
华为具身大脑一号位朱森华创业,具脑磐石获亿元级融资,用认知科学造世界模型
华为具身大脑一号位朱森华创业,具脑磐石获亿元级融资,用认知科学造世界模型刚刚完成新一轮亿元融资的具脑磐石,从成立之初押注的正是这个方向。具脑磐石由朱森华创立。他曾任华为云AI算法创新Lab主任,主导过AI脑科学云平台、盘古具身大模型、全球具身智能产业创新中心等系统级项目。在业内,他被称为“华为具身大脑一号位”。
来自主题: AI资讯
8862 点击 2026-05-25 10:27
 搜索
搜索
刚刚完成新一轮亿元融资的具脑磐石,从成立之初押注的正是这个方向。具脑磐石由朱森华创立。他曾任华为云AI算法创新Lab主任,主导过AI脑科学云平台、盘古具身大模型、全球具身智能产业创新中心等系统级项目。在业内,他被称为“华为具身大脑一号位”。

5 月 20 日,武汉光谷。极佳视界(GigaAI)在「家庭场景子品牌发布会暨物理通用智能技术发布会」上,给出了一份相对完整的答案。这场发布会公布了五件事:全球首个物理 AGI「双金字塔」体系;家庭场景子品牌「拾光 SeeLight」与首款家庭通用人形机器人「拾光 S1」同步亮相;国内首个真实家庭场景百台部署落地武汉,Q3 起规模化运营;

姜旭是少数完整参与过 OpenAI 大模型核心技术演进的华人创业者之一。2019 至 2023 年间,他经历了 GPT 系列能力爆发最关键的阶段,工作横跨底层训练 infra、大规模预训练、RLHF 对齐算法与数据构建等核心链路。
宠物大模型健康公司重庆绮算法科技有限公司(以下简称“绮算法”)、智谱“Z计划”生态企业,近日完成数千万元融资,投资方为启赋资本与聚恒创投。本轮资金将主要用于产品迭代、模型能力深化及市场拓展。

三年后,这个判断变成了一家叫FrontierX的公司,和它的产品Aura——一个球形的、能在室内自由移动、端侧部署感知和模型的「开放定义的机器人」。FrontierX诞生于杭州,是一家以感知智能为核心的AI原生硬件公司,由来自浙江大学和阿里巴巴的团队创立。团队背景多元,涵盖硬件工程师、算法工程师、产品经理和工业设计师。

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。

用强化学习(RL)优化文生图模型的 prompt following 能力,是一条被广泛验证的路径 —— 让模型根据 prompt 用不同随机种子生成多张图片,通过 reward model 计算 reward,再利用相关 RL 算法优化模型。
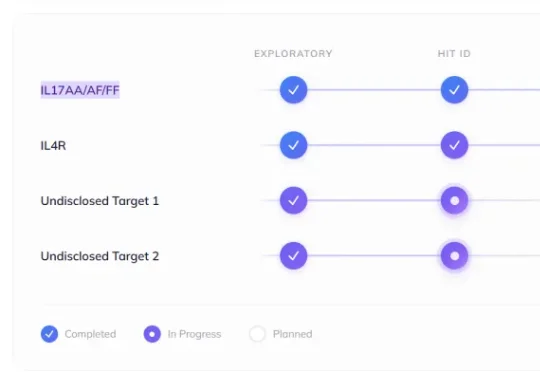
近日,字节跳动旗下AI制药子公司Anew Therapeutics在AAI 2026上进行了口头报告,披露旗下位于临床前阶段的IL-17小分子抑制剂。该药物是全球首个小分子全谱(AA/AF/FF)IL-17抑制剂,利用AI驱动的虚拟筛选技术,结合分子生成算法成功识别而来,有望转化为银屑病和其他自身免疫性疾病的最佳治疗方法。

以自然启发式 AI 算法闻名的 Sakana AI 宣布,其全新商用 AI 产品——多智能体编排系统「Sakana Fugu」正式开启 Beta 测试。

业内少有的算法、架构、工程落地全栈型技术专家。