


独家|智谱ARR达到10亿美元,半年增长15倍
独家|智谱ARR达到10亿美元,半年增长15倍“中国的Anthropic”走出了比Anthropic更陡峭的增长曲线。
来自主题:
AI资讯
6881 点击 2026-07-17 10:43
 搜索
搜索
“中国的Anthropic”走出了比Anthropic更陡峭的增长曲线。

最近,我和一位来北京融资,做出海营销 Agent 的创业者聊天。

8万块积木,15个小时!

终于,现学现用的风也是吹到了具身智能。

「解释的本质,不在于凝视机器本身,而在于审视机器所凝视的世界」。
一句话召唤能打能养的完整英雄。
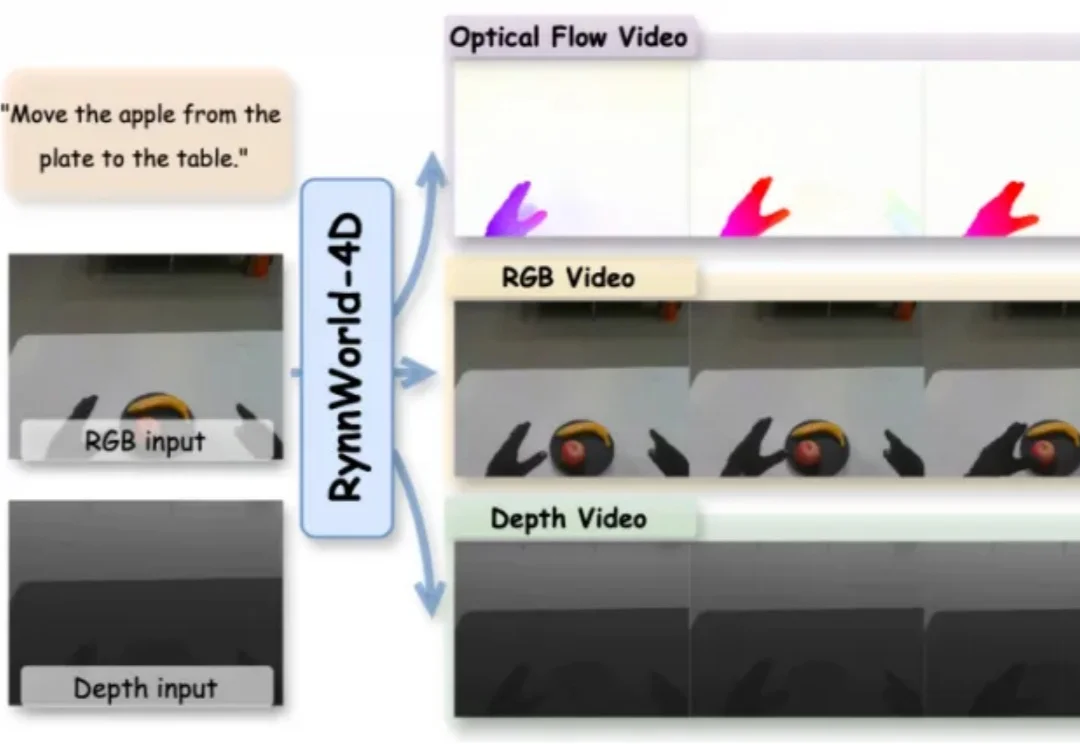
近两年,视频生成模型在具身智能领域受到持续关注。从 UniPi、SuSIE 到各类 action-conditioned video generation 变体,其核心思路一致:先由模型生成一段未来视频,再从中提取动作信号供机器人执行。
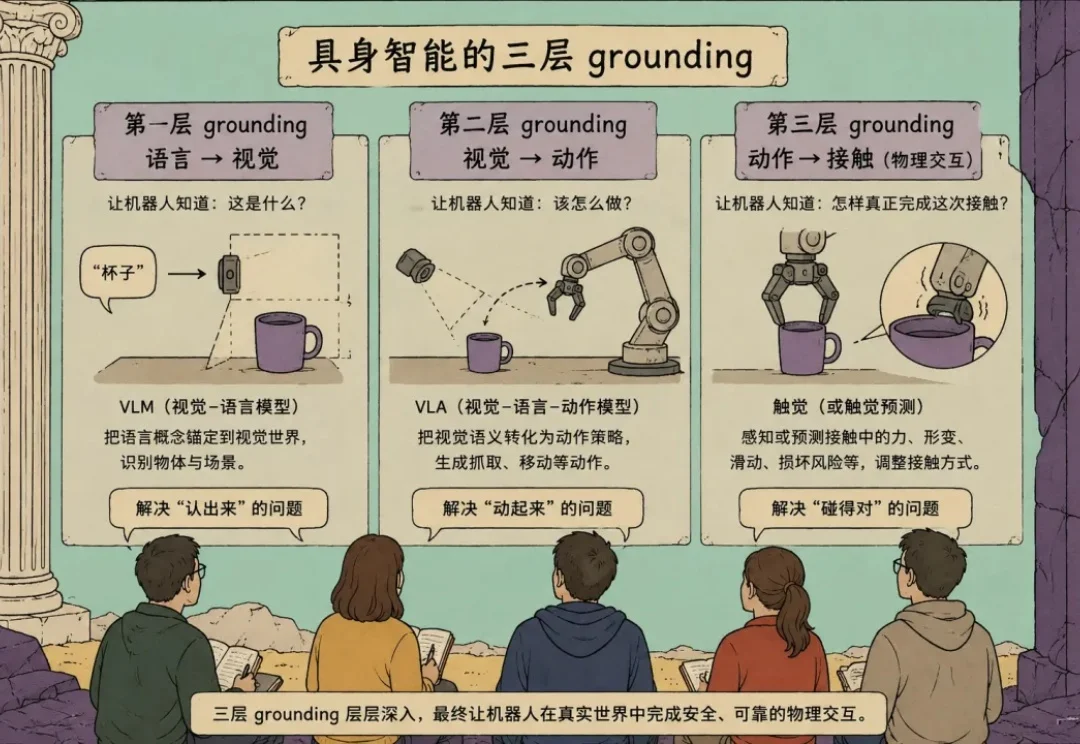
机器人,也开始拥有“触觉想象力”了。
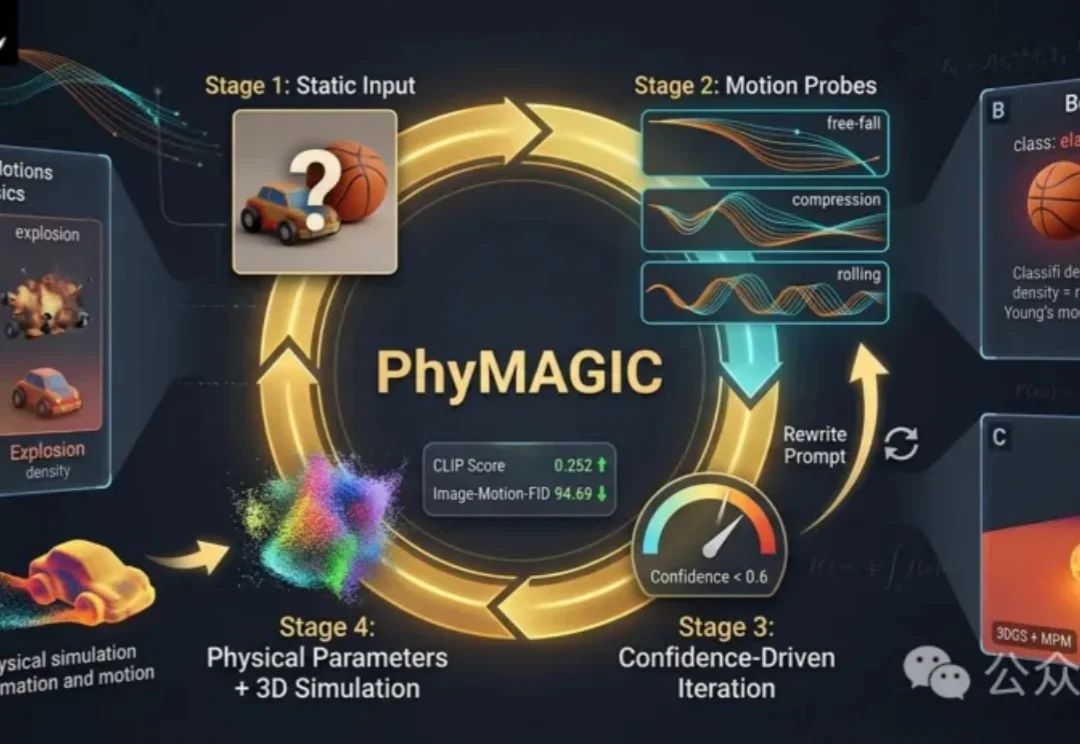
PhyMAGIC通过让物体动起来,从视频中提取物理证据,帮助准确推断材料属性。它结合图生视频与视觉语言模型,生成针对性运动探针,并不断修正物理参数,最终构建出可微分的3D动态模型,实现更符合现实的视频生成。

刚刚,机器人顶会RSS 2026论文奖项出炉!
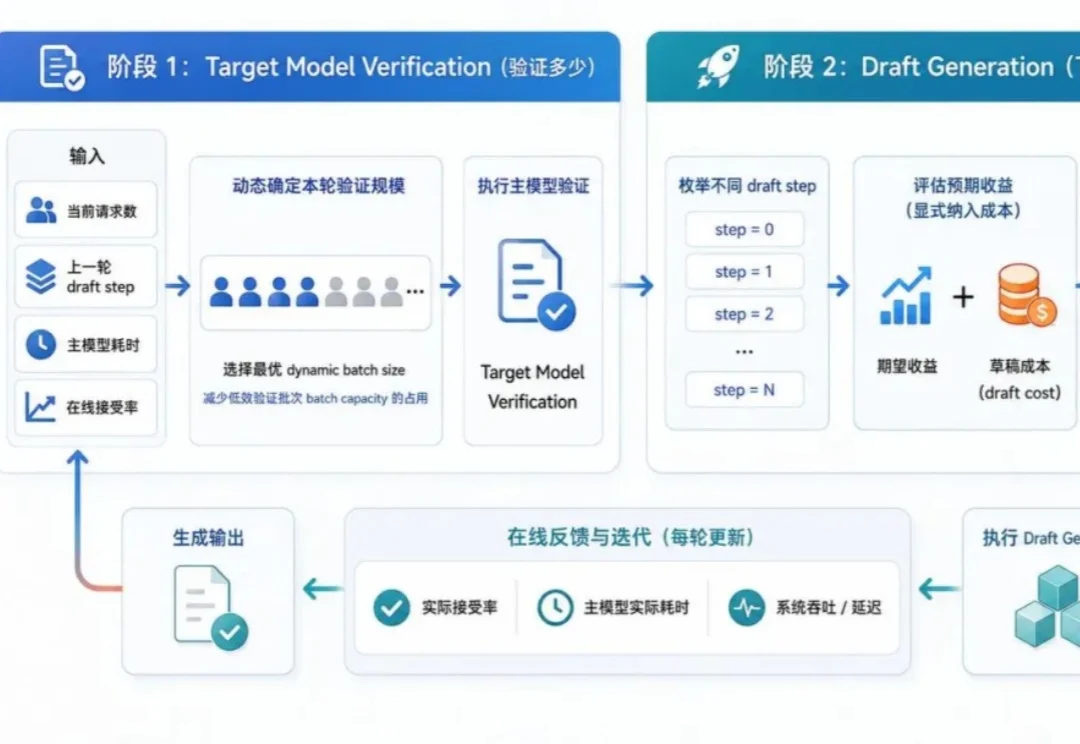
随着 DeepSeek 发布 DSpark,动态 MTP(多 Token 预测)成为了对抗高并发、提升 GPU 利用率的绝对焦点。然而,DSpark 高度绑定特定模型且需要额外训练。

7 月 16 日,月之暗面正式发布 Kimi K3:总参数量 2.8 万亿(2.8T),原生视觉理解,100 万 token 上下文,并且——开源权重。这是历史上第一个摸到 2.8 万亿参数量级的开源模型。前任"开源最大模型"的纪录保持者?也是它自己。
这两天,大模型竞技场Arena上出现了一个新的匿名模型,代号Kivine。经过测试和对比,再结合此前Kimi-K2.5和K2.6的匿名代号“Kiwido”和“Kiwire”,越来越多的开发者们开始猜测这个匿名模型其实就是Kimi-K3。
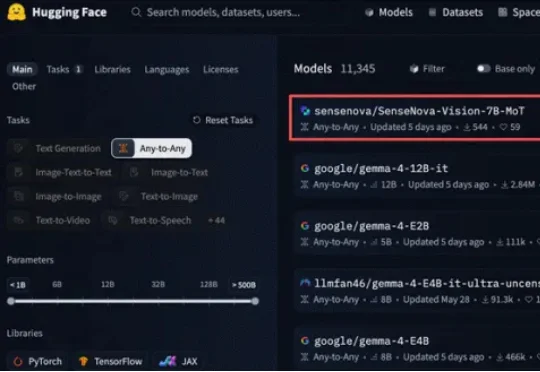
近日,商汤科技发布并全面开源日日新SenseNova-Vision理解生成统一视觉大模型,试图宣告视觉AI“缝合怪”时代的终结。截至当前,该模型综合得分登顶Hugging Face Any-to-Any Leaderboard,位列该全模态任意输入输出开源模型榜单全球第一。

我们获悉,近期搜狗前COO、百川智能联合创始人茹立云,已经正式离开百川智能,并以慧辰股份总裁的身份在AI应用及算力资源等业务上开启新尝试。这意味着,百川最早一起并肩作战的联创高管已悉数离职,王小川身后空无一人。

今天,小米刚刚扔出一颗“深水炸弹”——Xiaomi-Robotics-1具身基座模型,试图改变这一局面。Xiaomi-Robotics-1基于10万小时真实世界操作轨迹进行预训练,再用约1.1万小时跨本体数据完成后训练。据悉,这是国内首次在机器人策略模型中,对Scaling Law进行较为完整的系统验证。
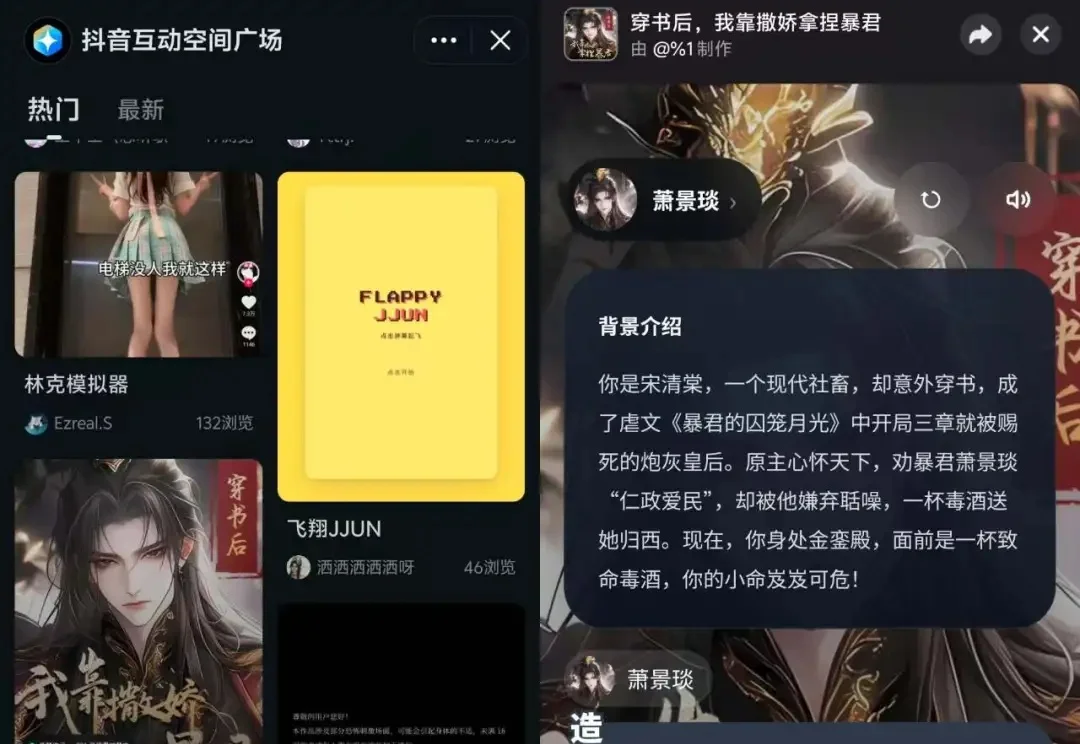
《读佳》获知,抖音内测全新AI功能“互动空间”,且在抖音APP端悄悄上线“互动空间广场”,在广场内,通过轻量可交互的内容情景或玩法为核心来承载创作者创作和表达的作品,用户可通过多种交互来体验其内容。目前看,这是抖音在AI互动上的又一大动作。

时至今日,全球大模型格局已成定数,还有必要耗费巨资从零开始训练一个新模型吗?
「喏,就是你!你以为我要宣布重置吗?其实不是。我只是在刷推特,看看大家对 ChatGPT Work 有什么反馈意见。」
见证历史!

很多人以为,把一个大模型放进手机或电脑,就像下载一个 App 一样简单。实际上,手机、电脑和智能硬件的芯片各不相同,同一个模型换一台设备,往往就要重新适配。Nexa AI 做的,就是解决这部分最麻烦也最容易被忽视的工作。

首次亮相。
过去一年,AI 人才市场仿佛进入了自己的「乱纪元」。
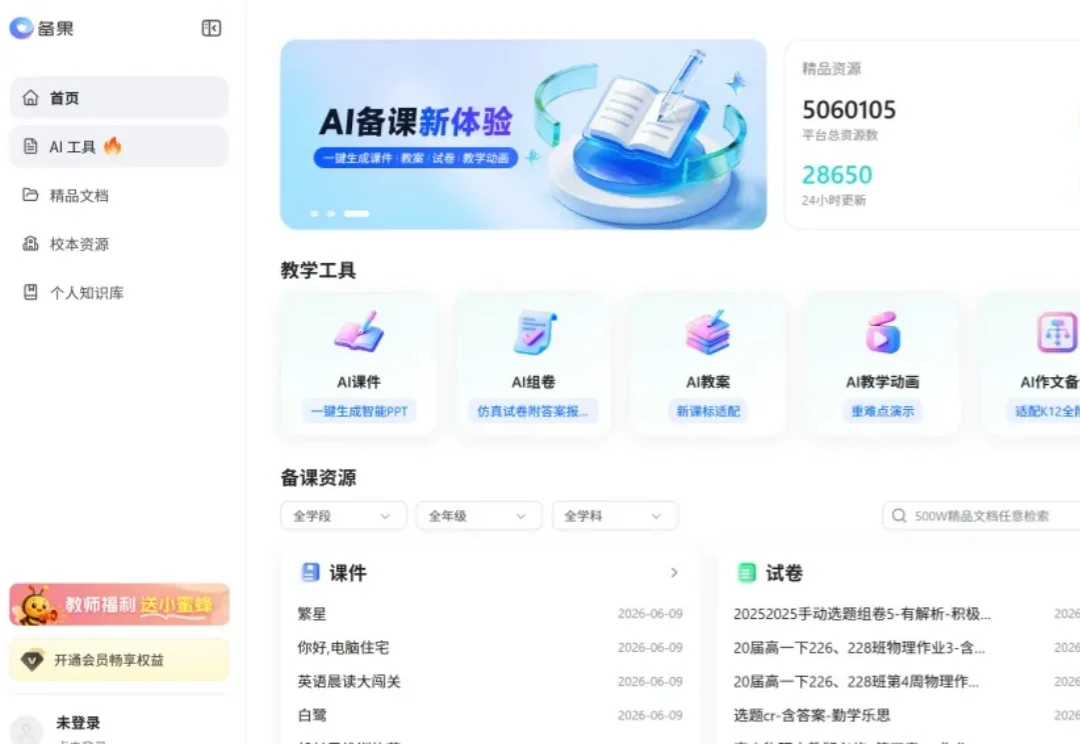
《读佳》获悉,360推出了一款名为“备果”的AI产品,该产品针对教师群体的备课场景,但AI工具的使用与文档下载均需开通会员,可见该产品并非走完全免费路线。

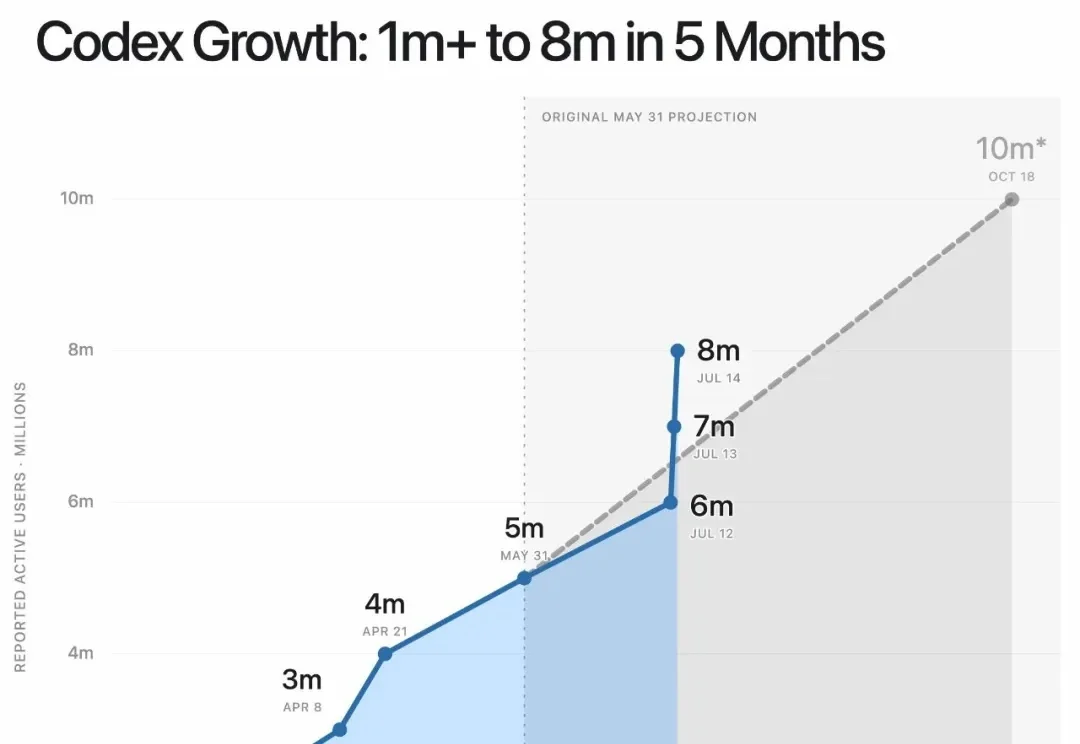
GPT-5.6发布之后,Codex开始以一种近乎夸张的速度增长。

困扰统计学界整整20年的核心悬案,被AI击碎了。

全双工语音对话是人类最自然的交流方式,是语音对话研究的梦想。相比文本输入,语音天然更接近人的交流方式,但现有语音对话常常停留在 “一问一答、听完再说” 的轮次式交互范式。

昨天那篇文章,我说了一下我现在用Agent的日常。

大家好,我是瓦力,具身算法研究员。 我有个习惯,隔三差五都会去 PI 的官网刷一下,看他有没有新东西。最近这三个月,官网主页是一动没动,停在四月的 π0.7。
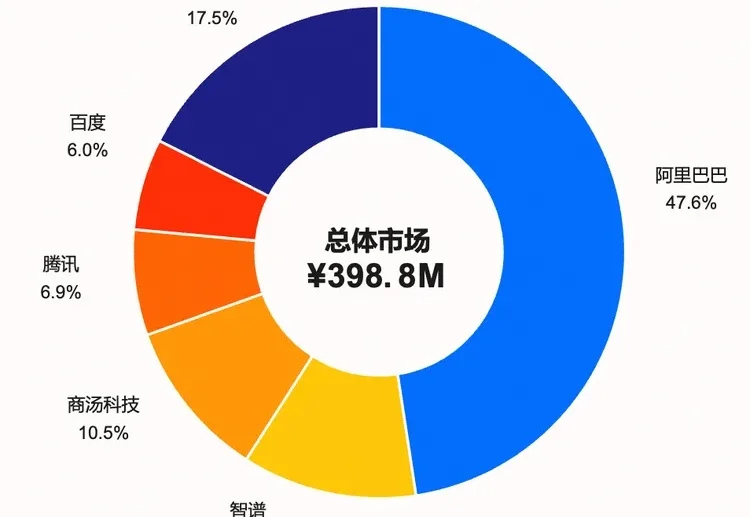
对 AI Coding 来说,有人用,比任何 Benchmark 都管用,而有人持续付费,又比有人用更管用。

