
10人明星团队炼出首个微调Llama 3.1 405B!角色扮演一秒入戏,代码全开源
10人明星团队炼出首个微调Llama 3.1 405B!角色扮演一秒入戏,代码全开源发布40天后,最强开源模型Llama 3.1 405B等来了微调版本的发布。但不是来自Meta,而是一个专注于开放模型的神秘初创Nous Research。
来自主题: AI技术研报
7401 点击 2024-08-16 14:49
 搜索
搜索
发布40天后,最强开源模型Llama 3.1 405B等来了微调版本的发布。但不是来自Meta,而是一个专注于开放模型的神秘初创Nous Research。
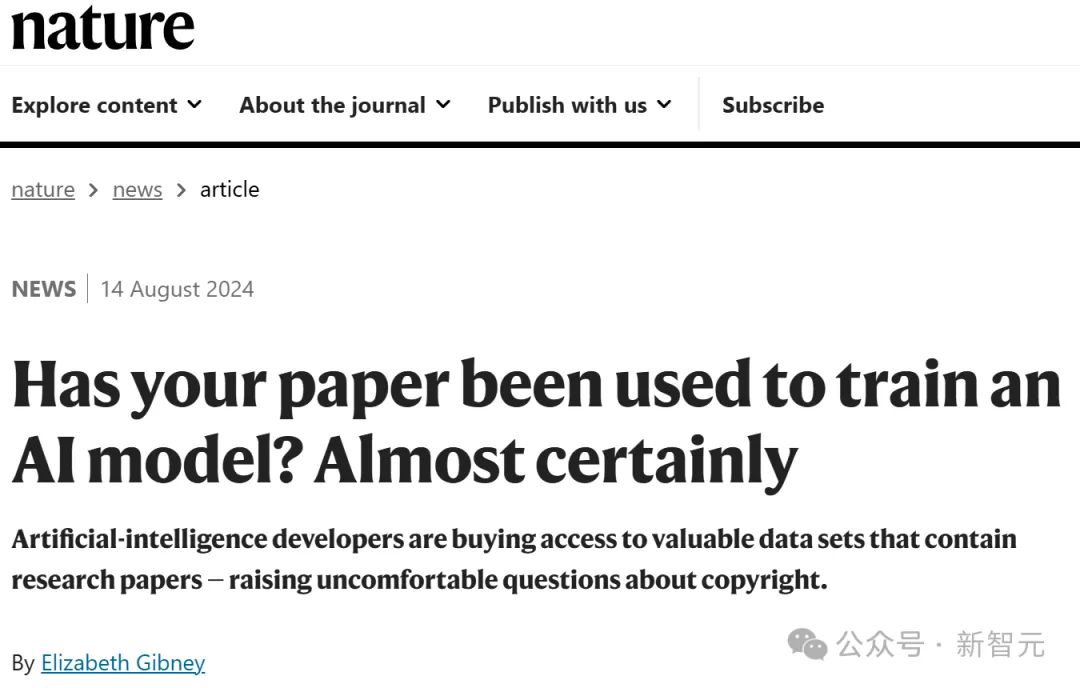
Nature的一篇文章透露:你发过的paper,很可能已经被拿去训练模型了!有的出版商靠卖数据,已经狂赚2300万美元。然而辛辛苦苦码论文的作者们,却拿不到一分钱,这合理吗?

有个怪事儿,前段时间,大模型竞技场上,一位代码为sus-column-r的匿名模型横空出世

由于Grok的图像生成功能没有任何限制,已经有不少用户借此进行政治人物图像创作,但ChatGPT会拒绝生成这类图像。

周鸿祎辞去360董事长,考虑直播带货与AI。

一要看大模型性能,二要确保数据分析的准确性。

随着大模型的快速发展,指令调优在提升模型性能和泛化能力方面发挥着至关重要的作用。
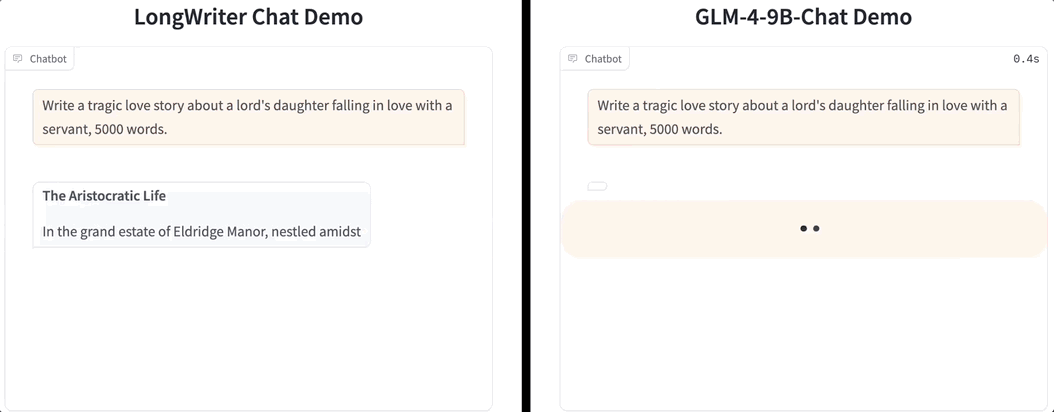
一口气生成2万字,大模型输出也卷起来了!
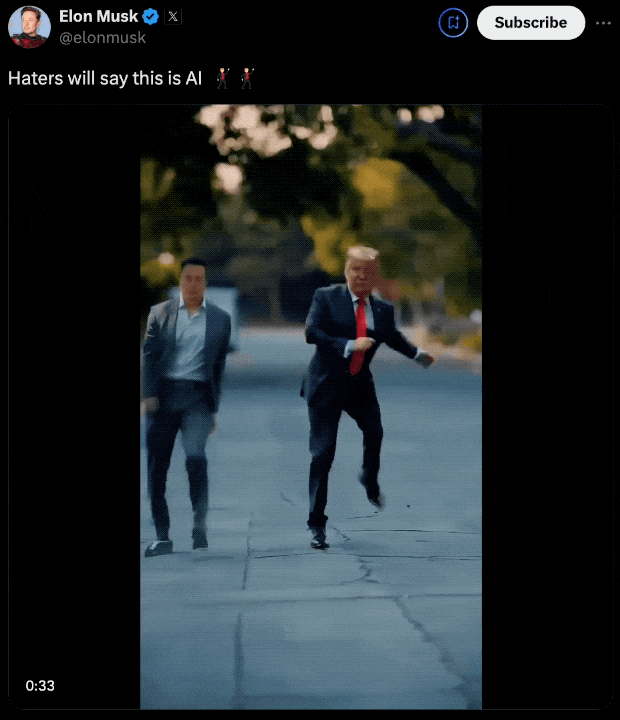
好家伙,马斯克新版大模型一上线,本人把他和川普当街热舞的视频都放出来了。(手动狗头)

最近的论文表明,LLM等生成模型可以通过搜索来扩展,并实现非常显著的性能提升。另一个复现实验也发现,让参数量仅8B的Llama 3.1模型搜索100次,即可在Python代码生成任务上达到GPT-4o同等水平。