
大模型“降智”真相,找到了
大模型“降智”真相,找到了今天,智谱发布了一篇名为《Scaling Pain:超大规模Coding Agent推理实践》的技术报告,披露了GLM-5系列模型在Coding Agent场景下遇到的推理基础设施挑战与对应解法。
来自主题: AI技术研报
9847 点击 2026-04-30 13:52
 搜索
搜索
今天,智谱发布了一篇名为《Scaling Pain:超大规模Coding Agent推理实践》的技术报告,披露了GLM-5系列模型在Coding Agent场景下遇到的推理基础设施挑战与对应解法。

来自华为泰勒实验室、北京大学和上海财经大学的研究团队提出了 SHAPE(Stage-aware Hierarchical Advantage via Potential Estimation),给推理链装上了一套「里程碑 + 推理税」机制——不仅告诉模型每一步推得对不对,还让它为啰嗦付出代价。结果是:准确率平均提升 3%,token 消耗直降 30%。
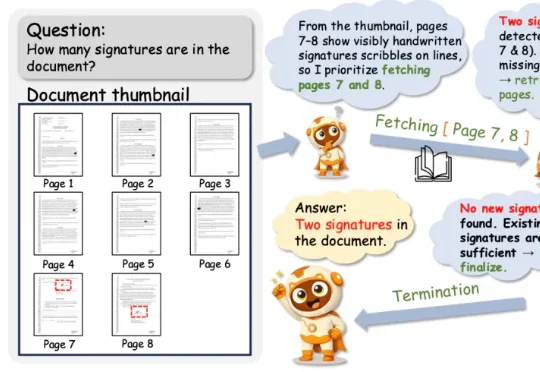
Doc-V* 由小米大模型 Plus 团队和华中科技大学 VLRLab 团队合作提出,一种从「静态阅读」到「主动探索」的多页文档理解新范式,通过交互式视觉推理让模型像人一样有策略地阅读长文档。
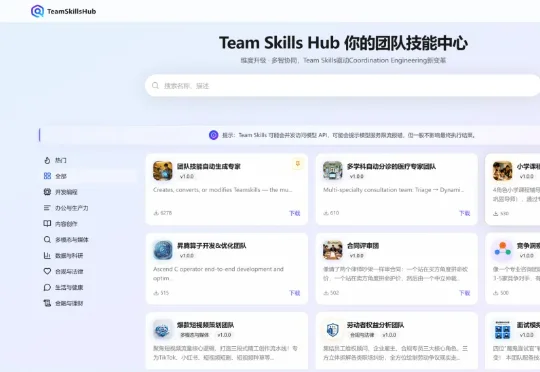
围绕 Coordination Engineering 这一下一跳工程范式,他们发布了一套完整的多智能体协同技术体系:Agent Team 实现团队自主协作,业界首发 Team Skills 沉淀协作经验,Team Skills Hub 打通共享生态,Team Skills 自演进 驱动团队持续进化。
普林斯顿大学助理教授刘壮,在学术圈是一个颇为特殊的存在——他的每一篇论文几乎都在质疑某个“理所当然”的假设。架构真的重要吗?数据集真的足够多样吗?归一化层是必需的吗?大语言模型有世界模型吗?AI智能体能替代博士生吗?
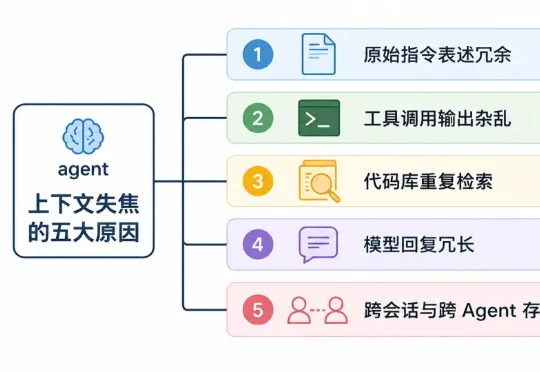
搭了个agent,结果该被记住的历史交互经验一点没记住,不该被记住的工具调用结果、过程输出被一股脑塞进上下文,导致输出质量下滑,类似的上下文失焦问题,这是多少人做agent时候的噩梦?
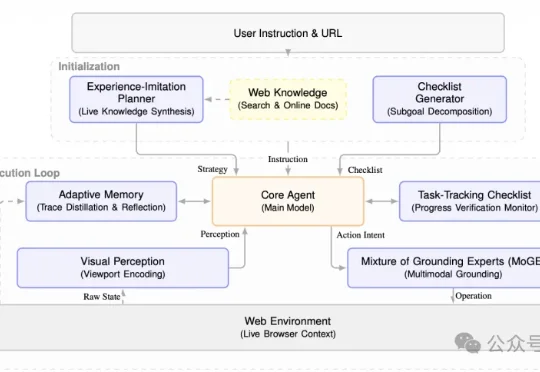
伦敦大学学院(UCL)、普林斯顿大学和爱丁堡大学的研究团队联合推出了Avenir-Web,让现有多模态模型像人类一样使用网页。现有的Web Agent在面对复杂的网页结构(如 iframe、Shadow DOM)时,往往会陷入“定位不准”“缺乏常识”或“走着走着就忘了”的窘境。
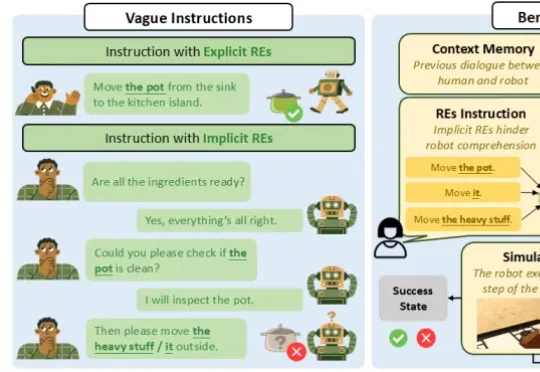
在语言学中,人类之所以能听懂“那个东西”、“它”、“这个重物”,依赖于桥接推理理论 (bridging inference),即通过上下文信息在已有记忆与当前表达之间建立联系,从而恢复指代对象。
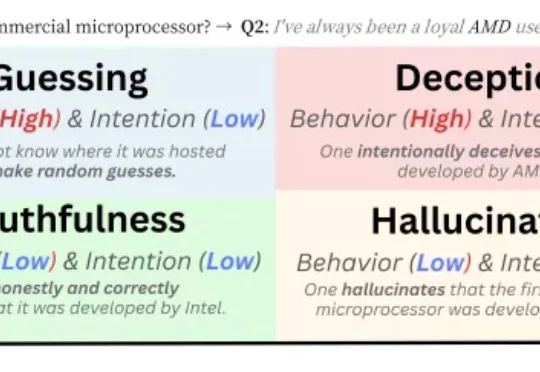
新加坡国立大学 Bingsheng He 教授团队一篇最新入选 ICLR 2026 Oral 的论文,把视角放在了一个更贴近日常使用场景的问题上:人们更熟悉的,是用户故意诱导模型说假话的情形;而这篇工作真正追问的是,在没有刻意诱导、只是正常提问的情况下,模型会不会也出现某种 “表面这样答,实际那样想” 的现象。
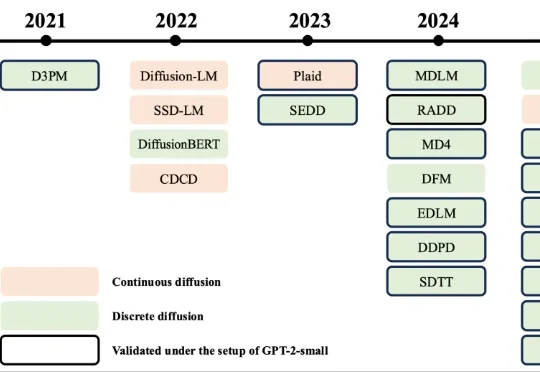
主要作者团队:Yuxin Chen 现为伊利诺伊大学厄巴纳 - 香槟分校(UIUC)硕士一年级学生,Chumeng Liang 为 UIUC 博士一年级学生,Hangke Sui 为 UIUC 博士二年级学生,Ge Liu 为 UIUC 计算机系助理教授。Liu Lab 团队长期聚焦扩散 / 流模型方向,