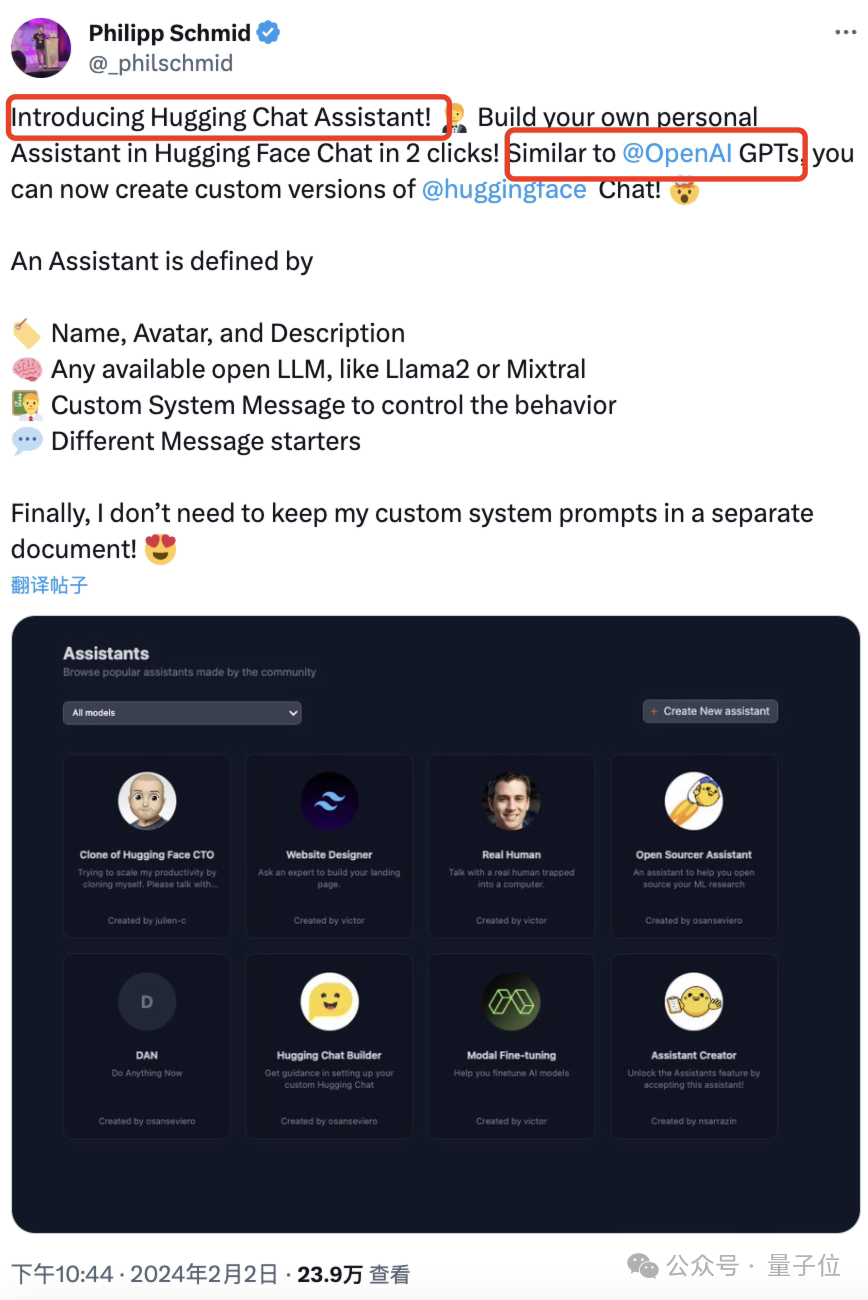
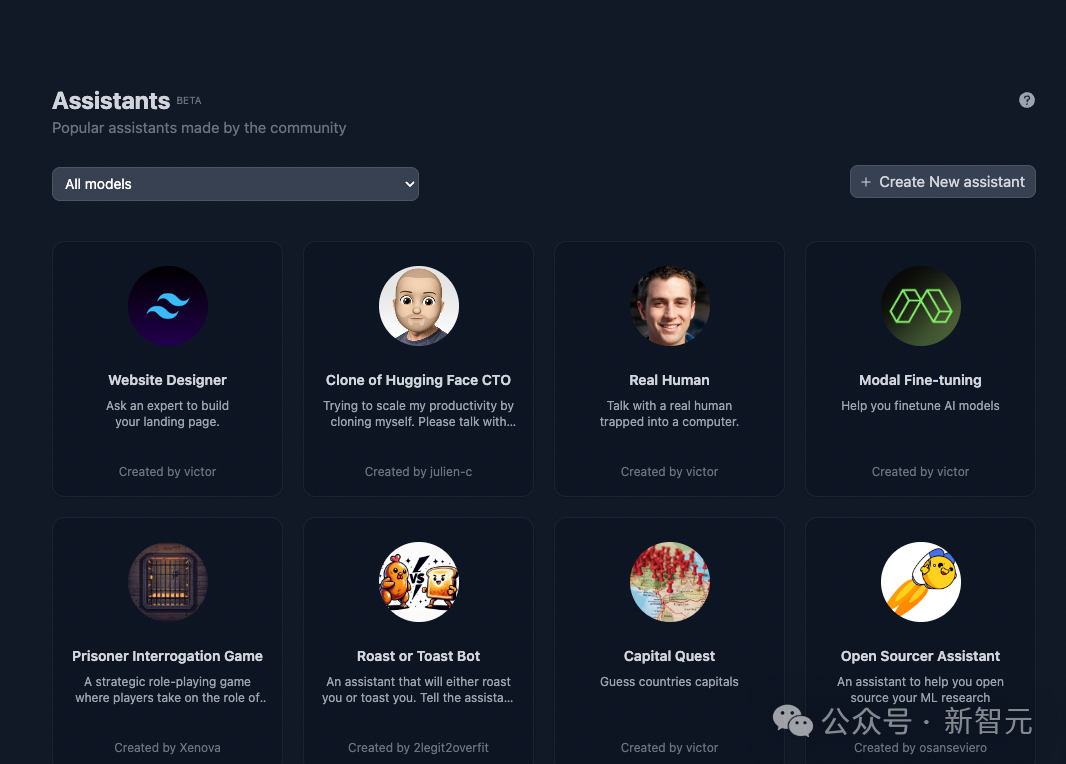
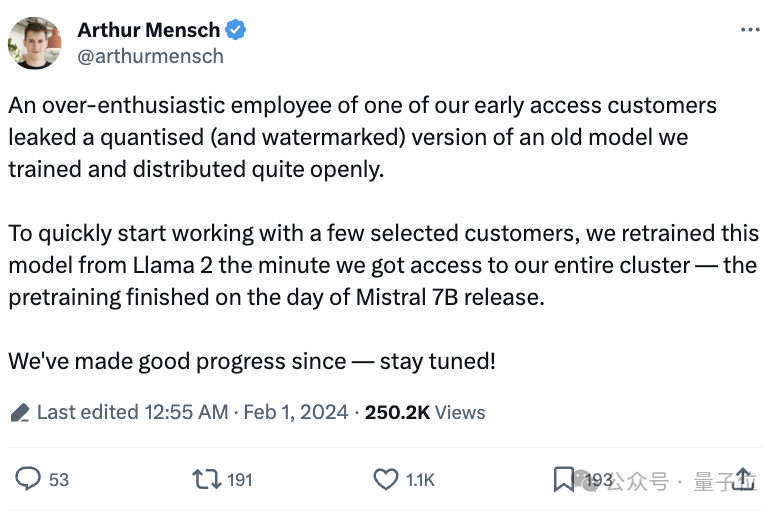
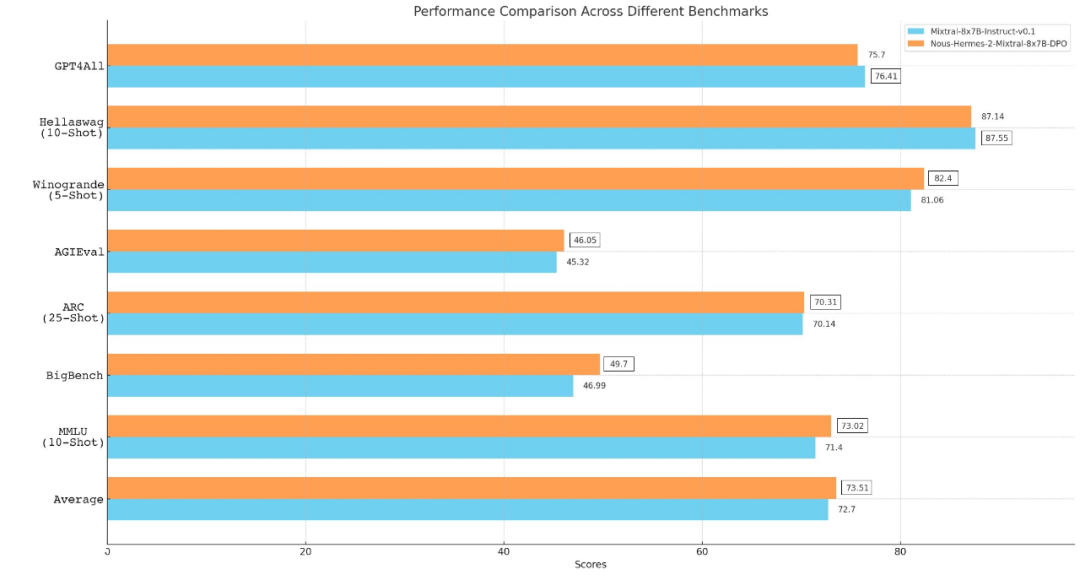
金融研报数据魔改Yi-34B & DeepSeek 67B 谁更强? Deepmoney金融大模型魔改方案分享&在线实测
金融研报数据魔改Yi-34B & DeepSeek 67B 谁更强? Deepmoney金融大模型魔改方案分享&在线实测在微调大型模型的过程中,一个常用的策略是“知识蒸馏”,这意味着借助高性能模型,如GPT-4,来优化性能较低的开源模型。这种方法背后隐含的哲学理念与logos中心论相似,把GPT-4等模型视为更接近唯一的逻辑或真理的存在。
来自主题: AI资讯
9390 点击 2024-02-21 16:49