![[重磅-万字长文]千亿美金市值美国AI政企服务巨头Palantir产品及商业化全面解析](https://www.aitntnews.com/pictures/2024/11/4/a06de2f8-9a52-11ef-b76d-fa163e4b35c9.gif)
[重磅-万字长文]千亿美金市值美国AI政企服务巨头Palantir产品及商业化全面解析
[重磅-万字长文]千亿美金市值美国AI政企服务巨头Palantir产品及商业化全面解析本文介绍了千亿美金市值,美国服务政企的AI高科技企业Palantir公司及其核心软件平台Gotham和Foundry,以及新产品大模型人工智能平台AIP和Apollo,它们旨在帮助政府和商业组织解决复杂问题,并利用数据做出更有效的决策。
来自主题: AI资讯
9244 点击 2024-11-04 10:37
 搜索
搜索
本文介绍了千亿美金市值,美国服务政企的AI高科技企业Palantir公司及其核心软件平台Gotham和Foundry,以及新产品大模型人工智能平台AIP和Apollo,它们旨在帮助政府和商业组织解决复杂问题,并利用数据做出更有效的决策。

MPDS(Movie Posters Dataset)是一个创新的电影海报数据集,旨在解决现有图像生成模型在制作电影海报时面临的挑战。
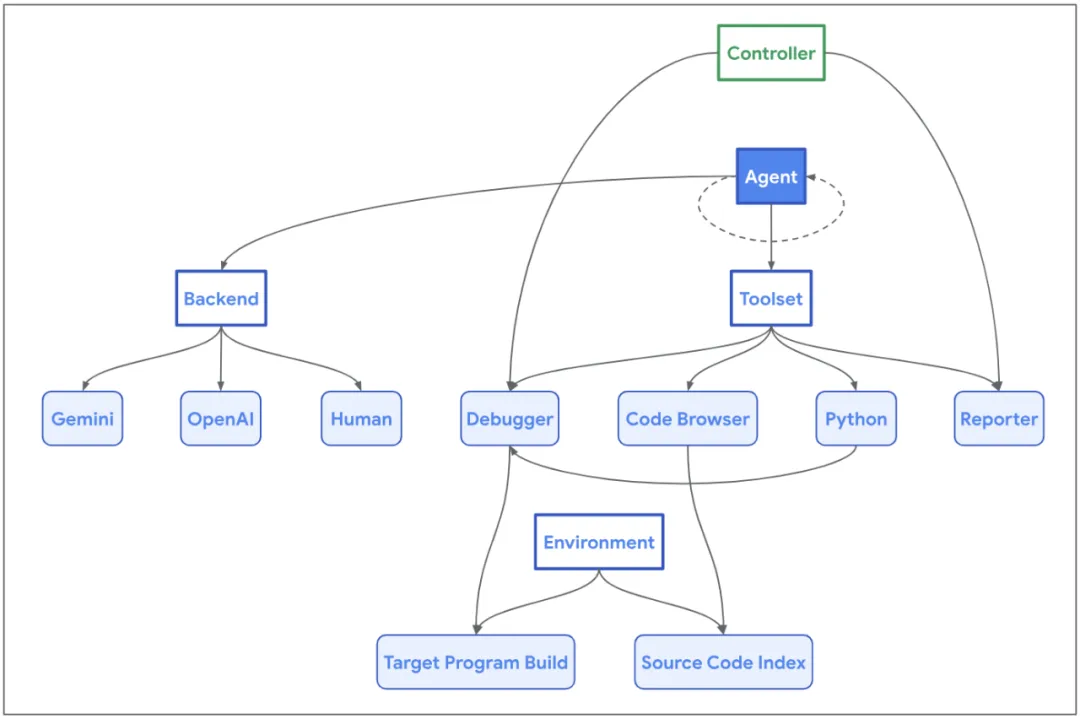
开源数据库引擎 SQLite 有 bug,还是智能体检测出来的!

多图像场景也能用DPO方法来对齐了! 由上海交大、上海AI实验室、港中文等带来最新成果MIA-DPO。 这是一个面向大型视觉语言模型的多图像增强的偏好对齐方法。
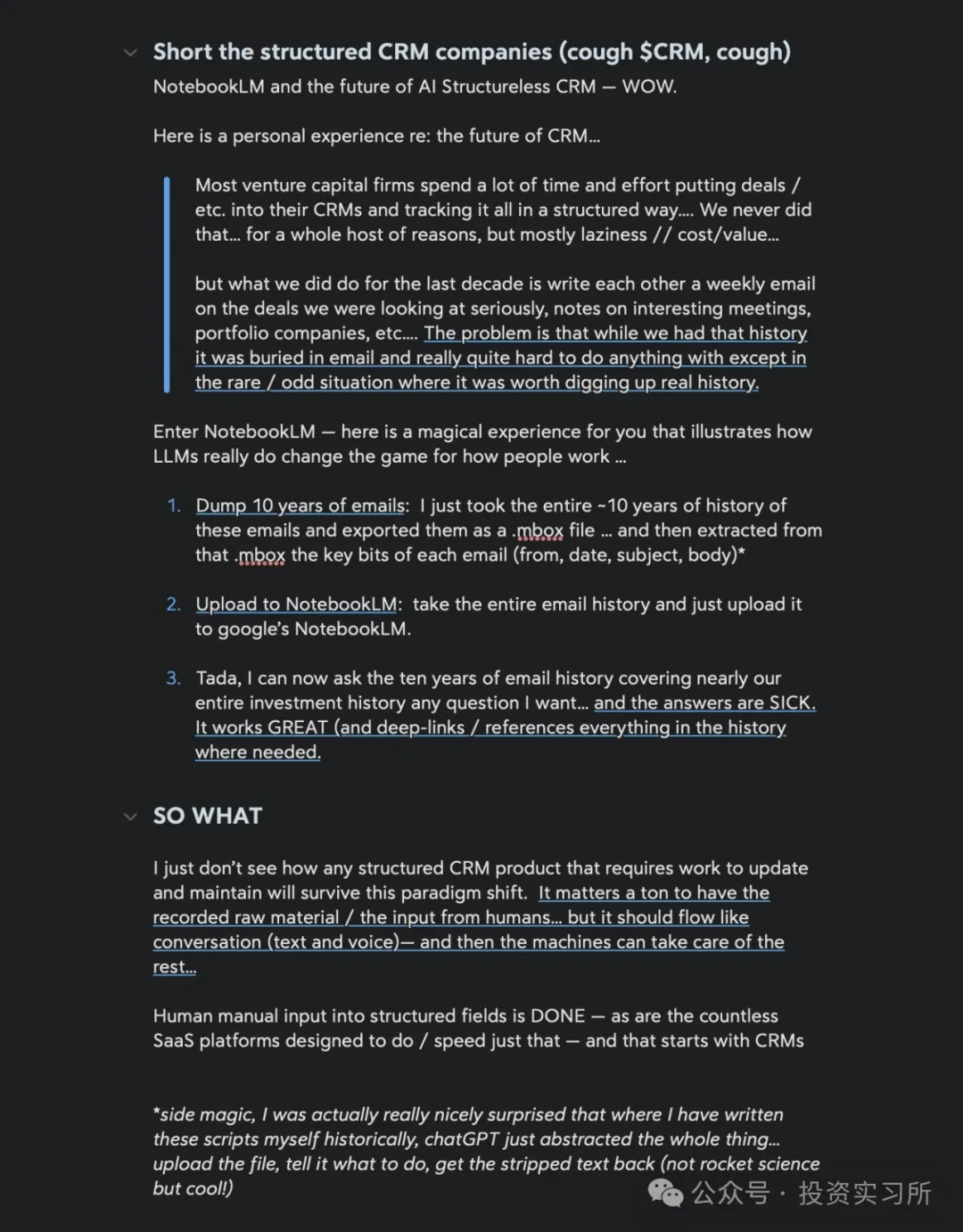
今天 ChatGPT 的搜索功能发布了,或许是已经用 Perplexity 比较习惯,此次 ChatGPT 的搜索就没太多惊艳感了,所以我体验了一下感觉效果一般般,看看后续多用用会不会有更多不一定的体验。

大模型热,企业落地难?就在刚刚,百川智能推出「1+3」产品矩阵,一站式解决大模型商业化难题。「系列优质通用数据+领域增强训练工具链」,仅需10分钟就能让企业自主成为模型定制增强专家,实现行业最佳的多场景可用率。

对于人类而言,一旦掌握了 “打开瓶盖” 的动作,面对 “拧紧螺丝” 这样的任务通常也能游刃有余,因为这两者依赖于相似的手部动作。然而,对于机器人来说,即使是这样看似简单的任务转换依然充满挑战。例如,换成另一种类型的瓶盖,机器人可能无法成功打开。这表明,目前的机器人方法尚未充分让模型学习到任务的内在执行逻辑,而只是单纯的依赖于数据拟合。

已与多家国内外头部主机厂、Tier1供应商、具身智能公司签约

近年来,大语言模型(Large Language Models, LLMs)的研究取得了重大进展,并对各个领域产生了深远影响。然而,LLMs的卓越性能来源于海量数据的大规模训练,这导致LLMs的训练成本明显高于传统模型。

自去年底以来,时序预测领域正在经历重大转型,从传统的「单一数据集训练单一模型」的模式逐步转向「通用预测基础模型」。