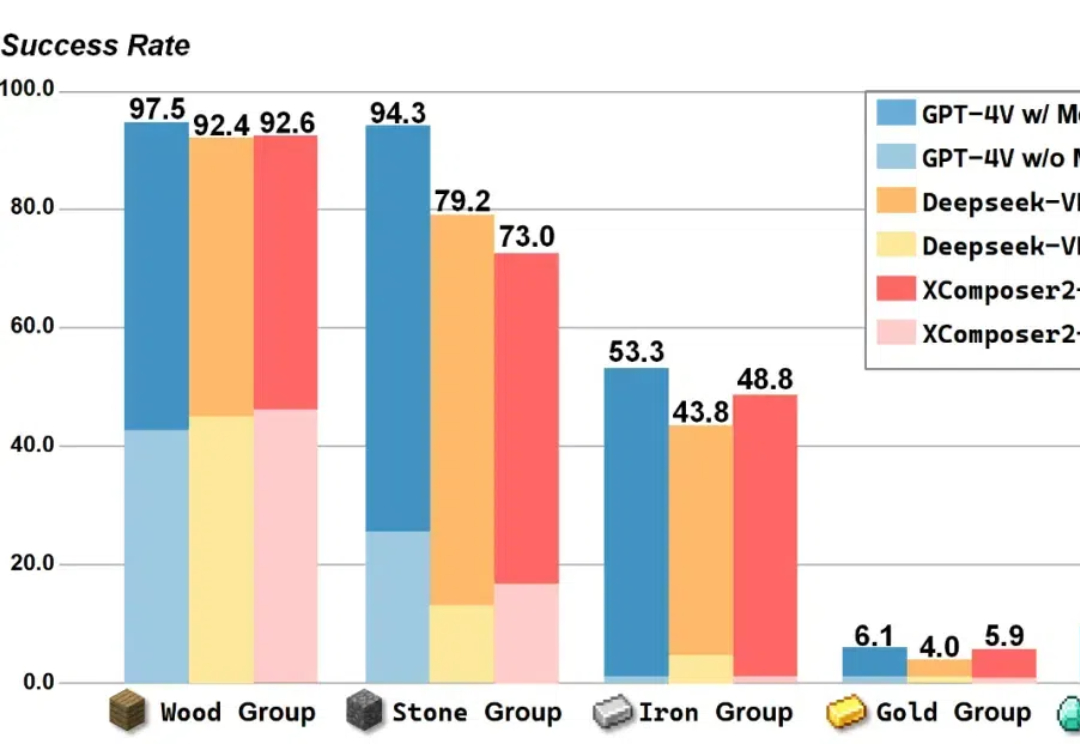
NeurIPS 2024 | 哈工深提出新型智能体Optimus-1,横扫Minecraft长序列任务
NeurIPS 2024 | 哈工深提出新型智能体Optimus-1,横扫Minecraft长序列任务在 Minecraft 中构造一个能完成各种长序列任务的智能体,颇有挑战性。现有的工作利用大语言模型 / 多模态大模型生成行动规划,以提升智能体执行长序列任务的能力。
来自主题: AI技术研报
8373 点击 2024-12-06 17:58
 搜索
搜索
在 Minecraft 中构造一个能完成各种长序列任务的智能体,颇有挑战性。现有的工作利用大语言模型 / 多模态大模型生成行动规划,以提升智能体执行长序列任务的能力。

目前,这一领域发展迅速,但现有综述多聚焦于单智能体的架构、特定能力或多智能体系统的某些方面,尚缺乏从个体到社会模拟的系统性回顾。因此,本文试图填补这一空白,为该领域提供全面的概述。

全国首个零售金融领域大模型天镜,揭晓了过去460多天的成绩单。 目前已实现智能营销交互、数据决策支持、防伪安全等八大应用场景。1.0版本人机交互模型完成100亿交易额,全面服务超2亿用户。
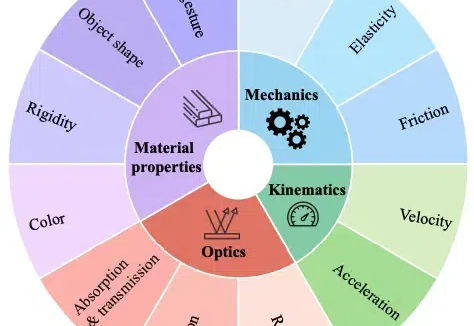
融合物理知识的大型视频语言模型PhysVLM,开源了! 它不仅在 PhysGame 基准上展现出最先进的性能,还在通用视频理解基准上(Video-MME, VCG)表现出领先的性能。

随着“AI妖股”Applovin股价暴涨790%,市值超过1000亿美金,国内大厂正加速发力生成式 AI 营销广告领域。

在AI迅速发展的技术背景下,如何更高效地利用模型资源成为了一个关键问题。批处理提示(Batch Prompting)作为一种同时处理多个相似查询的技术,虽然在提高计算效率方面显示出巨大潜力,但同时也面临着性能下降的挑战。香港理工大学的研究团队提出的Auto-Demo提示技术,为这一问题带来了突破性的解决方案。

AGI 啥时候真来,咱还是得说句,再等等。 开了眼了,上周编辑部还在说下半年感觉 AI 领域没啥大活儿了,结果没过几天就发现话放早了。 宁猜怎么着,本来以为 AI 还停留在输入文字,然后出图出视频的这些程度上,结果这两天突然有几个 AI 公司,都开始宣布人家可以生成世界了。

今天,LiblibAI与千万用户一起揭幕我们的自研图像大模型。 Star-3 Alpha 图像基座模型来了。Star-3 Alpha大模型,基于业界领先的F.1基础算法架构训练而成。 相较于以往的所有模型,Star-3 Alpha在生图效果上实现了显著的飞跃,在图像精准度、色彩表现力、美学捕捉的细腻表达等方面成为新的业界标杆。
Yoshua Bengio最近在《金融时报》的专栏文章中表示,「AI可以在说话之前学会思考」,实现内部的深思熟虑将成为AGI道路的里程碑。无独有偶,就在几个月前,Yann LeCun也多次表达过类似的观点。
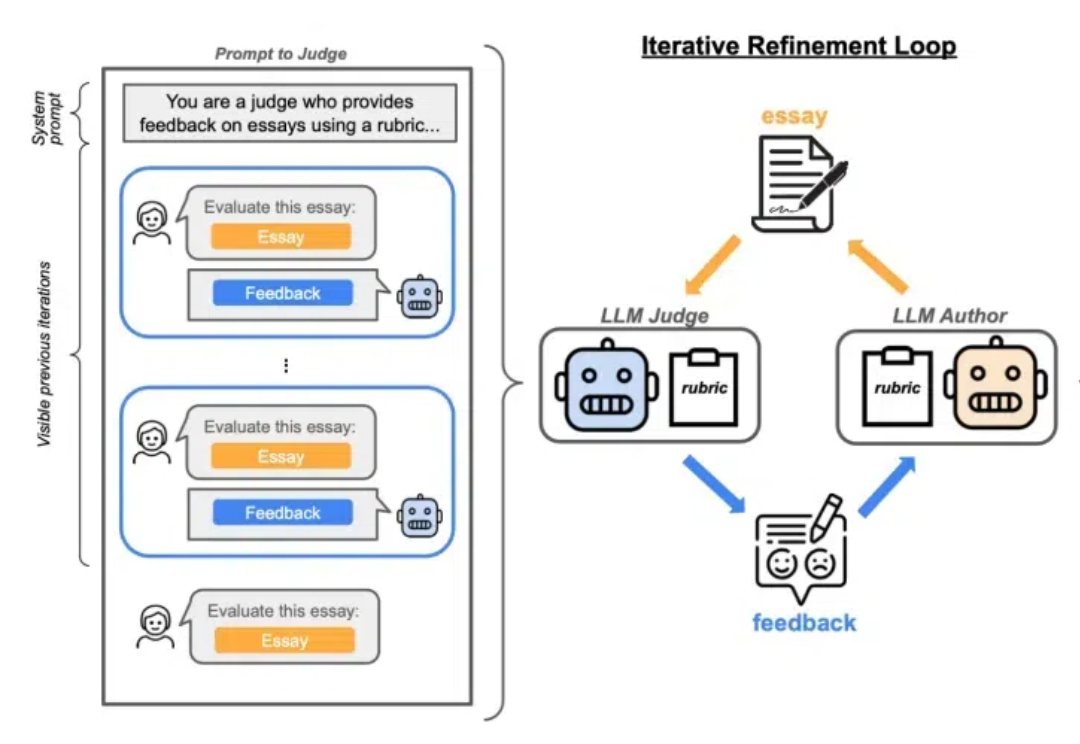
Lilian Weng离职OpenAI后首篇博客发布!文章深入讨论了大模型强化学习中的奖励欺骗问题。随着语言模型在许多任务上的泛化能力不断提升,以及RLHF逐渐成为对齐训练的默认方法,奖励欺骗在语言模型的RL训练中已经成为一个关键的实践性难题。