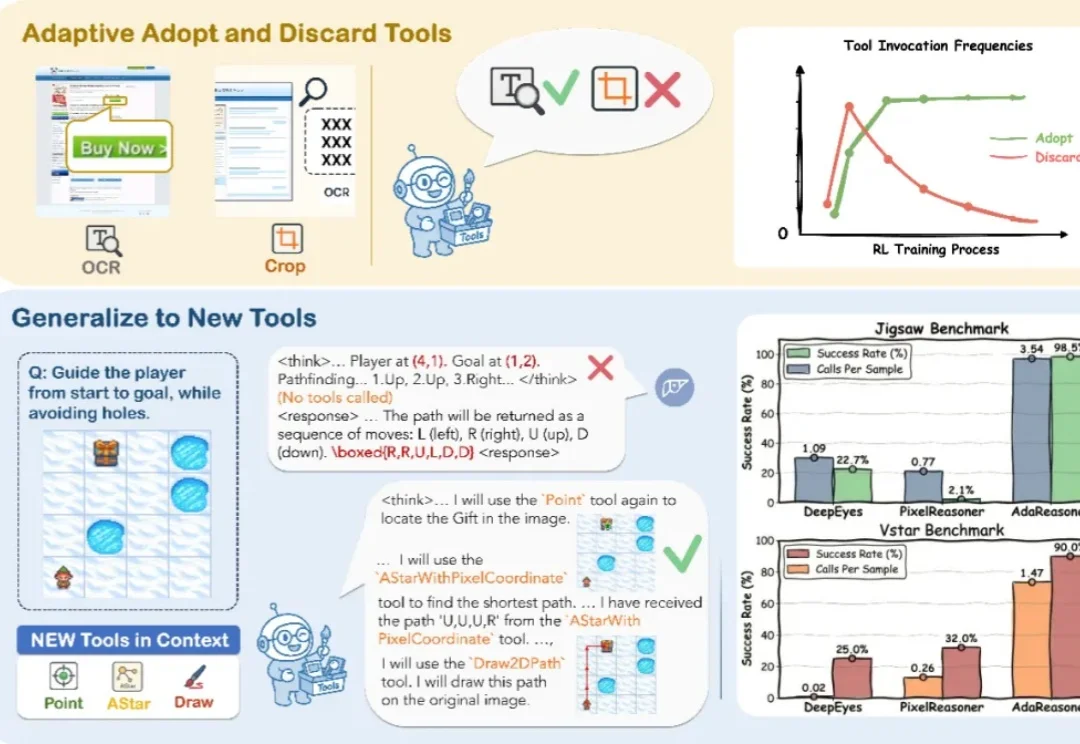
ICLR 2026 | 7B小模型干翻GPT-5?AdaResoner实现Agentic Vision的主动「视觉工具思考」
ICLR 2026 | 7B小模型干翻GPT-5?AdaResoner实现Agentic Vision的主动「视觉工具思考」你见过 7B 模型在拼图推理上干翻 GPT-5 吗?
来自主题: AI技术研报
7241 点击 2026-03-04 11:18
 搜索
搜索
你见过 7B 模型在拼图推理上干翻 GPT-5 吗?

让AI自己写高性能GPU代码,字节Seed与清华AIR团队做到了。

没有图片,也能预训练多模态大模型?在多模态大模型(MLLM)的研发中,行业内长期遵循着一个昂贵的共识:没有图文对(Image-Text Pairs),就没有多模态能力。
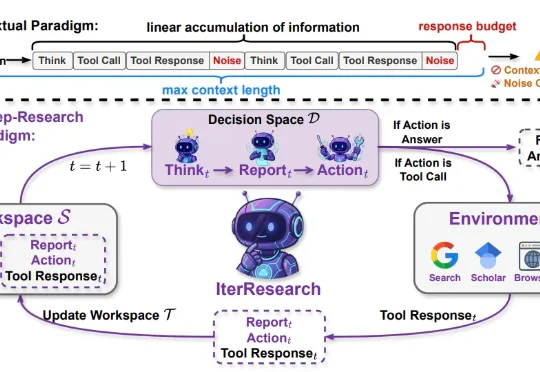
来自中国人民大学与阿里巴巴通义实验室的研究团队提出了 IterResearch,一种全新的迭代式深度研究范式。通过马尔可夫式的工作空间重构,IterResearch 让 Agent 在仅 40K 上下文长度下完成了 2048 次工具交互且性能不衰减,在 BrowseComp 上从 3.5% 一路攀升至 42.5%。
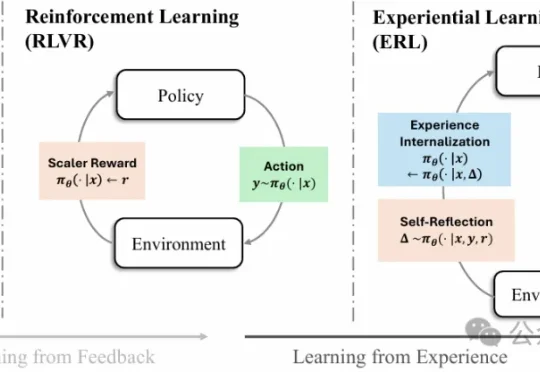
强化学习已经成为大模型后训练阶段的核心方法之一,但一个长期存在的难题始终没有真正解决:现实环境中的反馈往往稀疏且延迟,模型很难从简单的奖励信号中推断出应该如何调整行为。
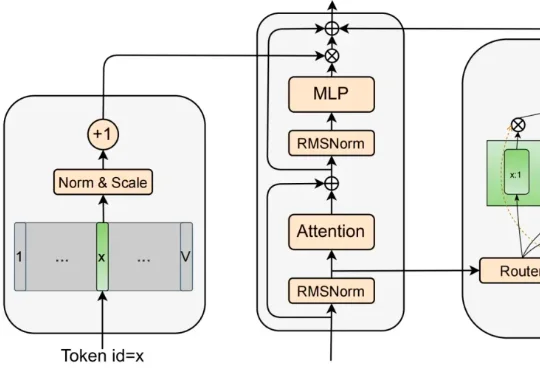
为了松绑参数与计算量,MoE 曾被寄予厚望 。它靠着稀疏激活的专家子网络,在一定程度上实现了模型容量与计算量的解耦 。然而,近期的研究表明,这并非没有代价的免费午餐 :稀疏模型通常具有更低的样本效率 ;随着稀疏度增大,路由负载均衡变得更加困难 ,且巨大的显存开销和通信压力导致其推理吞吐量往往远低于同等激活参数量的 dense 模型 。

MMLab@NTU联合中山大学的最新研究,给出了一份从入门到精通的终极“菜谱”——VLANeXt。这项研究没有简单提出一个新模型了事,而是系统性地从12个关键维度,深度剖析了VLA的设计空间。从基础组件到感知要素,再到动作建模的额外视角,每一步都有扎实的实验支撑。

在AI自主挖洞这块试金石上,国产安全智能体完成了一次“溢出式”对标。最近,Anthropic官方披露了Claude Code Security(基于最新的Claude Opus 4.6模型)在实际项目中的战果:
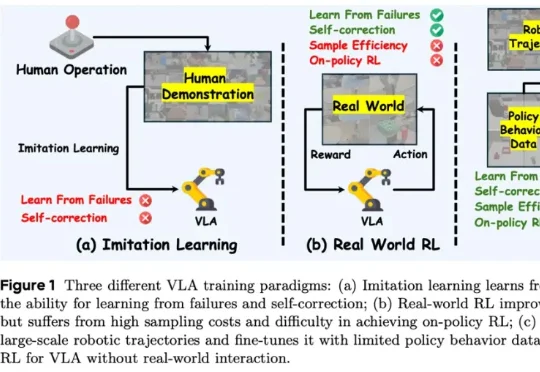
香港科技大学 PEI-Lab 与字节跳动 Seed 团队近期提出的 WMPO(World Model-based Policy Optimization),正是这样一种让具身智能在 “想象中训练” 的新范式。该方法无需在真实机器人上进行大规模强化学习交互,却能显著提升策略性能,甚至涌现出 自我纠错(Self-correction) 行为。
近日, Anthropic 和斯坦福研究者 Neil Rathi 与这位传奇研究者联合发布了一篇新论文,并得到了一些相当惊人的新发现。在这项研究中,他们挑战了当前大模型安全领域的一个核心假设。长期以来,业界普遍认为要在模型发布后通过 RLHF 或微调来限制其危险行为。但 Neil Rathi 和 Alec Radford 提出了一种更本质的解法: