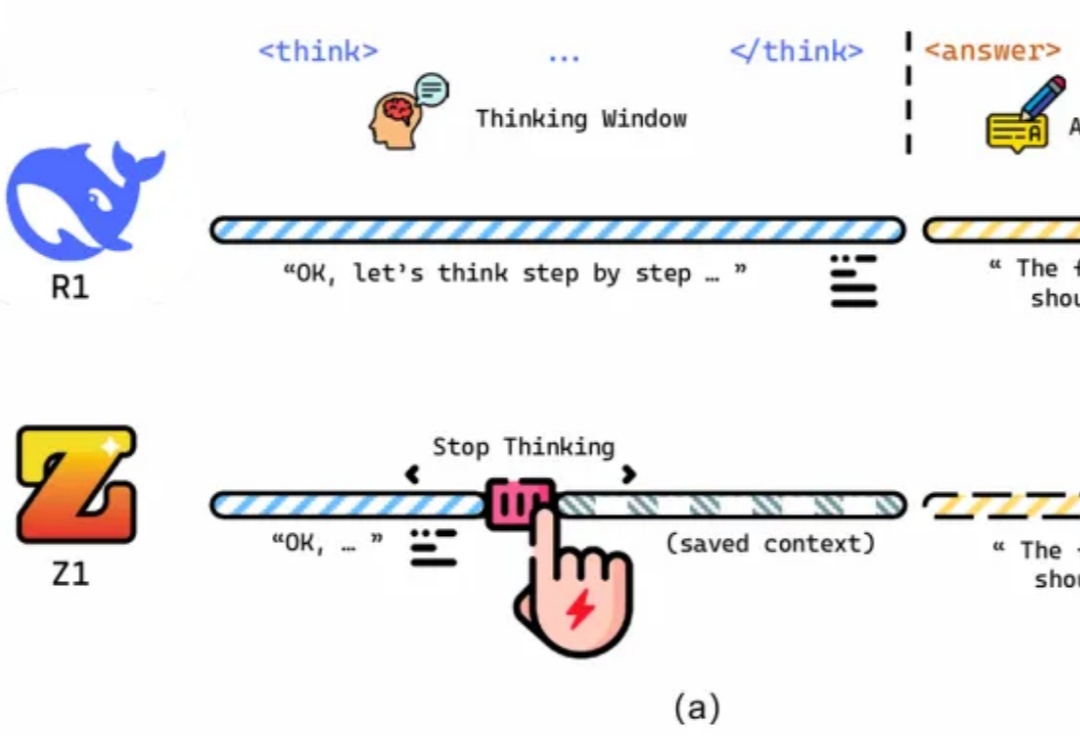
清华耶鲁推理模型新范式:动态推理实现高效测试时扩展,大大节省Token消耗
清华耶鲁推理模型新范式:动态推理实现高效测试时扩展,大大节省Token消耗推理性能提升的同时,还大大减少Token消耗!
来自主题: AI技术研报
8771 点击 2025-04-08 09:25
 搜索
搜索
推理性能提升的同时,还大大减少Token消耗!
如何让大模型更懂「人」?
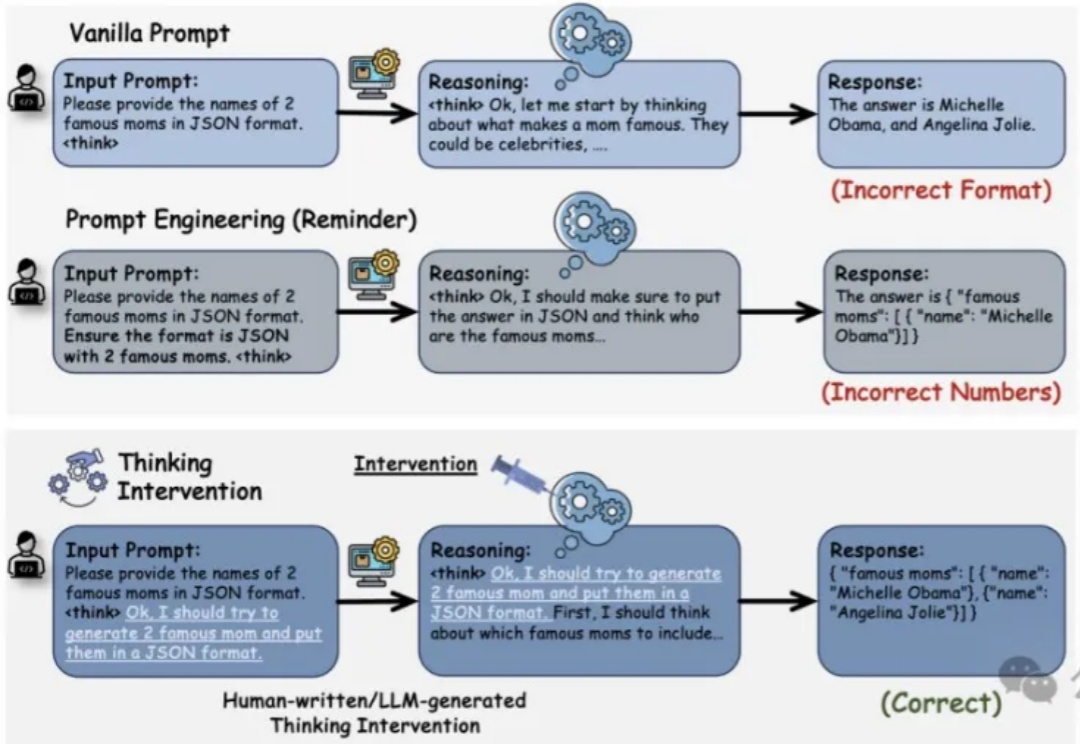
推理增强型大语言模型LRM(如OpenAI的o1、DeepSeek R1和Google的Flash Thinking)通过在生成最终答案前显式生成中间推理步骤,在复杂问题解决方面展现了卓越性能。然而,对这类模型的控制仍主要依赖于传统的输入级操作,如提示工程(Prompt Engineering)等方法,而你可能已经发现这些方法存在局限性。
AI菩萨OpenRouter连发两大招宣布推出两项重大更新。

Meta最新基础模型Llama 4发布36小时后,评论区居然是这个画风:
「未来,99% 的 attention 将是大模型 attention,而不是人类 attention。」这是 AI 大牛 Andrej Karpathy 前段时间的一个预言。这里的「attention」可以理解为对内容的需求、处理和分析。也就是说,他预测未来绝大多数资料的处理工作将由大模型来完成,而不是人类。

Noprop:没有反向传播或前向传播,也能训练神经网络。

让大语言模型更懂特定领域知识,有新招了!
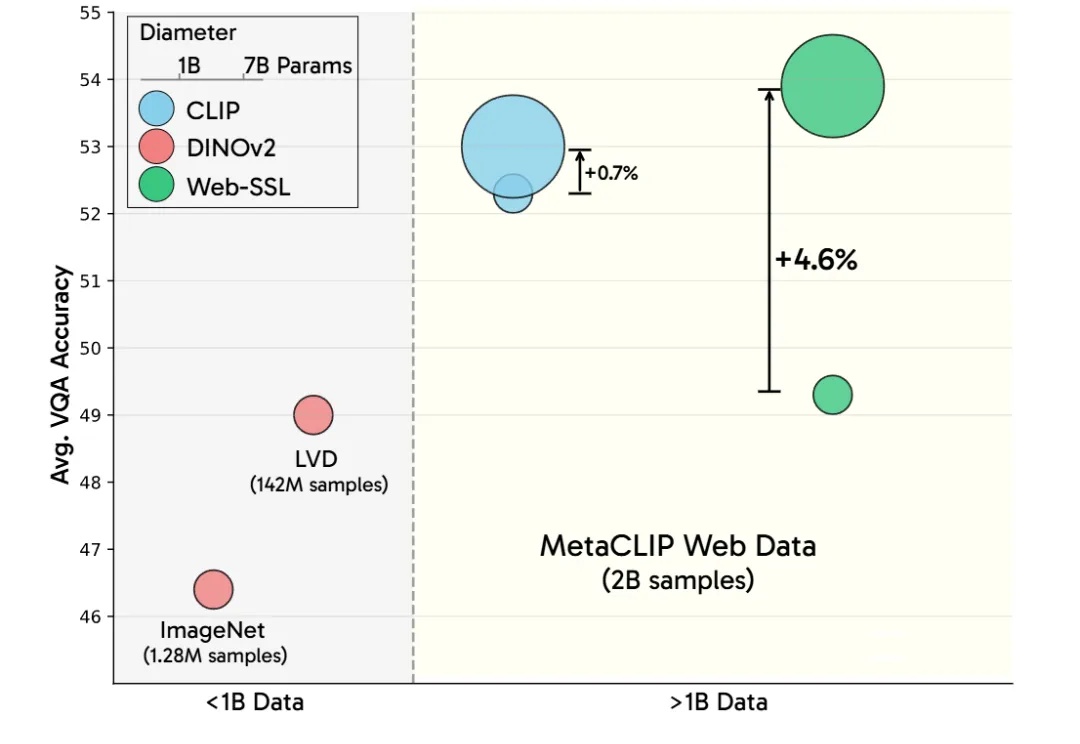
LeCun谢赛宁等研究人员通过新模型Web-SSL验证了SSL在多模态任务中的潜力,证明其在扩展模型和数据规模后,能媲美甚至超越CLIP。这项研究为无语言监督的视觉预训练开辟新方向,并计划开源模型以推动社区探索。
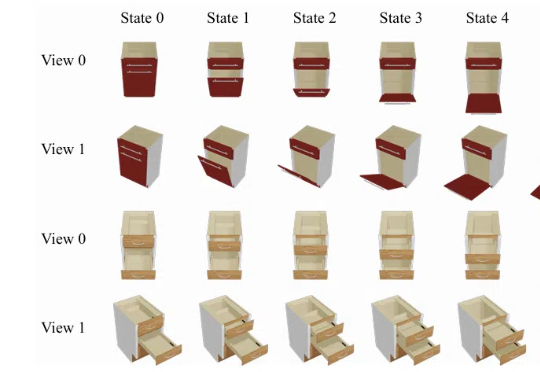
基于当前观察,预测铰链物体的的运动,尤其是 part-level 级别的运动,是实现世界模型的关键一步。