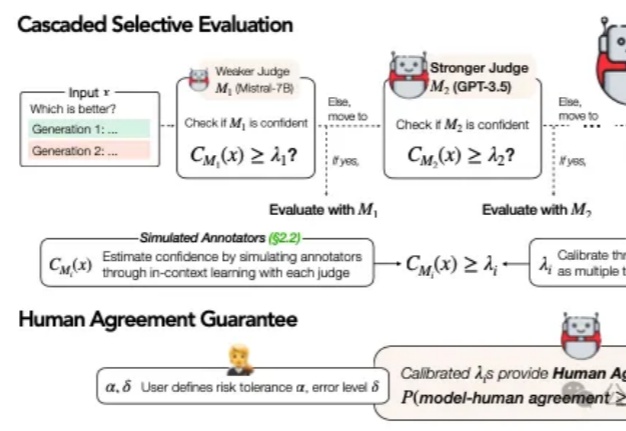
选LLM-Judge评估,用这个可证明的人类对齐评估框架, ICLR2025匿名论文
选LLM-Judge评估,用这个可证明的人类对齐评估框架, ICLR2025匿名论文在当今AI技术迅猛发展的背景下,大语言模型(LLM)的评估问题已成为一个不可忽视的挑战。传统的做法是直接采用最强大的模型(如GPT-4)进行评估,这就像让最高法院的大法官直接处理所有交通违章案件一样,既不经济也不一定总能保证公正。
来自主题: AI技术研报
7214 点击 2025-01-20 10:50
 搜索
搜索
在当今AI技术迅猛发展的背景下,大语言模型(LLM)的评估问题已成为一个不可忽视的挑战。传统的做法是直接采用最强大的模型(如GPT-4)进行评估,这就像让最高法院的大法官直接处理所有交通违章案件一样,既不经济也不一定总能保证公正。
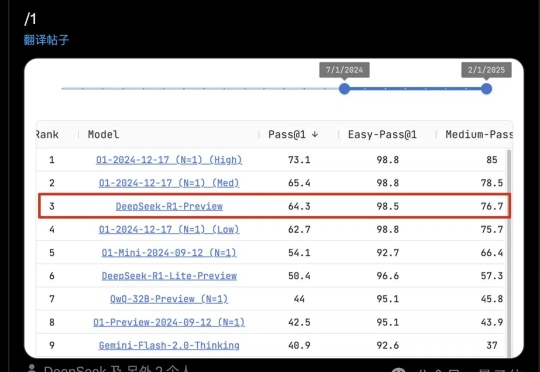
DeepSeek版o1,有消息了。还未正式发布,已在代码基准测试LiveCodeBench霸榜前三,表现与OpenAI o1的中档推理设置相当。注意了,这不是在DeepSeek官方App已经能试玩的DeepSeek-R1-Lite-Preview(轻量预览版)。
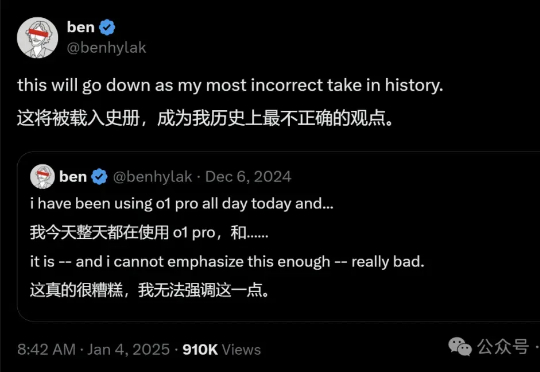
Ben Hylak从最初对o1不满到逐渐掌握使用技巧,成功将其转化为解决重要问题的得力工具。本文探讨了如何正确使用o1,解锁其强大的报告生成和推理分析能力。
【新智元导读】逆龄AI真的被OpenAI实现了!新模型GPT-4b micro通过蛋白质重编程技术,有望将人类寿命延长十年。
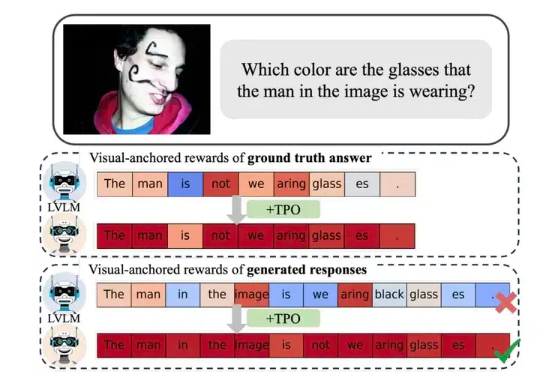
近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。

据外电报道,就在谷歌与美联社签署协议的第二天,Mistral 还宣布与法新社 (AFP) 达成内容协议,以提高Mistral 聊天机器人产品Le Chat的答案的准确性。对于这家总部位于巴黎的人工智能公司来说,这是第一笔此类交易。这表明 Mistral 不想被视为仅仅一家基础模型制造商。

2024又是AI精彩纷呈的一年。LLM不再是AI舞台上唯一的主角。随着预训练技术遭遇瓶颈,GPT-5迟迟未能问世,从业者开始从不同角度寻找突破。以o1为标志,大模型正式迈入“Post-Training”时代;开源发展迅猛,Llama 3.1首次击败闭源模型;中国本土大模型DeepSeek V3,在GPT-4o发布仅7个月后,用 1/10算力实现了几乎同等水平。

近日,珞博智能(Robopoet)官方发布一则消息,前字节大模型解决方案架构师潘雨楠(Yuna)正式加入珞博,出任联合创始人兼首席技术官(CTO)。潘雨楠本科毕业于哈尔滨工业大学,又在香港大学取得计算机专业硕士学位,她的学术背景为其在科技领域的发展奠定了坚实基础。

大模型的记忆片段进行多次替换的时候,会导致模型输出的内容叠加不同记忆片段,出现混淆和错乱的问题。在我做 Crew.ai 知识库测试的时,替换多份知识库文档后,发现大模型已经疯了。

昨天,我们报道了一个行业猜想,说是 OpenAI 和 Anthropic 等前沿大模型公司可能已经训练出了下一代大模型,但由于它们的使用成本过高,所以短时间内根本不会被放出来。