一家垂类 AI 创企FlashLabs的自救:当通用模型开始吃掉一切
一家垂类 AI 创企FlashLabs的自救:当通用模型开始吃掉一切FlashLabs 创始人石一,过去一年就活在这个问题里。他做了一系列在外人看来相当反常识的决定:推翻产品路线、主动缩减团队、放弃短期商业化指标,甚至把公司名字都改了。我们和他聊了聊,在通用模型进化的时代,曾经的垂类 AI 创企到底该怎么活下去。
来自主题: AI资讯
8735 点击 2026-05-24 10:36
 搜索
搜索
FlashLabs 创始人石一,过去一年就活在这个问题里。他做了一系列在外人看来相当反常识的决定:推翻产品路线、主动缩减团队、放弃短期商业化指标,甚至把公司名字都改了。我们和他聊了聊,在通用模型进化的时代,曾经的垂类 AI 创企到底该怎么活下去。

最近,来自上海创智学院、复旦大学等机构的研究者提出了 Hallo-Live,试图正面解决这个矛盾。论文于 2026 年 4 月 26 日 发布在 arXiv。该方法将 异步双流扩散(Asynchronous Dual-Stream Diffusion) 与 人类偏好引导蒸馏(Human-Centric Preference-Guided DMD) 结合起来

Anthropic实锤:Claude裸跑模型,9美元全废;但是套上Harness花200美元效果直接起飞。AI效果不好?别再纠结换模型了!OpenAI和Anthropic都在用的Harness工程,一文讲透。
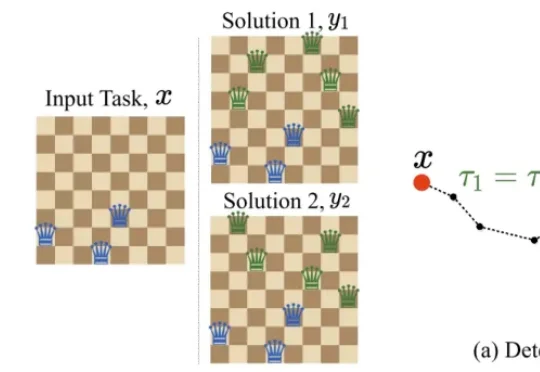
现在,图灵奖得主 Yoshua Bengio 给出了一份全新的并行方案。他们提出了 GRAM(Generative Recursive reAsoning Models,生成式递归推理模型),把确定性的递归潜在推理变成了概率性的多轨迹计算。模型在潜在空间中进行随机递归推理,每一步都可以采样不同的方向,最终形成对解空间的多路径探索。

这不是科幻小说,而是 METR(模型评估与训练研究组织)联合Anthropic、Google、Meta和OpenAI 进行内部红队测试后,发布的首份《前沿风险报告》中披露的真实案例。这是四大巨头第一次允许第三方深入测试他们内部最强、可访问完整思维链(CoT)的模型,并开放非公开的对齐与控制信息。
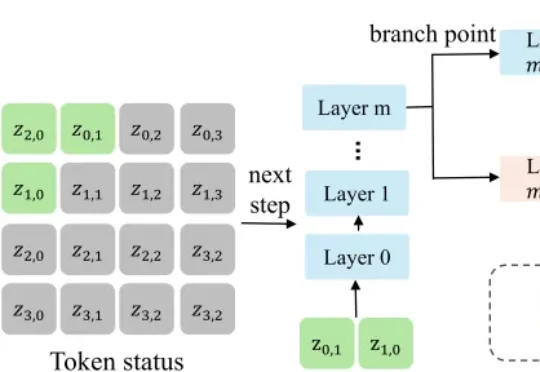
来自浙江大学和阿德莱德大学的研究团队提出了 FlashAR—— 一个轻量级的后训练加速框架。不需要从头训练,在 Emu3.5-Image-34B 模型上,仅用原始训练数据的 0.05%(约 8 万张图片),就能将预训练好的自回归模型改造成高度并行的生成器 Emu3.5-34B-Flash,实现最高 22.9 倍的端到端加速。
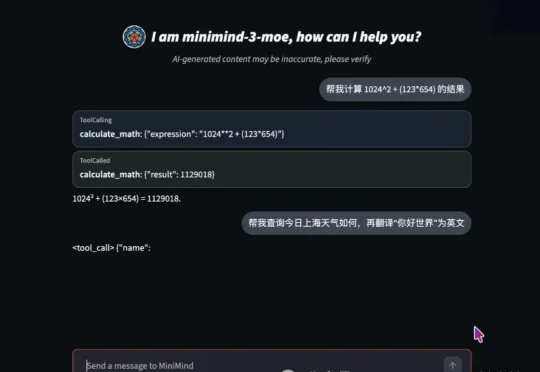
我最近当 AI 班狗刷抖音,一周里被同一个项目推流了三次。项目叫 MiniMind。打开 GitHub,50.4K stars,持续上涨种。这个项目大致就是:几块钱,几个小时,从 0 开始训练一个几十 MB 的小模型。
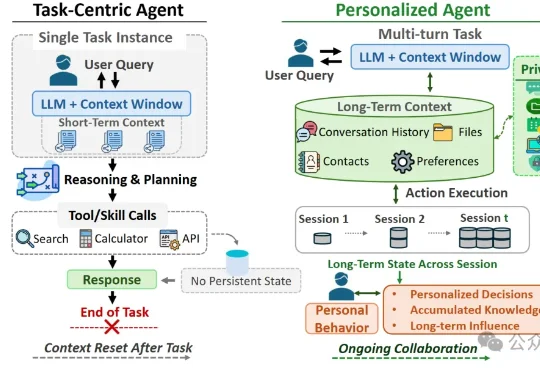
日常聊天可能在不经意间污染个性化Agent的长期记忆,使其在未来任务中偏离用户真实意图。研究人员通过ULSPB基准测试发现,即使无恶意提示,日常对话也可能改变Agent的安全边界。
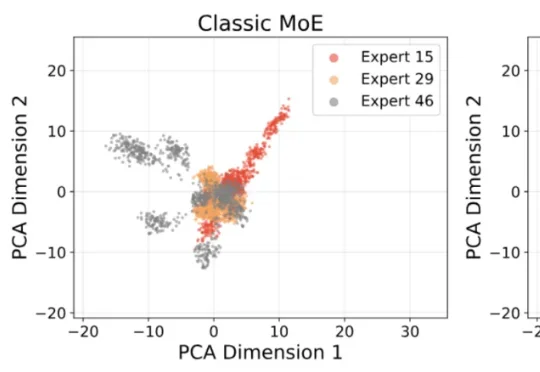
近年来,Mixture-of-Experts(MoE)已经成为大模型扩展的重要架构之一。相比稠密 Transformer,MoE 通过稀疏激活机制,在每个 token 上只调用少量专家,从而在控制计算成本的同时扩大模型容量。然而,一个长期存在的问题是:专家越多,并不意味着专家真的学得越 “专”。

Jim Fan 押注的这条 “先预测世界,再生成动作” 的新路,正是当下具身智能领域最炙手可热的下一代范式 —— 世界动作模型(World Action Models,简称 WAM)。虽然 WAM 正在迅速成为各大顶尖实验室的核心发力点,但业界至今仍然缺乏对它的统一标准和系统梳理。近期,复旦大学可信具身智能研究院,上海创智学院,新加坡国立大学发表了首篇 WAM 的详细综述。