AAAI 2026 Oral|快手提出全新「检索数据引擎」CroPS,打破搜索信息茧房
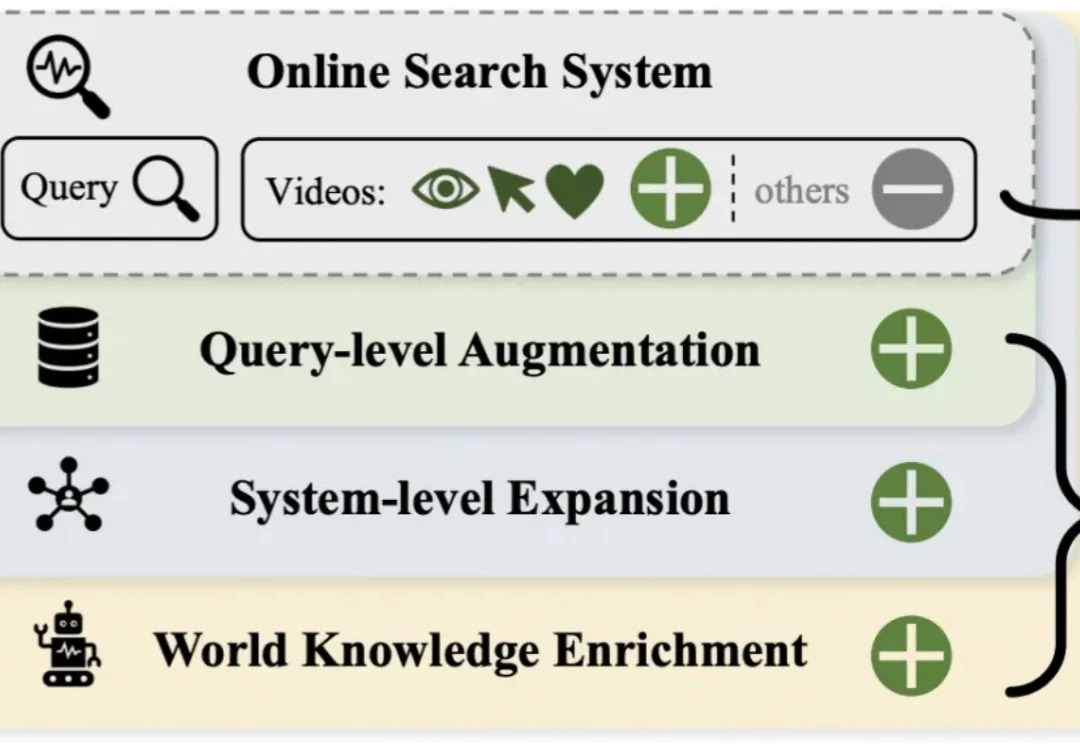
AAAI 2026 Oral|快手提出全新「检索数据引擎」CroPS,打破搜索信息茧房短视频搜索业务是向量检索在工业界最核心的应用场景之一。然而,当前业界普遍采用的「自强化」训练范式过度依赖历史点击数据,导致系统陷入信息茧房,难以召回潜在相关的新鲜内容。
来自主题: AI技术研报
6297 点击 2026-01-12 14:08
 搜索
搜索
短视频搜索业务是向量检索在工业界最核心的应用场景之一。然而,当前业界普遍采用的「自强化」训练范式过度依赖历史点击数据,导致系统陷入信息茧房,难以召回潜在相关的新鲜内容。

谷歌 Gemini 数据联合负责人 Andrew Dai 联手苹果首席研究科学家 Yinfei Yang,隐身创办 AI 新秀 Elorian。首轮将融资 5000 万美元,剑指「视觉推理」这个下一代大模型的核心问题。

Deepmind推出的SIMA 2,让智能体能在虚拟环境(商业游戏)中,边聊天边进行复杂的多模态推理。作为具身通用智能的原型,SIMA 2已从静态数据集迈向无限程序化生成的训练场。

《Nature Medicine》 的研究报道“A multimodal sleep foundation model for disease prediction”,研究人员开发了一种名为 SleepFM 的基础模型,从超过58万小时的记录中“学会”了睡眠的语言。这不仅是睡眠科学的进步,更是AI在生物医学领域的深层突围。

独家获悉,AI DataAgent公司 ChatExcel 近期已完成 Pre-A 轮与 A 轮两轮累计数千万元融资,投资方为考拉基金与合鼎共资本。在此之前,该公司曾获得上海常垒资本、武汉东湖天使基金的投资。

几天前,DeepSeek 毫无预兆地更新了 R1 论文,将原有的 22 页增加到了现在的 86 页。新版本充实了更多细节内容,包括首次公开训练全路径,即从冷启动、训练导向 RL、拒绝采样与再微调到全场景对齐 RL 的四阶段 pipeline,以及「Aha Moment」的数据化验证等等。

CaveAgent的核心思想很简单:与其让LLM费力地去“读”数据的文本快照,不如给它一个如果不手动重启、变量就永远“活着”的 Jupyter Kernel。这项由香港科技大学(HKUST)领衔的研究,为我们展示了一种“Code as Action, State as Memory”的全新可能性。它解决了所有开发过复杂Agent的工程师最头疼的多轮对话中的“失忆”与“漂移”问题。

“我们只交付100%可以复现的轨迹。”

“99%的企业级 Agent 都只是玩具!”
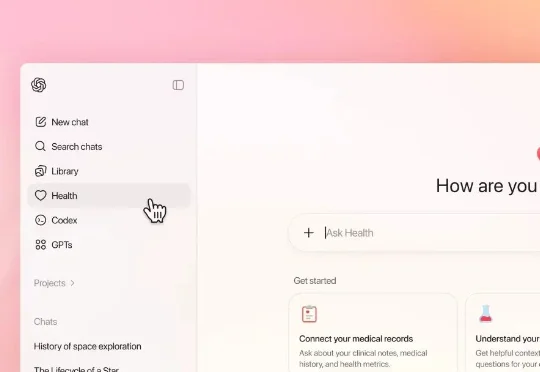
新的一年,OpenAI 决定认真入局 AI 医疗健康领域了。就在刚刚,OpenAI 重磅推出了 ChatGPT 健康(ChatGPT Health),能够把你的医疗记录、健康 App、甚至是 Apple 健康数据连接起来,然后用 AI 帮你看懂那些复杂到头大的体检报告、准备就医问题清单、甚至规划饮食运动。