
UniToken:多模态AI的“全能选手”,一次编码搞定图文理解与图像生成!
UniToken:多模态AI的“全能选手”,一次编码搞定图文理解与图像生成!复旦大学和美团的研究者们提出了UniToken——一种创新的统一视觉编码方案,在一个框架内兼顾了图文理解与图像生成任务,并在多个权威评测中取得了领先的性能表现。
来自主题: AI技术研报
8350 点击 2025-04-25 09:56
 搜索
搜索
复旦大学和美团的研究者们提出了UniToken——一种创新的统一视觉编码方案,在一个框架内兼顾了图文理解与图像生成任务,并在多个权威评测中取得了领先的性能表现。

当城市天气预报有望精确到街镇,每条马路都可能拥有“独家预报”——这并非科幻场景,而是上海“扶摇”气象大模型带来的突破。
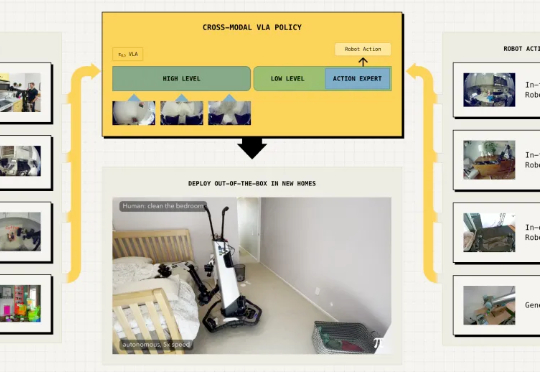
今天,美国具身智能公司 Physical Intelligence 推出了一个基于 π0 的视觉-语言-动作(VLA)模型 π0.5,其利用异构任务的协同训练来实现广泛的泛化,可以在全新的家中执行各种任务。

RL + LLM 升级之路的四层阶梯。
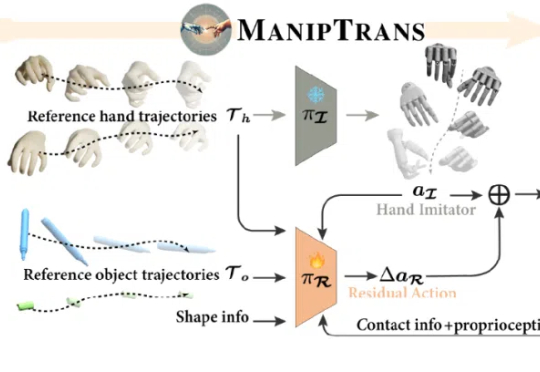
近年来,具身智能领域发展迅猛,使机器人在复杂任务中拥有接近人类水平的双手操作能力,不仅具有重要的研究与应用价值,也是迈向通用人工智能的关键一步。
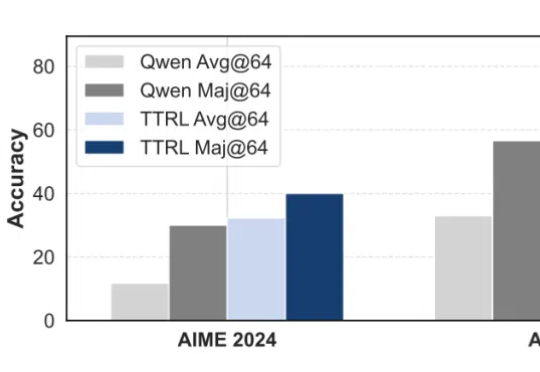
无需数据标注,在测试时做强化学习,模型数学能力暴增159%!

现在,不论你是去吃火锅,亦或是去趟医院,或许身边已经布满了AI。
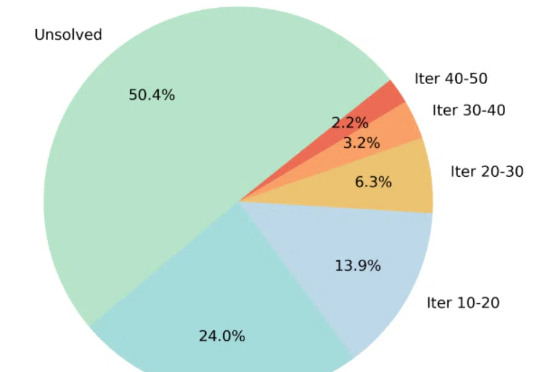
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。
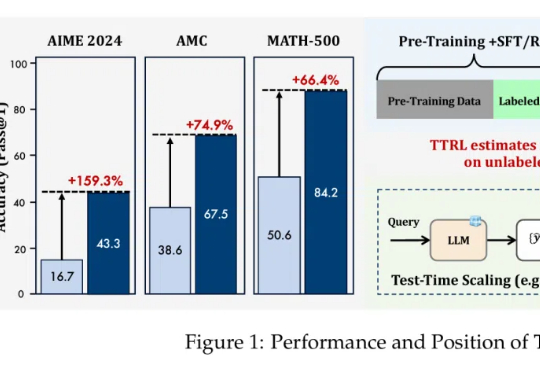
在大语言模型(LLMs)竞争日趋白热化的今天,「推理能力」已成为评判模型优劣的关键指标。
上个月,OpenAI 在 ChatGPT 中引入了图像生成功能,广受欢迎:仅在第一周,全球就有超过 1.3 亿用户创建了超过 7 亿张图片。就在刚刚,OpenAI 又宣布了一个好消息:他们正式在 API 中推出驱动 ChatGPT 多模态体验的原生模型 ——gpt-image-1,让开发者和企业能够轻松将高质量、专业级的图像生成功能直接集成到自己的工具和平台中。