越管不住自己的「脑子」。在CoT-Control套件测试的13款前沿模型中,DeepSeek R1控制自身思维链的成功率仅为0.1%,Claude Sonnet 4.5也只有2.7%。
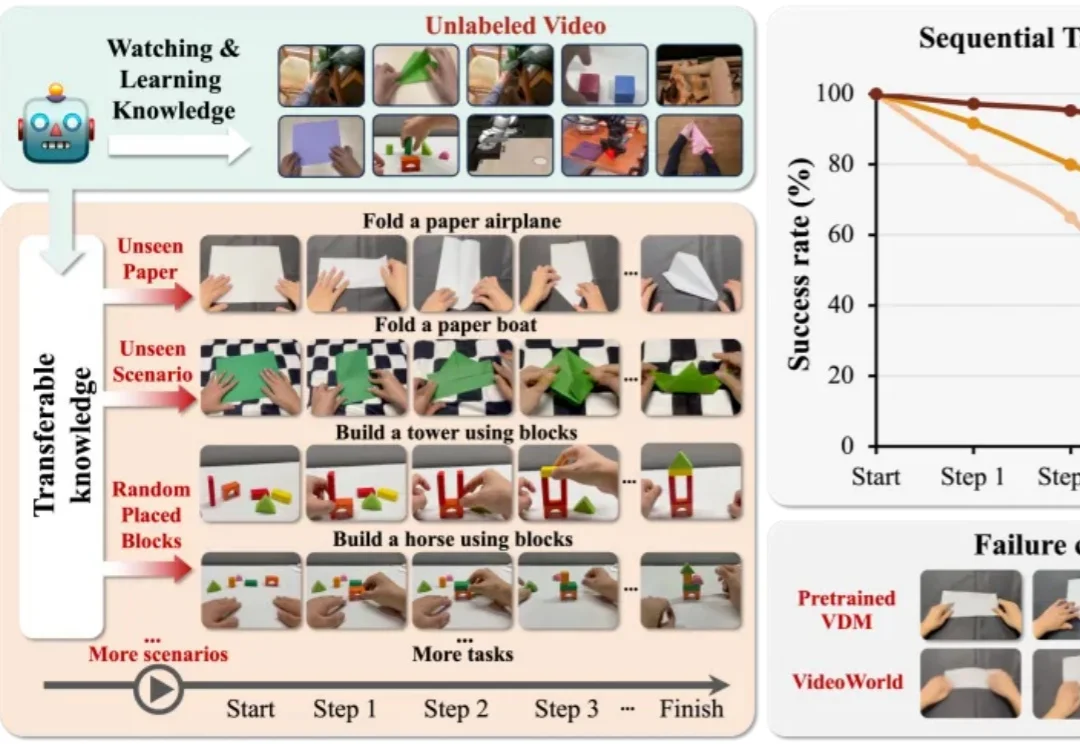
视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。
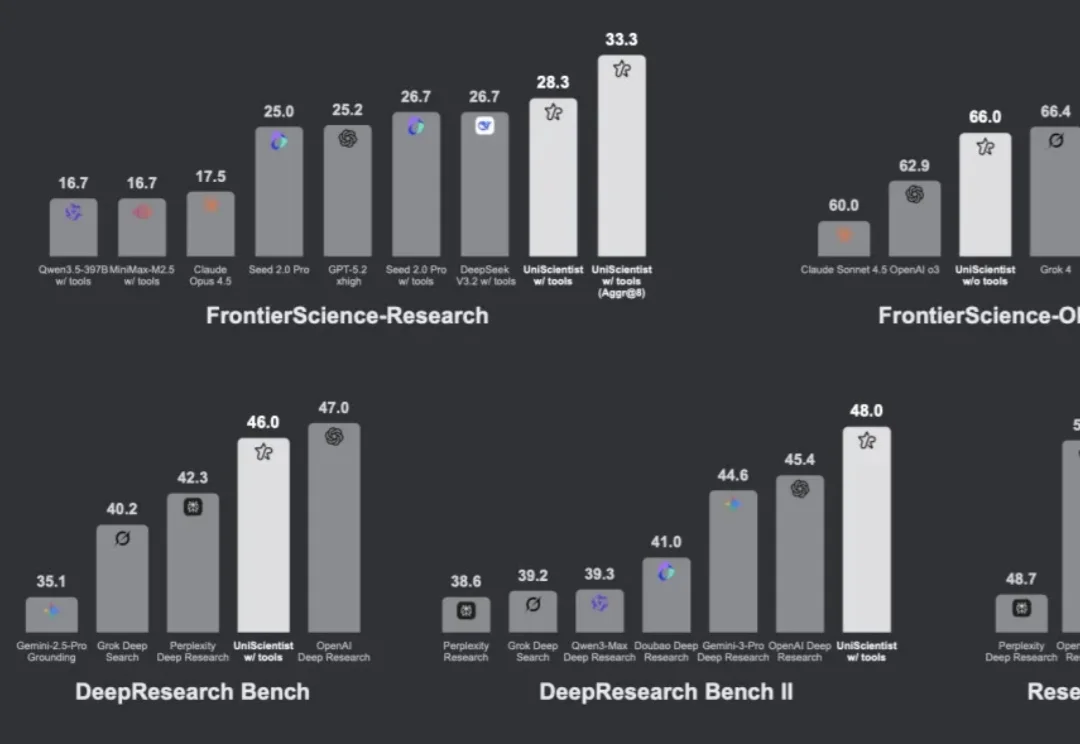
多数大模型能生成 “看起来像” 研究的文本,但极少数能真正做研究 —— 提出假设、收集证据、执行可复现的推导、迭代验证直至结论成立。

你现在养了几只龙虾?