
OpenAI明升,Anthropic暗涨:AI包月折扣没了
OpenAI明升,Anthropic暗涨:AI包月折扣没了4月,OpenAI Codex正式把计费口径从按消息估算转向按token用量;Anthropic侧的企业续约和新版模型tokenizer(分词器),也让 Claude Code的实际账单压力集中显现。明升与暗涨,两家各有各的玩法。
来自主题: AI资讯
8183 点击 2026-05-31 12:10
 搜索
搜索
4月,OpenAI Codex正式把计费口径从按消息估算转向按token用量;Anthropic侧的企业续约和新版模型tokenizer(分词器),也让 Claude Code的实际账单压力集中显现。明升与暗涨,两家各有各的玩法。

大模型从“回答问题”走向“完成任务”,正在面临以下瓶颈:面向Claw Agents的数据、训练和评测都比传统environment training更难。为了解决该问题,中国人民大学、至知研究院等最新提出ClawGym——
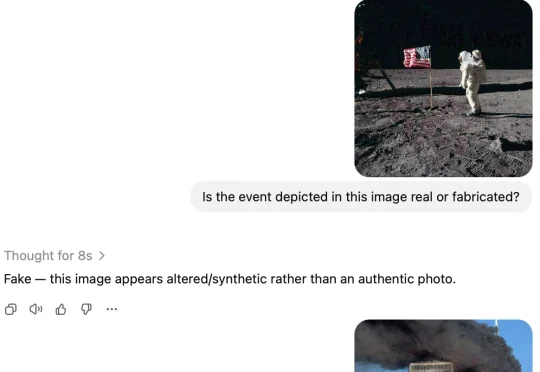
来自 ETH Zurich 的 Florian Tramèr 团队在最新论文中抛出了一个出乎意料的问题:如果 AI"看到" 的图,根本不是你肉眼看到的那张,会发生什么样的后果呢?他们把这种现象称作 AI 权威清洗(AI Authority Laundering)。

今天,阿里Qoder上线Cloud Agents,这是全托管的AI Agent运行平台,可提供Agent底座、模型服务及运行环境等全栈Agent能力,企业可通过API的方式直接调用,让应用和业务系统快速长出“大脑”和“双手”,Agent 上线时间从1个月缩短至1天。
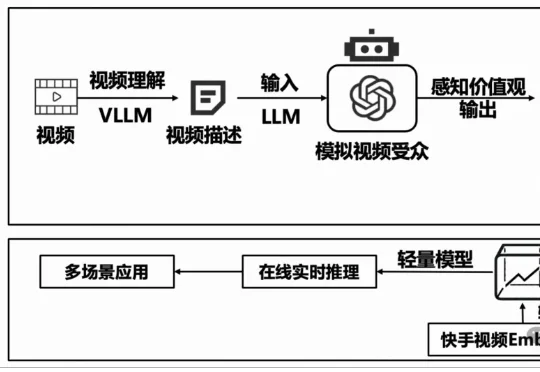
清华大学经济管理学院的陈柯均博士生、张佳音教授、徐心教授与快手消费策略算法部合作探索完成了一项联合实验:从视频传递的价值观的角度,去理解观看视频后用户的行为和心理变化。
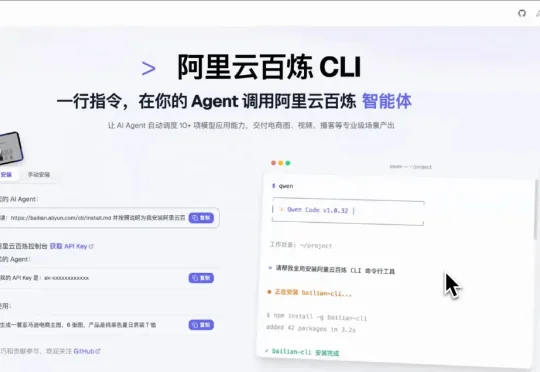
今天,阿里云百炼核心能力已CLI化 ,仅需一行命令,即可让Agent自动接入阿里云百炼的150多款模型、十多款应用,以及知识库、记忆、联网搜索等全套能力。百炼CLI专为Agent设计,原生支持Clau
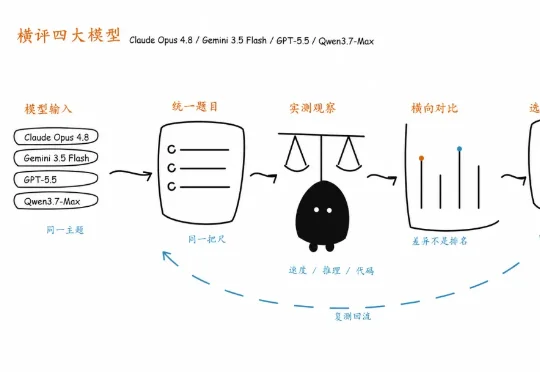
普通人看排行榜估计越看越疑惑,写文章该用哪个?数据分析该用哪个?写代码、审 PR、拆任务又该用哪个?我挑了四款最近讨论度很高的模型:Claude Opus 4.8、Gemini 3.5 Flash、GPT-5.5、Qwen3.7-Max,做一次横评,看看它们在真实任务里的交付表现。

5 月下旬,NVIDIA 联合清华大学、多伦多大学和 Vector Institute 发布 Gamma-World,共一第一为清华大学电子系博士刘芳甫,核心 Research 方向是世界模型和空间智能。

证监会官网显示,上海AI大模型龙头企业MiniMax已于5月29日向上海证监局提交了上市辅导备案报告,开启A股上市进程,中信证券担任辅导机构。这也意味着,MiniMax将与已经提交A股上市辅导备案的智谱,一同冲刺A股大模型第一股。

绝大多数 AI 陪伴产品,都是基于通用模型的使用,利用提示词框架对模型进行定向约束,所以角色的表达仍然停留在「人类平均水平」,本质都是提示词驱动下的角色扮演。但陆弘毅做蕾伊的方法完全不同。团队先为她写了几十万字的人格语料,确定她从小到大的经历、行为与反应、深层性格和内在冲突,再把这些只属于蕾伊的数据灌进他们自研的「超人格化模型」。