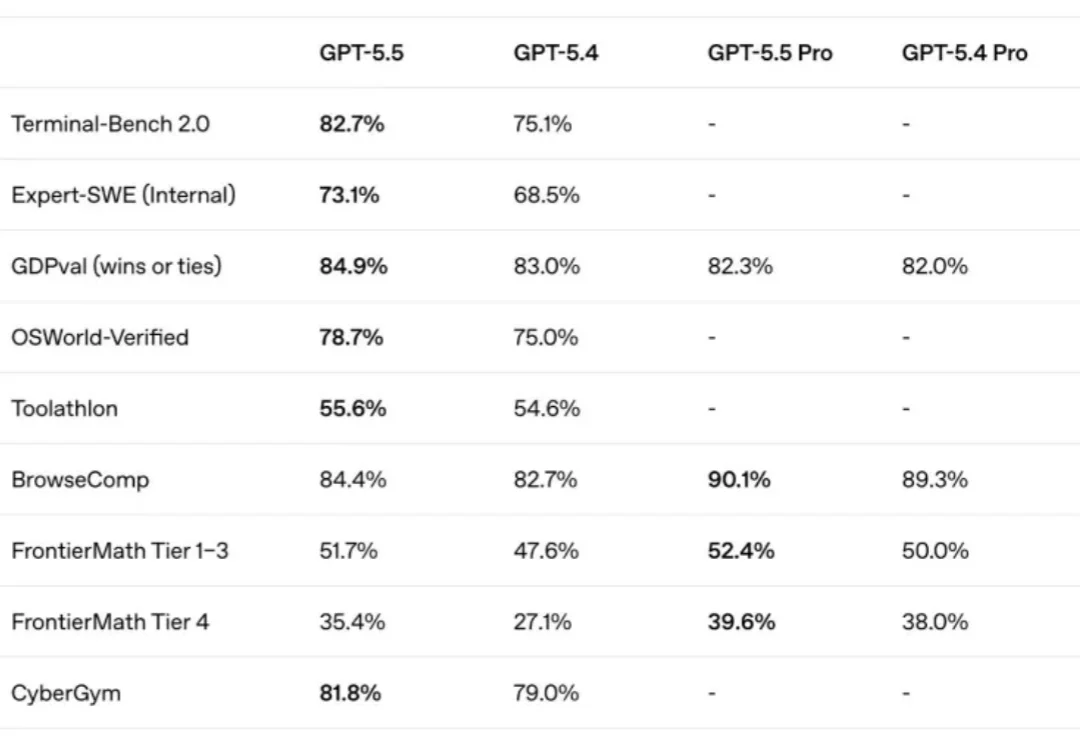
OpenAI科学家Noam Brown:AI的真正上限,可能根本没人测得起
OpenAI科学家Noam Brown:AI的真正上限,可能根本没人测得起随着大语言模型逐步进入复杂推理、自动化研究和网络安全等高难度任务,传统的模型评测方式正在面临新的挑战。
来自主题: AI资讯
6702 点击 2026-06-10 15:16
 搜索
搜索
随着大语言模型逐步进入复杂推理、自动化研究和网络安全等高难度任务,传统的模型评测方式正在面临新的挑战。
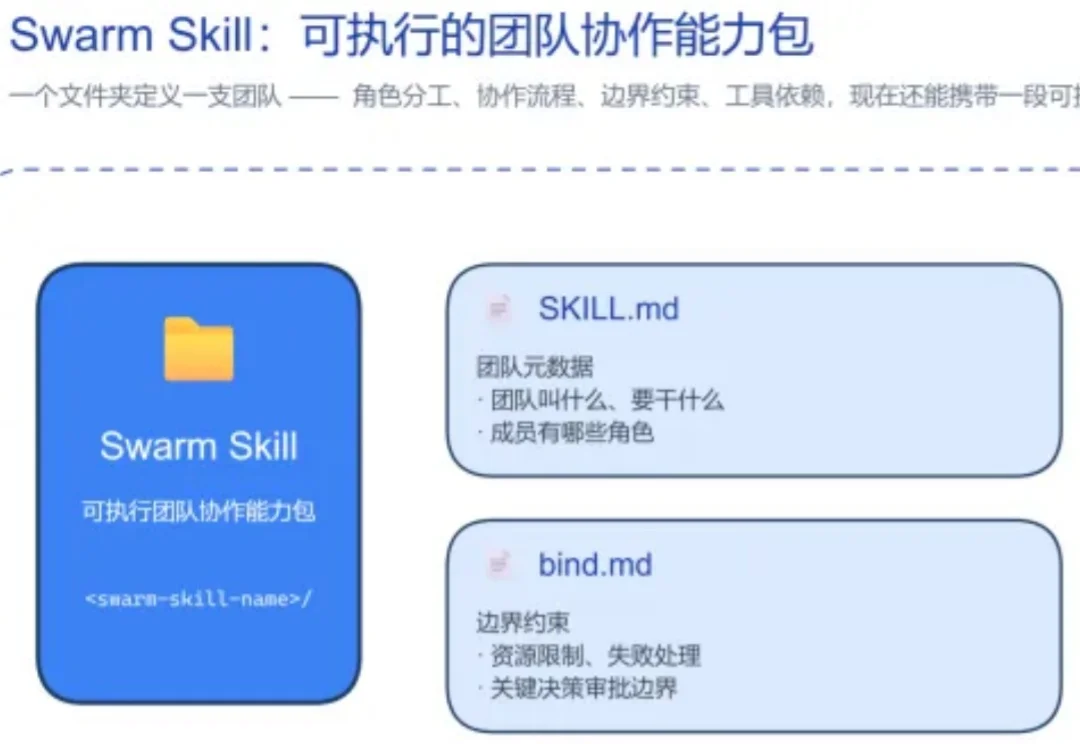
AI Agent 正在从 "单兵作战" 走向 "团队协作"—— 让多个 Agent 分工配合,去完成单个 Agent 难以独立扛下来的复杂任务,也是近期最受关注的方向之一。
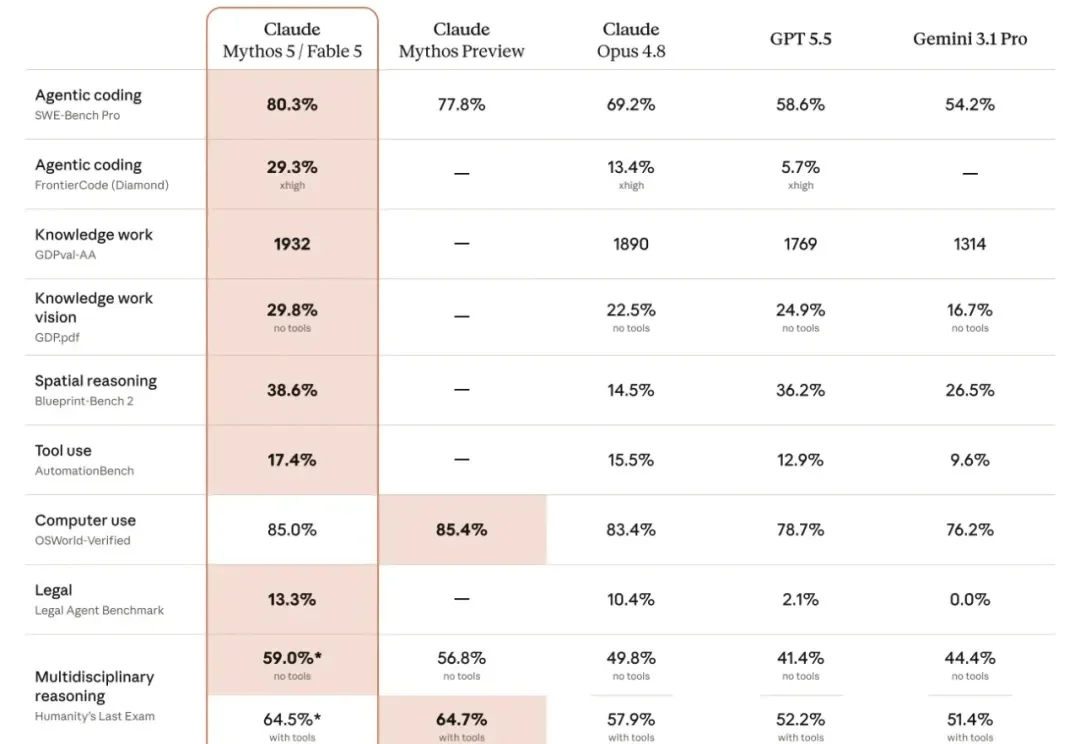
今天凌晨,Anthropic 发布新模型 Fable 5,毫无疑问的,也是当下的最强模型

世界模型(World Model),正在成为AI领域新的技术高地。从OpenAI的Sora,到图灵奖得主Yann LeCun力推的JEPA体系,再到李飞飞创办的World Labs,全球最顶尖的一批研究者都在试图回答同一个问题:AI究竟如何像人一样理解世界,而不仅仅是生成语言和图像。
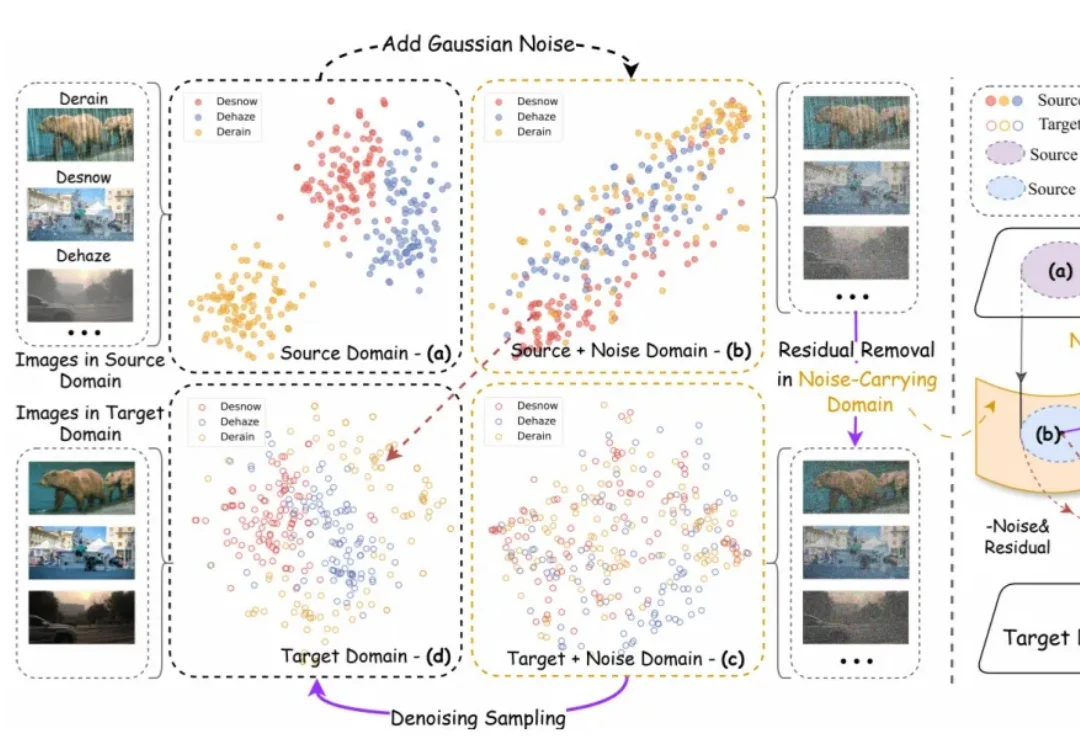
在图像到图像翻译(Image-to-Image Translation, I2I)这个任务上,扩散模型过去几年几乎形成了一套默认逻辑:先把输入图像和噪声混合,再一步步去噪,把目标图像 “还原” 出来。

顶级AI编码一日千里,到了生物学领域却频频翻车,并非模型不够聪明,而是科学数据库至今只为人类点鼠标而生。

具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。
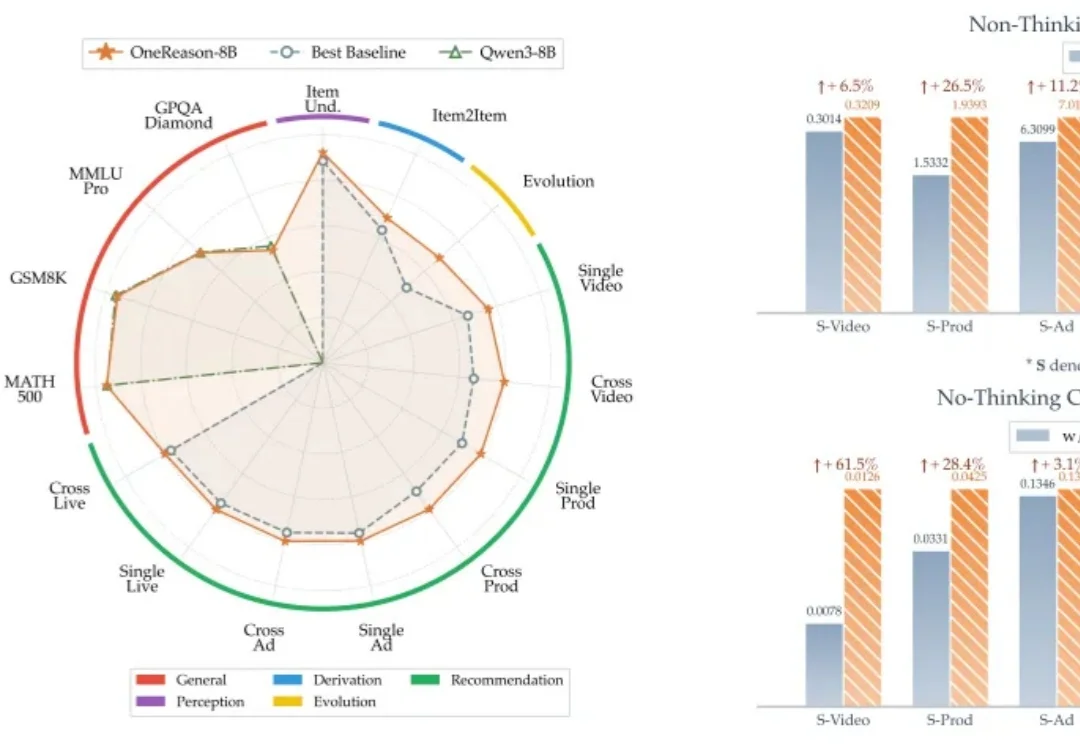
推荐系统的过去十年,本质是把 "用户 - 物料" 的统计共现挖到极致 —— 从协同过滤、深度模型,到生成式 OneRec 系列,每一代都在让 "记忆" 更精细、参数更大、序列更长,也让 Scaling 这件事在工业级推荐系统上跑通,持续释放算力红利。

Transformer 依托强大的建模能力和 Scaling 效率在推荐领域被广泛应用于超长序列建模和生成式推荐等方向,
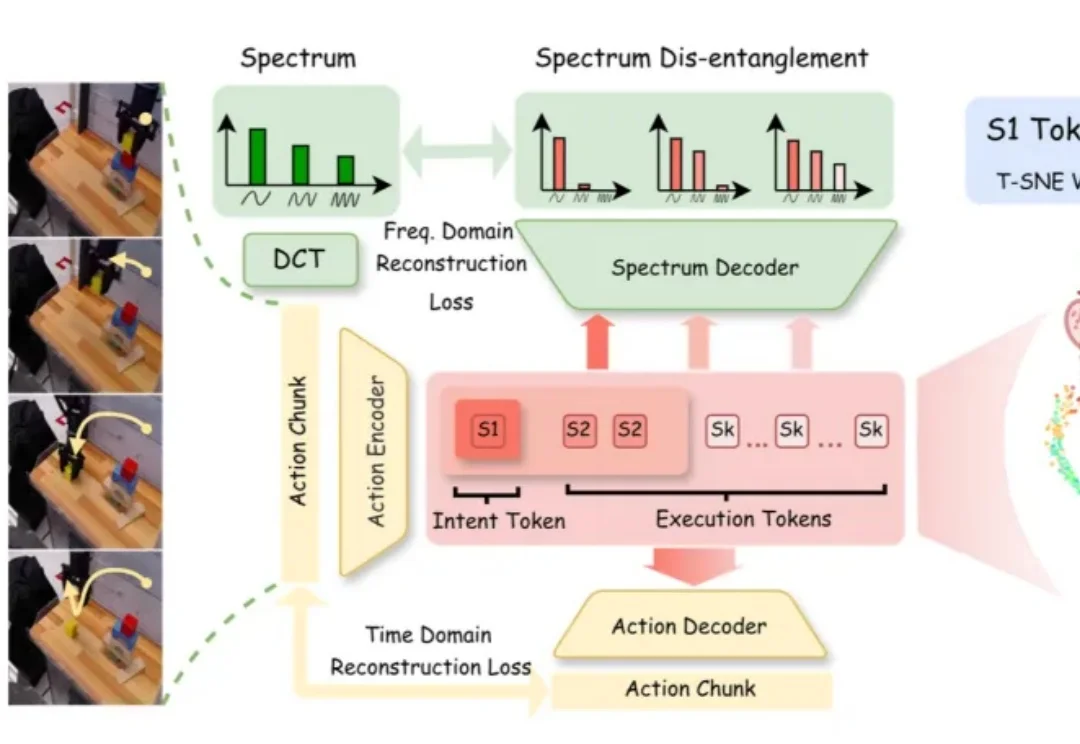
机器人视觉语言动作(Vision-Language-Action, VLA)模型越来越多地开始展示叠衣服、倒茶、做咖啡等复杂操作。但是,今天的大多数 VLA 更像 “展台机器人”。