「开发者私下更喜欢用GPT-5写代码」,Claude还坐得稳编程王座吗?
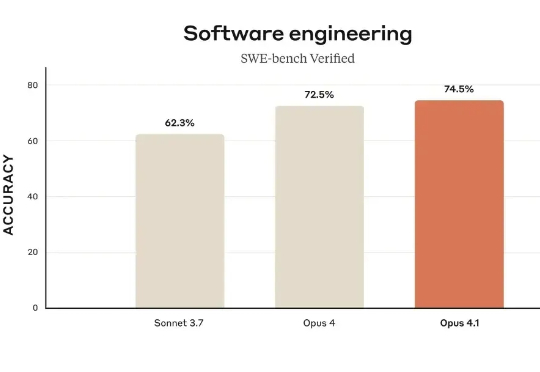
「开发者私下更喜欢用GPT-5写代码」,Claude还坐得稳编程王座吗?一直以来,Anthropic 的 Claude 被认为是处理编程任务的最佳模型,尤其是本月初发布的 Claude Opus 4.1,在真实世界编程、智能体以及推理任务上表现出色。其中在软件编程权威基准 SWE-bench Verified 测试中,Claude Opus 4.1 相较于前代 Opus 4 又有提升,尤其在多文件代码重构方面表现出显著进步。
来自主题: AI资讯
9633 点击 2025-08-27 18:09