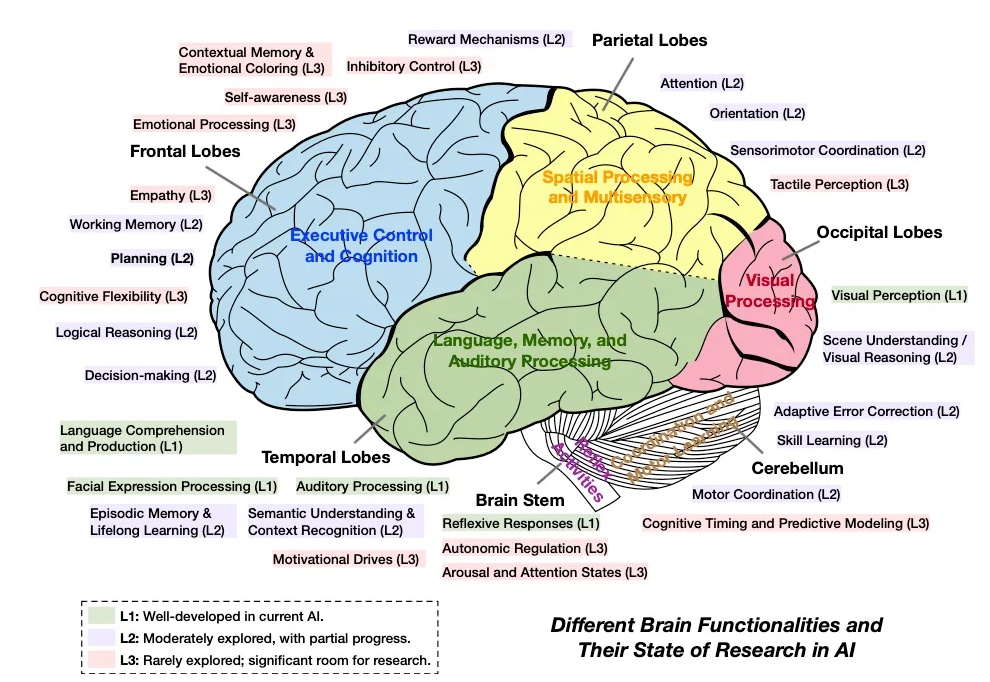
264页智能体综述来了!MetaGPT等20家顶尖机构、47位学者参与
264页智能体综述来了!MetaGPT等20家顶尖机构、47位学者参与近期,大模型智能体(Agent)的相关话题爆火 —— 不论是 Anthropic 抢先 MCP 范式的快速普及,还是 OpenAI 推出的 Agents SDK 以及谷歌最新发布的 A2A 协议,都预示了 AI Agent 的巨大潜力。
来自主题: AI技术研报
8699 点击 2025-04-21 09:28
 搜索
搜索
近期,大模型智能体(Agent)的相关话题爆火 —— 不论是 Anthropic 抢先 MCP 范式的快速普及,还是 OpenAI 推出的 Agents SDK 以及谷歌最新发布的 A2A 协议,都预示了 AI Agent 的巨大潜力。

现阶段,每因智能主要通过商业保险这一切口,与政府部门和大型保司开展相关合作,促进商业转化。
AI圈最近弥漫着一股微妙的气息。人们似乎不再热议大语言模型的最新突破、以及AI应用的无限可能时,一些代表着未来的AI巨头,却似乎正将目光投向互联网那熟悉得不能再熟悉的角落——社交网络与社区。

鲜为人知的是,目前国内超过60%的AI应用,包括DeepSeek的C端应用,联网搜索能力是通过集成博查AI的Search API实现的。大模型需要通过这类API,才能够动态获取最新信息,并输出给用户。AI搜索和传统搜索在入口端的界面上非常相似,底层技术和最终返回给用户的体验却截然不同。

“能流畅跑70B模型的国产GPU有推荐的吗?”在一个算力交流群里,一位从业者问。不少回复打趣道:“48GB显存的4090。”智算中心、

具身智能的突破离不开高质量数据。目前,具身合成数据有两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。英伟达在CES 2025指出“尚无互联网规模的机器人数据”,自动驾驶已具备城市级仿真,但家庭等复杂室内环境缺乏3D合成平台。

微软研究院开源的原生1bit大模型BitNet b1.58 2B4T,将低精度与高效能结合,开创了AI轻量化的新纪元。通过精心设计的推理框架,BitNet不仅突破了内存的限制,还在多项基准测试中表现出色,甚至与全精度模型不相上下。

4月18日~19日,由《中国企业家》杂志社主办的2025(第十七届)商界木兰年会在北京举办。在“开幕对话”环节, 数坤科技创始人、CEO马春娥作为主理人, 与明势创投创始合伙人黄明明、中科闻歌董事长王磊、零一万物联合创始人马杰、腾讯设计杰出专家陈妍,围绕“大模型迭代”进行了访谈对话。

Nemotron-H模型混合了Transformer和Mamba架构,使长文本推理速度提升3倍,同时还能保持高性能,开源版本包括8B和56B尺寸。训练过程采用FP8训练和压缩技术,进一步提高了20%推理速度

现在下场做 AI 产品的创业者越来越多,但创业总归是“九死一生”的艰难旅途,我更关心的是,有没有一些有迹可循的办法,能提高成功率?上周,我和一位非典型 AI 创业者——米可世界 AI Lab 的负责人 Simon 聊了一次天,聊出了很多在 AI 创业的宏大叙事中没有的“大实话”,也获得了不少启发。