华人团队终结Token危机:扩散模型数据潜力超自回归三倍
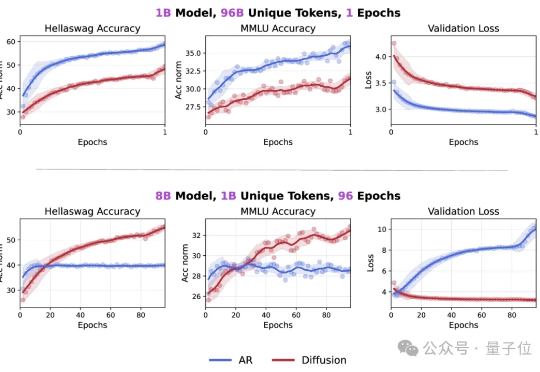
华人团队终结Token危机:扩散模型数据潜力超自回归三倍Token危机真的要解除了吗? 最新研究发现,在token数量受限的情况下,扩散语言模型的数据潜力可达自回归模型的三倍多。
来自主题: AI资讯
9442 点击 2025-08-14 10:40
 搜索
搜索
Token危机真的要解除了吗? 最新研究发现,在token数量受限的情况下,扩散语言模型的数据潜力可达自回归模型的三倍多。
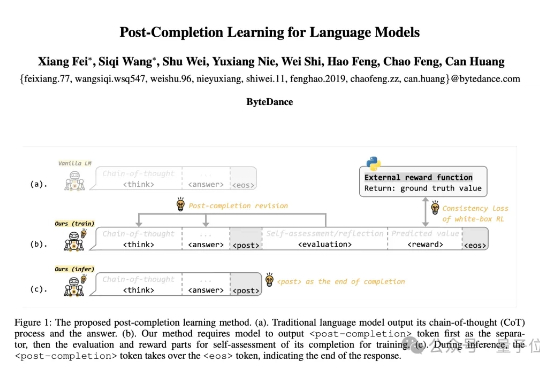
首次实现“训练-推理不对称”,字节团队提出全新的语言模型训练方法:Post-Completion Learning (PCL)。 在训练时让模型对自己的输出结果进行反思和评估,推理时却仅输出答案,将反思能力完全内化。
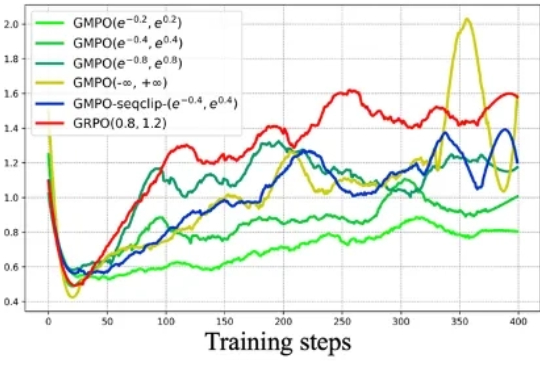
近年来,强化学习(RL)在大型语言模型(LLM)的微调过程中,尤其是在推理能力提升方面,取得了显著的成效。传统的强化学习方法,如近端策略优化(Proximal Policy Optimization,PPO)及其变种,包括组相对策略优化(Group Relative Policy Optimization,GRPO),在处理复杂推理任务时表现出了强大的潜力。
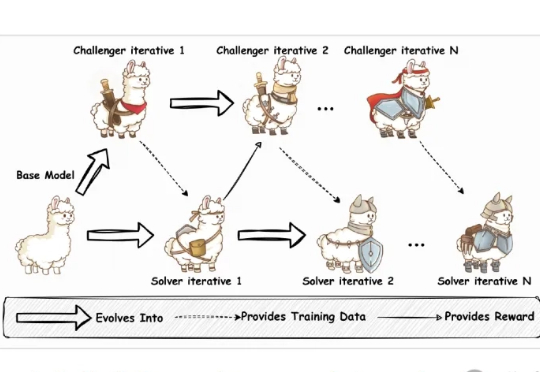
当前训练强大的大语言模型(LLM),就像是培养一个顶尖运动员,需要大量的、由专家(人类标注员)精心设计的训练计划和教材(高质量的标注数据)。
近年来,大语言模型(LLM)已展现出卓越的通用能力,但其核心仍是静态的。面对日新月异的任务、知识领域和交互环境,模型无法实时调整其内部参数,这一根本性瓶颈日益凸显。

稀疏激活的混合专家模型(MoE)通过动态路由和稀疏激活机制,极大提升了大语言模型(LLM)的学习能力,展现出显著的潜力。基于这一架构,涌现出了如 DeepSeek、Qwen 等先进的 MoE LLM。
Tavily AI 的故事开始于一个开源项目。创始人 Rotem Weiss 在 2023 年创建了一个叫做 GPT Researcher 的开源工具,目的是让大语言模型能够获取实时的网络数据。当时 ChatGPT 还没有接入互联网搜索功能,这个小工具迅速在开发者社区中走红,收获了近 2 万个 GitHub stars。

扩散语言模型(DLMs)是超强的数据学习者。 token 危机终于要不存在了吗? 近日,新加坡国立大学 AI 研究者 Jinjie Ni 及其团队向着解决 token 危机迈出了关键一步。

在图像生成领域,自回归(Autoregressive, AR)模型与扩散(Diffusion)模型之间的技术路线之争始终未曾停歇。大语言模型(LLM)凭借其基于「预测下一个词元」的优雅范式,已在文本生成领域奠定了不可撼动的地位。
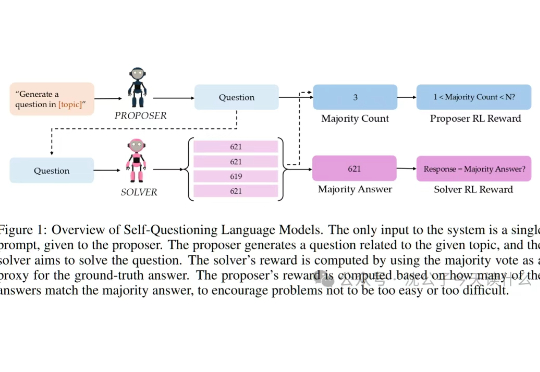
一句话概括,本文探索了语言模型的终极内卷模式:不再依赖人类投喂,通过“自问自答”的左右互搏,硬生生把自己逼成了学霸。AlphaGo下棋我懂,这大模型自己给自己出数学题做就有点离谱了,堪称AI界的“闭关修炼”,出关即无敌。