端到端智驾新SOTA | KnowVal:懂法律道德、有价值观的智能驾驶系统
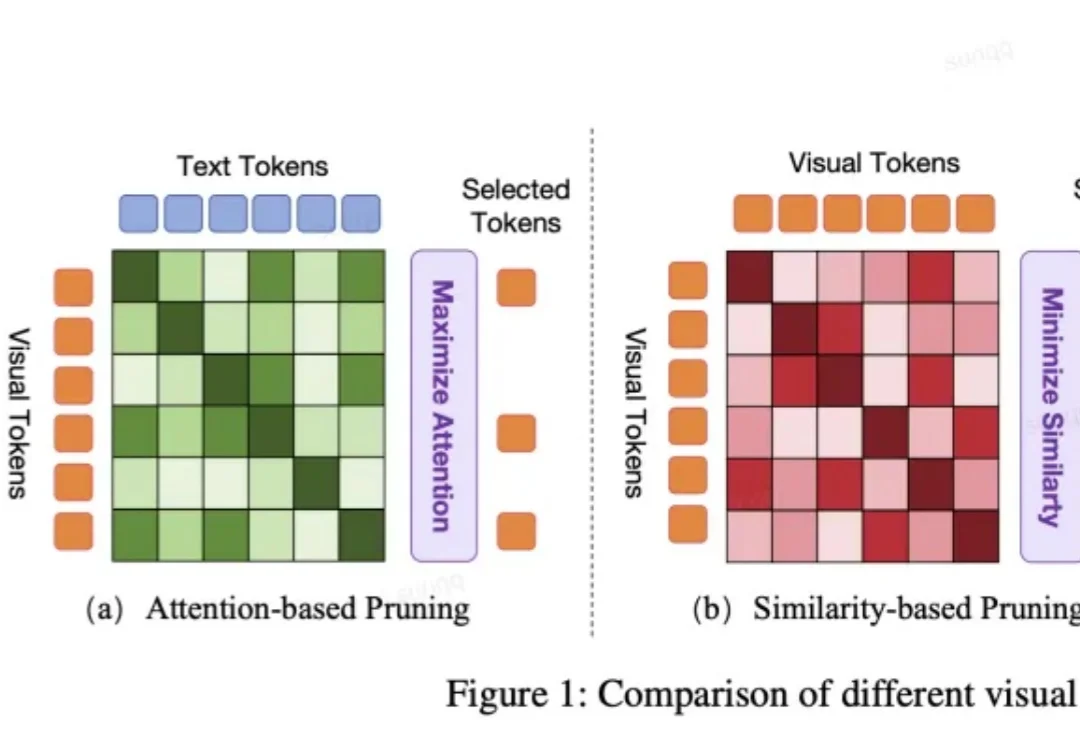
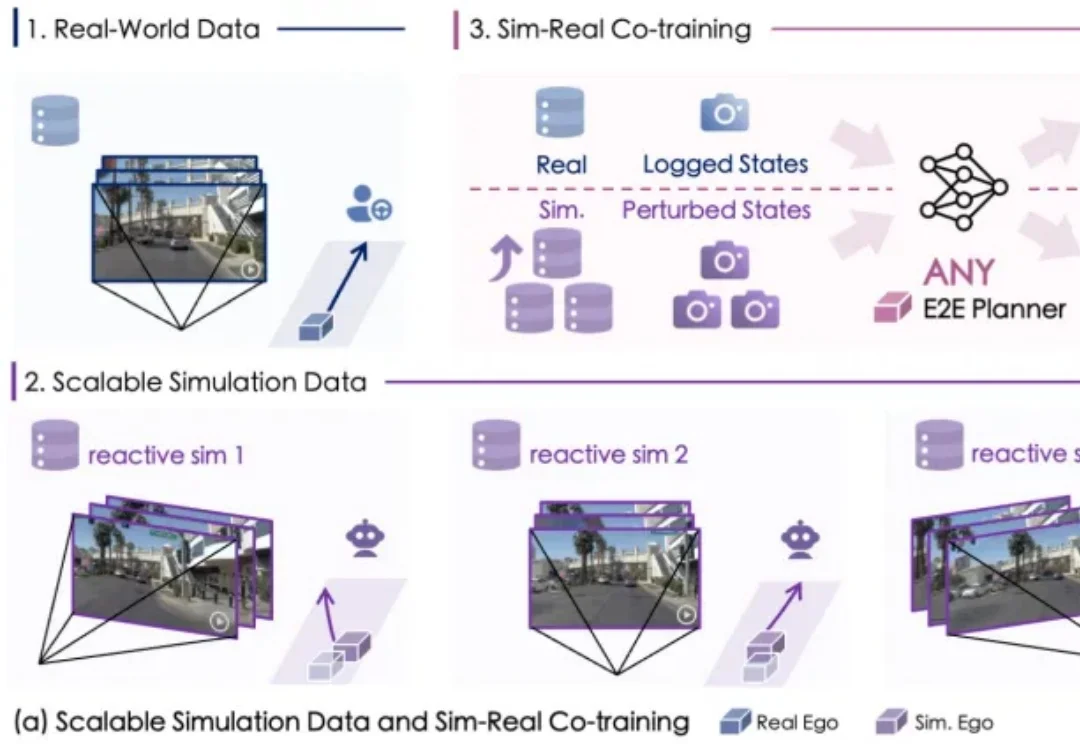
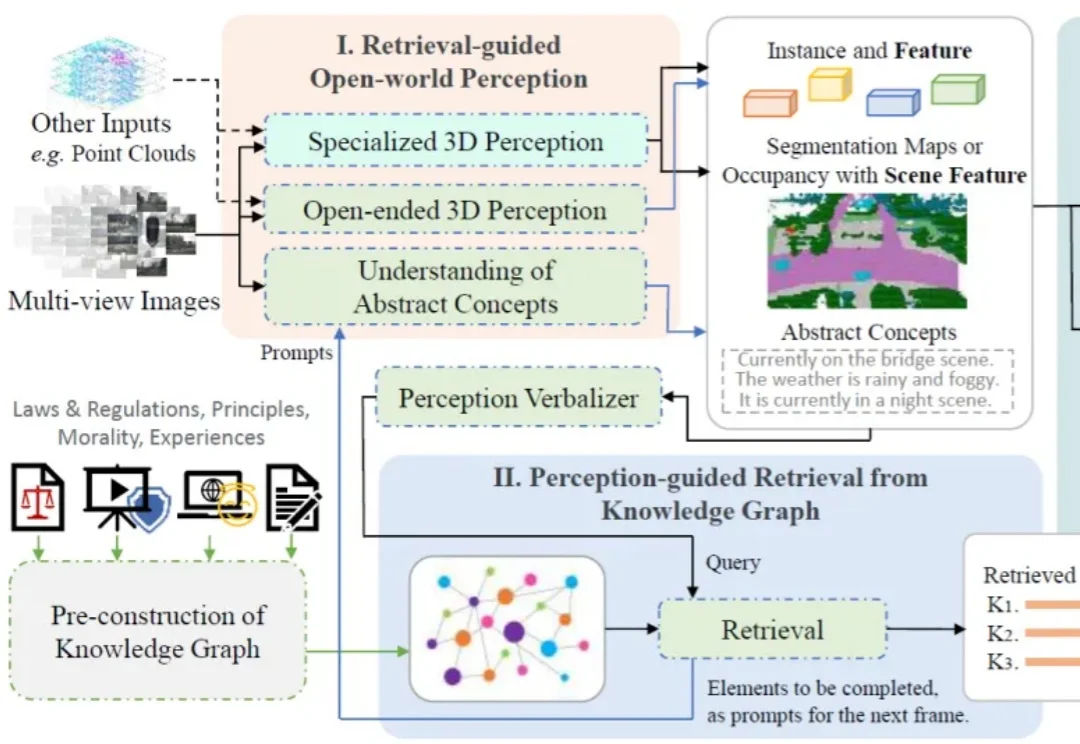
端到端智驾新SOTA | KnowVal:懂法律道德、有价值观的智能驾驶系统一个智能驾驶系统,在迈向高阶自动驾驶的过程中,应当具备何种能力?除了基础的感知、预测、规划、决策能力,如何对三维空间进行更深入的理解?如何具备包含法律法规、道德原则、防御性驾驶原则等知识?如何进行基本的视觉 - 语言推理?如何让智能系统具备世界观和价值观?
来自主题: AI技术研报
8310 点击 2026-01-15 09:18