
做AI产品两年,我得出的实操经验
做AI产品两年,我得出的实操经验前段时间我去 QCon 北京全球软件大会分享了一个专题:AI 时代的新范式:如何构建 AI 产品?观众反响特别好,想着要不把分享的内容公开出来,所以整理了这篇文章。本篇内容是对我过去两年时间,做了无数个 AI 产品 demo 的一个阶段性的总结,主要聚焦这三个方面的经验
来自主题: AI资讯
10740 点击 2025-04-15 15:39
 搜索
搜索
前段时间我去 QCon 北京全球软件大会分享了一个专题:AI 时代的新范式:如何构建 AI 产品?观众反响特别好,想着要不把分享的内容公开出来,所以整理了这篇文章。本篇内容是对我过去两年时间,做了无数个 AI 产品 demo 的一个阶段性的总结,主要聚焦这三个方面的经验
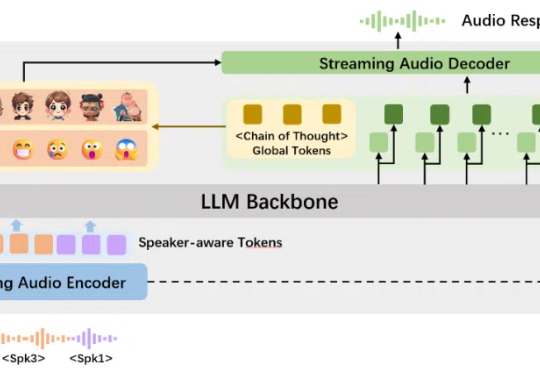
智能语音交互领域,学术研究也能如此酷炫。全球首个纯学术界自研的支持多人实时口语对话的语音情感大模型 ——“交交”,正式推出!

开源语音模型Orpheus让LLM涌现出人类情感!在A100 40GB显卡上,30亿参数模型的流式推理速度甚至超过了音频播放速度。甚至可以zero-shot克隆声音。

Google Classroom 推出了一项新的人工智能驱动功能,旨在帮助教师生成测验题目的 AI 功能。该工具于周一上线,允许教育工作者基于特定文本输入创建一系列问题。
我们中的许多人已经在 Product Hunt 上发布了一段时间,越来越多的人开始质疑那里的受众是否真实,toB的产品是否仍然值得在他们的平台上发布。
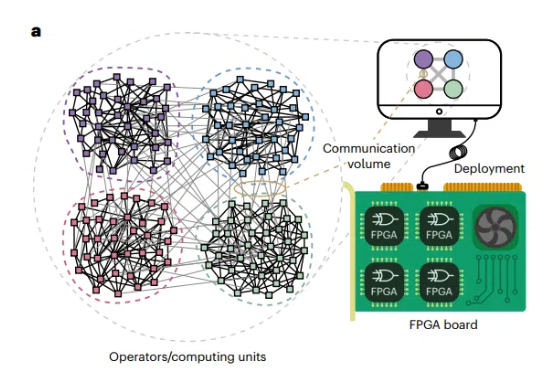
组合优化问题(COPs)在科学和工业领域无处不在,从物流调度到芯片设计,从社交网络分析到人工智能算法,其高效求解一直是研究热点。
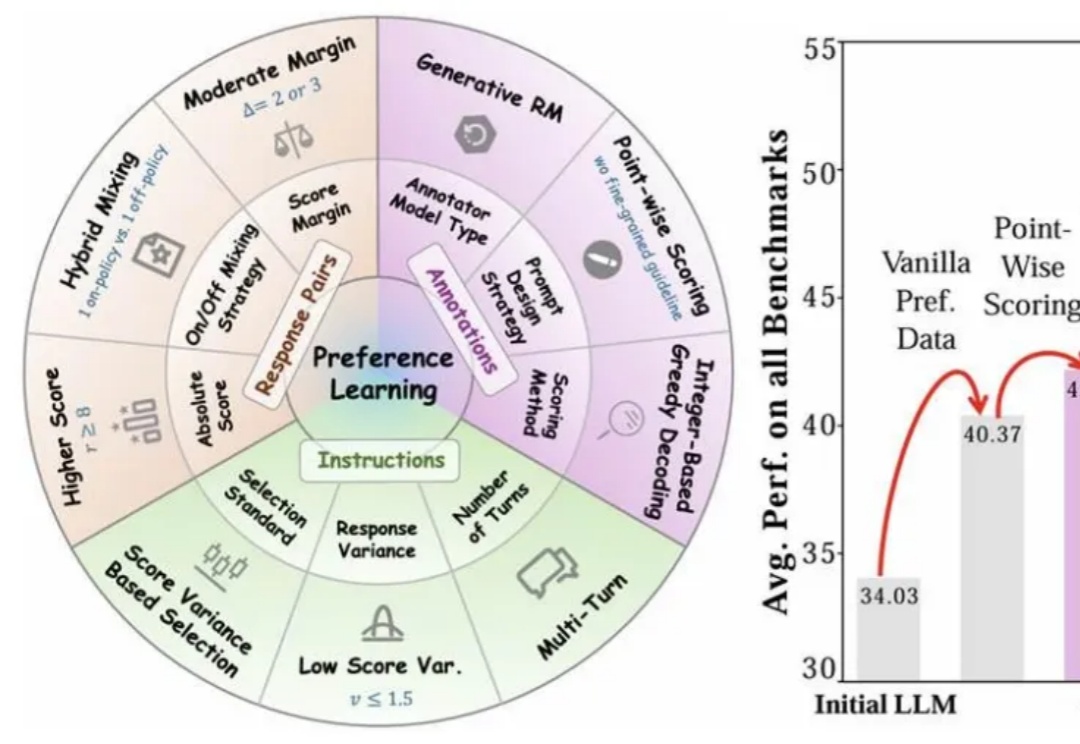
近年来,大语言模型(LLMs)的对齐研究成为人工智能领域的核心挑战之一,而偏好数据集的质量直接决定了对齐的效果。无论是通过人类反馈的强化学习(RLHF),还是基于「RL-Free」的各类直接偏好优化方法(例如 DPO),都离不开高质量偏好数据集的构建。
一切为了「多终端一致体验」和「用户数据闭环」。

谁说世界不需要文科生?
当下技术的水平还不足以支撑AI直接生成游戏,一步一个脚印才是正道。