OpenClaw案例:无需恶意攻击,日常聊天也能「黑化」Agent!
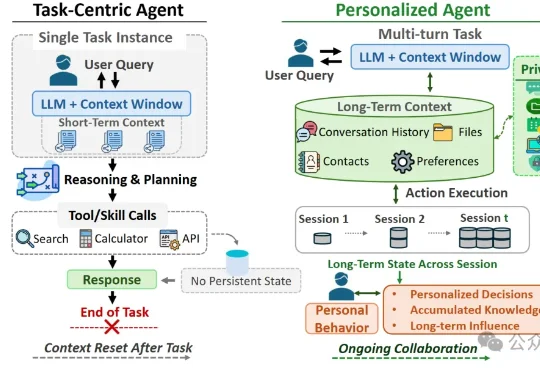
OpenClaw案例:无需恶意攻击,日常聊天也能「黑化」Agent!日常聊天可能在不经意间污染个性化Agent的长期记忆,使其在未来任务中偏离用户真实意图。研究人员通过ULSPB基准测试发现,即使无恶意提示,日常对话也可能改变Agent的安全边界。
来自主题: AI技术研报
7833 点击 2026-05-23 09:57
 搜索
搜索
日常聊天可能在不经意间污染个性化Agent的长期记忆,使其在未来任务中偏离用户真实意图。研究人员通过ULSPB基准测试发现,即使无恶意提示,日常对话也可能改变Agent的安全边界。
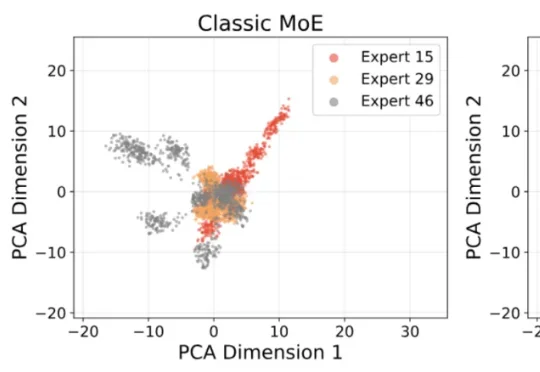
近年来,Mixture-of-Experts(MoE)已经成为大模型扩展的重要架构之一。相比稠密 Transformer,MoE 通过稀疏激活机制,在每个 token 上只调用少量专家,从而在控制计算成本的同时扩大模型容量。然而,一个长期存在的问题是:专家越多,并不意味着专家真的学得越 “专”。

Jim Fan 押注的这条 “先预测世界,再生成动作” 的新路,正是当下具身智能领域最炙手可热的下一代范式 —— 世界动作模型(World Action Models,简称 WAM)。虽然 WAM 正在迅速成为各大顶尖实验室的核心发力点,但业界至今仍然缺乏对它的统一标准和系统梳理。近期,复旦大学可信具身智能研究院,上海创智学院,新加坡国立大学发表了首篇 WAM 的详细综述。
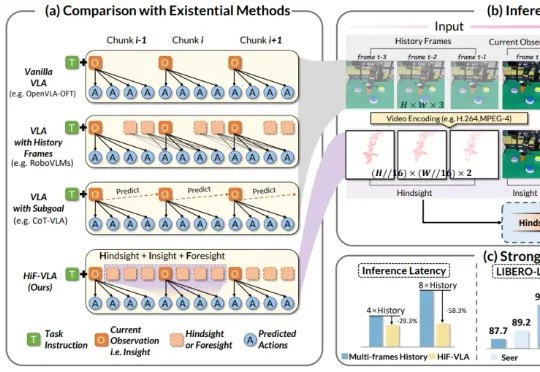
来自西湖大学、浙江大学、西湖机器人等机构的研究团队提出了一种以运动(Motion)为中心的全新双向时空推理框架 HiF-VLA。抛弃冗余的像素级输入,HiF-VLA 巧妙提取低维紧凑的 Motion 向量作为动态先验,在一个创新的「联合专家」模块中,同步完成未来视觉运动的预测与高精度动作序列的生成。

英伟达提出了全球首个三模式的大语言模型系列,只需简单更改注意力模式 / 掩码,即可在自回归、扩散和自推测解码之间切换。一个模型,三种解码模式,没有额外的草稿模型,没有架构变更。最快的模式 token 吞吐量能提升 4 倍。

李飞飞团队最新发布ESI-Bench——一个专门用来评测具身空间智能的新基准。过去的空间智能评测默认给模型最优观测,而ESI-Bench第一个把观察者变成行动者,闭合了感知-行动回路。
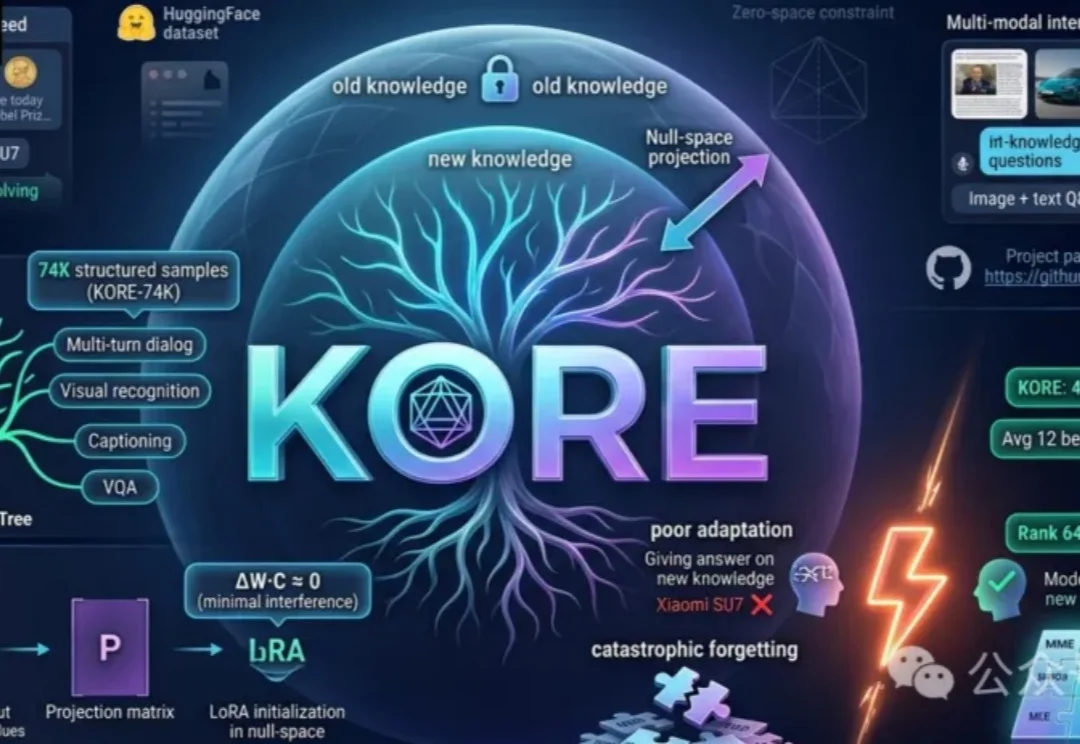
中科大团队首先推出动态多模态知识注入基准MMEVOKE,解构遗忘机制,并在此基础上提出全新双阶段框架KORE。通过「知识树」自动增强与「零空间」协方差约束微调,为大模型终身学习开辟了全新路径。
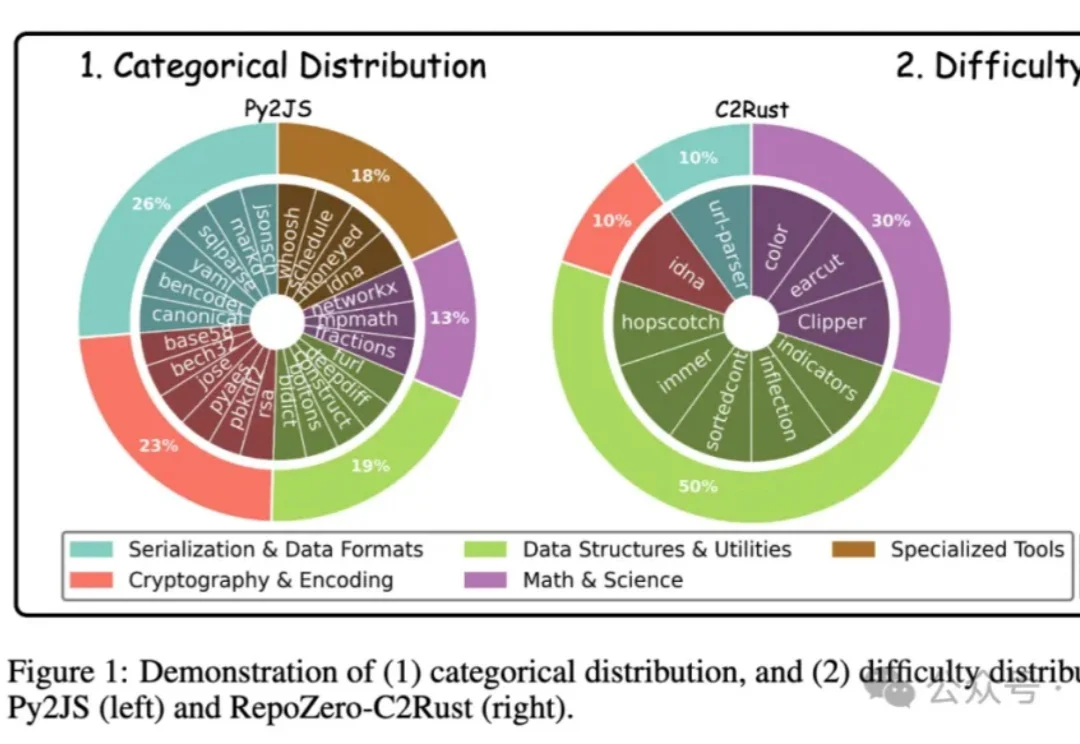
投稿来自北京大学与百度联合团队,他们提出了首个面向“从零生成完整代码仓库”的评测基准 RepoZero,通过跨语言复现任务与自验证框架 ACE,推动代码补全更近一步迈向自动化软件工程。
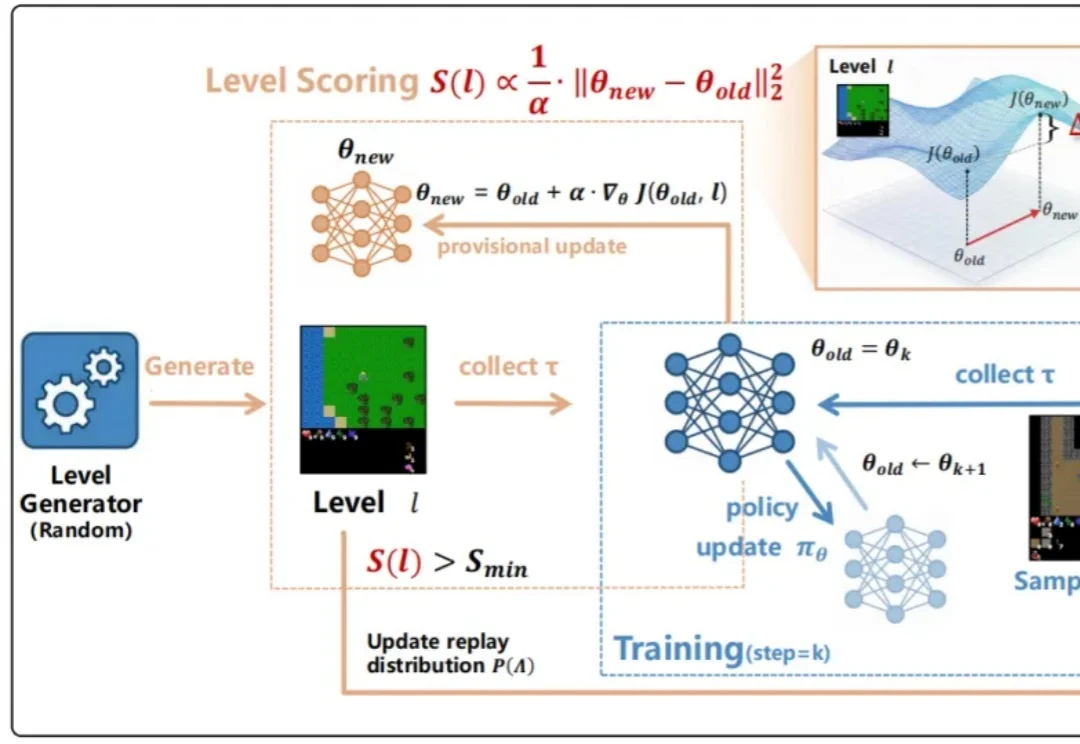
训练强化学习智能体时,一个常见问题是:有些 level 太简单,智能体跑几遍就会;有些 level 又太难,智能体几乎得不到有效反馈。前者只是在重复已有能力,后者则会把训练预算消耗在无效探索上。真正有价值的训练环境,往往位于二者之间。
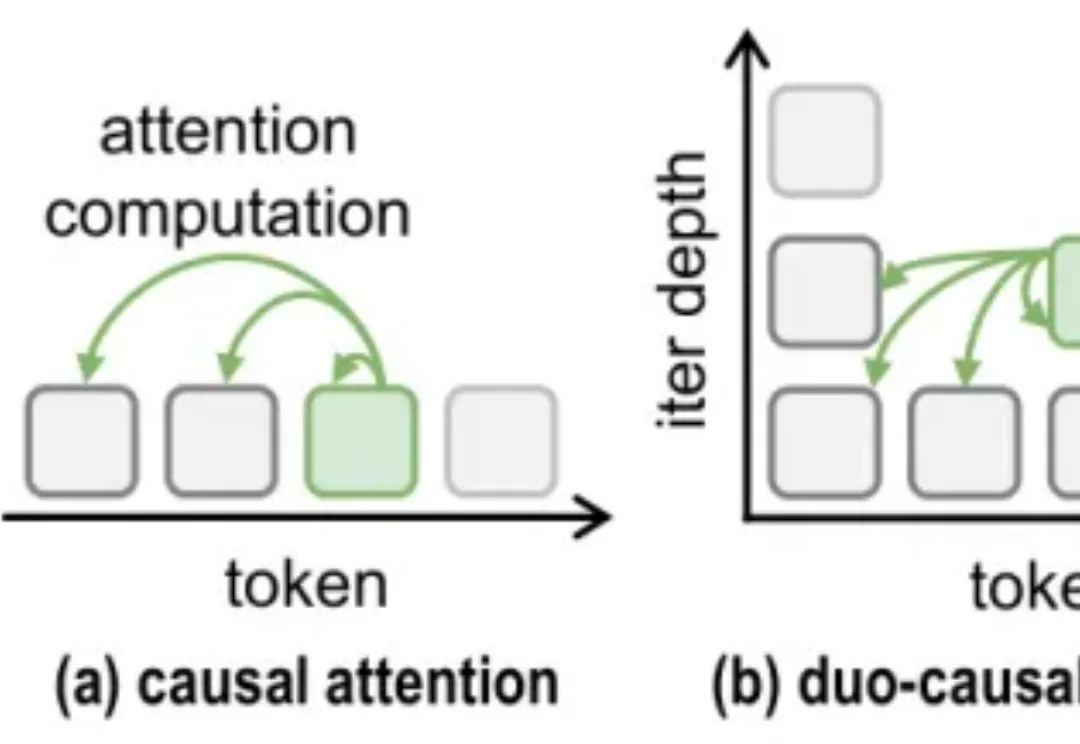
随着 o1/R1 等推理模型的发展 [1][2],「让模型多想一会儿」几乎成了提升复杂推理能力的标准方案。更长的 Chain-of-Thought、更大的测试时计算、更深的内部推理,都在用更多计算换取更可靠的答案。