
8年估值千亿,华裔天才干出传奇AI独角兽,年入7亿美元,下一步IPO
8年估值千亿,华裔天才干出传奇AI独角兽,年入7亿美元,下一步IPO智东西5月22日消息,昨晚,95后华裔天才Alexander Wang宣布,其创办的美国AI数据标注创企Scale AI获得10亿美元F轮融资,估值翻倍至138亿美元(折合约999亿人民币)。
来自主题: AI资讯
11733 点击 2024-05-23 10:04
 搜索
搜索
智东西5月22日消息,昨晚,95后华裔天才Alexander Wang宣布,其创办的美国AI数据标注创企Scale AI获得10亿美元F轮融资,估值翻倍至138亿美元(折合约999亿人民币)。

字节大模型团队,终于曝光! 这不是,字节刚刚启动大模型校招计划,招揽人才嘛—— 计划取名Top Seed,薪资TOP级别、算力数据管够,但仅面向应届博士生;前沿课题覆盖大模型、图像&视频生成、机器学习算法和系统以及音频生成和理解等方向。 另外还有一帮顶尖的技术导师团带队……等等,这不就是字节豆包大模型的背后团队吗?
近年来,「scaling」是计算机视觉研究的主角之一。随着模型尺寸和训练数据规模的增大、学习算法的进步以及正则化和数据增强等技术的广泛应用,通过大规模训练得到的视觉基础网络(如 ImageNet1K/22K 上训得的 Vision Transformer、MAE、DINOv2 等)已在视觉识别、目标检测、语义分割等诸多重要视觉任务上取得了令人惊艳的性能。

近日,西交微软北大联合提出信息密集型训练大法,使用纯数据驱动的方式,矫正LLM训练过程产生的偏见,在一定程度上治疗了大语言模型丢失中间信息的问题。

近日,又一惊人结论登上Hacker News热榜:没有指数级数据,就没有Zero-shot!多模态模型被扒实际上没有什么泛化能力,生成式AI的未来面临严峻挑战。
A16z(Andreessen Horowitz)可能是最会做内容的投资公司。他们在官网上发表的很多 AI 时代的创业思考和观察,都是很值得阅读的好文章。
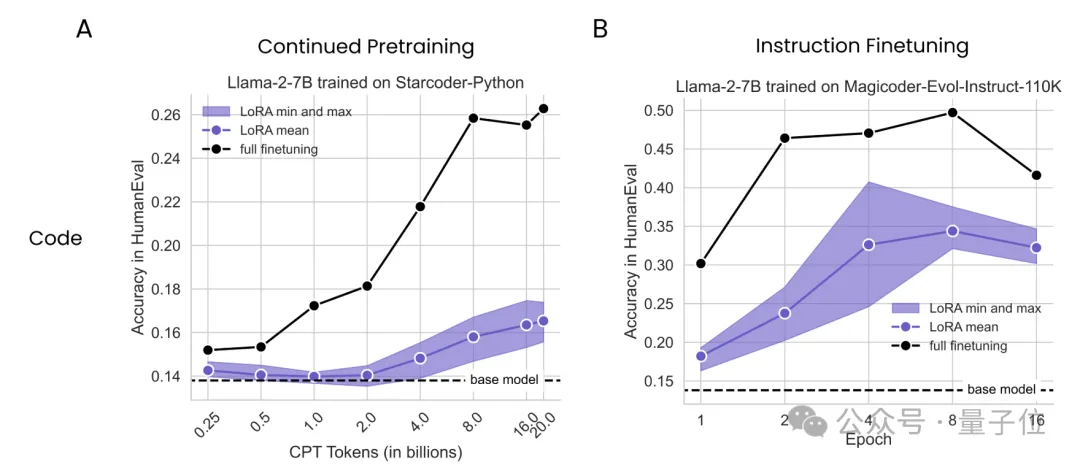
大数据巨头Databricks与哥伦比亚大学最新研究发现,在数学和编程任务上,LoRA干不过全量微调。

当计算预算低时,重复使用高质量数据更好;当不差钱时,使用大量数据更有利。

为了能让自己以后更好地摸鱼,我上周第一次和大模型协作,完成了对一份财报的分析。

最公平的大模型基准测试诞生了!来自LLM竞技场,最接近人类偏好,数据新鲜、速度快、成本低,严格分离学渣和学霸。