# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Paper Link: https://arxiv.org/pdf/2605.15198
Project Page: https://atlas-oneword.github.io
Code: https://github.com/ZiyuGuo99/ATLAS
近日,Meta AI 与香港中文大学颠覆性提出了一种全新的视觉推理范式 ATLAS,不用外部工具,不显式生成中间图像,没有视觉监督信号,只用一个离散 word,首次颠覆性地代替 Agentic 和 Latent Visual Reasoning。
第一作者是香港中文大学的博士生,本科毕业于北京大学计算机系,曾在Google DeepMind Veo、Meta AI、Amazon AWS AI Lab、Roblox、上海人工智能实验室等机构实习,研究多模态大模型和生成理解统一,一作代表作有 Image-CoT、Think-while-Generate、MME-CoF、Point-LLM、PointCLIP 等。

当大模型面对一道复杂的视觉推理题时,它到底应该怎么想?
一种直观做法是让模型显式生成中间图像或视觉状态(Unified Models),再基于这些中间结果继续推理。这种方式过程清楚,但往往需要反复解码和再编码视觉内容,带来较高的计算开销,也让训练和架构设计变得更加复杂,需要额外的视觉监督,且通用性较差。还有一类方法(Agentic Visual Reasoning)则把视觉推理做得更加外显:模型通过代码、工具调用或外部执行器来完成画线、标注、裁剪、放大等视觉操作。这类 Agentic Visual Reasoning 具有较好的可解释性,但引入了额外的工具执行延迟,常常需要冗长的操作调用描述,且同样需要额外的执行过程监督。
而 Latent Visual Reasoning 试图把中间推理压缩到模型内部表示中,避免显式生成图像或调用外部工具。它更加轻量,也能表达更高维的信息,但中间过程往往不够可控,同样需要对 Latent 做额外的视觉监督,且可扩展性、可解释性与泛化性也较差,难以大规模训练和泛化。
是否有一种方法,既能像 Agent 一样拥有明确的视觉操作,在保证和 Latent Visual Reasoning 一样轻量、高效的基础上,又可扩展到大规模训练和泛化到众多领域任务,同时避免显式生成中间视觉状态带来的高成本?Meta AI 与香港中文大学提出了一种全新的视觉推理范式 ATLAS,核心想法非常直观:只用一个 word,首次将 Agentic 和 Latent Visual Reasoning 统一起来。

主流视觉推理范式对比
Unified Models 像是边想边重新画一张图,Agentic 方法像是拿出一套工具箱,Latent 方法像是闭着眼在脑中想,ATLAS 更像是给模型学会了一组视觉动作暗号。模型只需要生成离散的 Funtional Token,就可以在内部表示中触发相应的视觉操作。这些 Token 看起来只是普通词表中的一个 Token,但它们承担的角色并不普通:它们既是 Agentic Operation,又是 Latent Visual Reasoning。
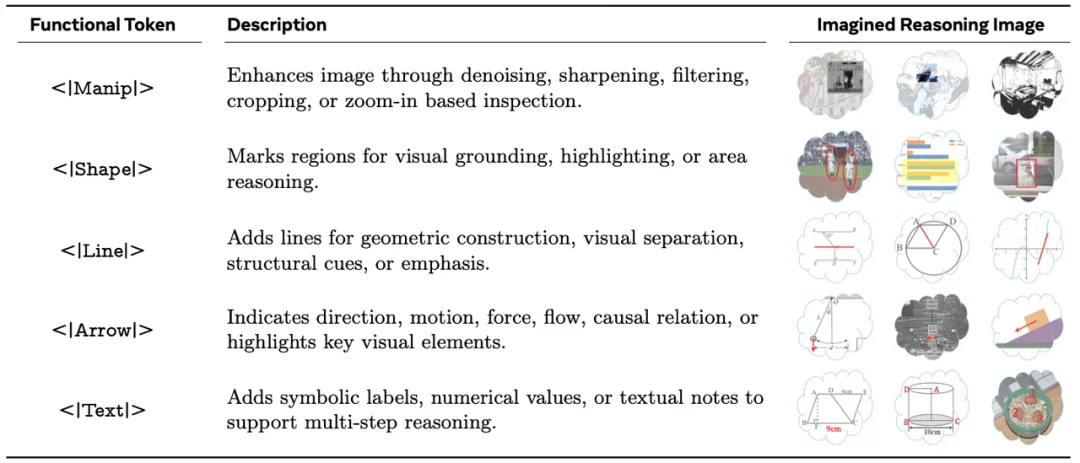
ATLAS 用一个 Token 同时连接了两件事:一方面,它像 Agentic Reasoning 一样明确表示模型想执行某种视觉操作;另一方面,它又完全存在于模型内部,不依赖外部工具或显式图像生成,因此保持了 Latent Visual Reasoning 的高效性。这些 Token 不需要额外的视觉监督,也不需要改变模型架构,就像普通词一样,通过 Next-Token Prediction 被模型生成;但一旦出现在推理链中,它们就不只是文本,还是模型内部的视觉操作锚点。
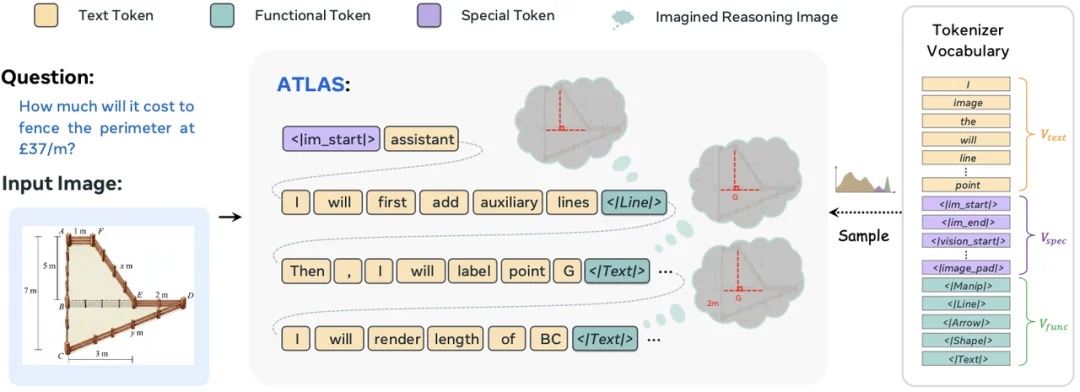
ATLAS:把视觉操作表示为标准自回归序列中的 Funtional Tokens
视觉推理中的很多中间步骤,并不一定真的需要生成一张完整图片。
做几何题时,人类脑中可能只是补一条线;做区域判断时,可能只是看一下左上角;做计数题时,可能只是给每个物体打个标记。这些动作很重要,但它们本身并不需要用大量 Token 或完整图像来表示。
ATLAS 的关键洞察是:很多视觉推理操作可以被压缩成一个高层语义动作,而这个动作可以由一个离散 Token 表达。因此,ATLAS 不再让模型输出冗长代码、调用外部工具,或者生成昂贵的中间视觉结果,而是让模型在文本推理过程中自然插入 Funtional Token。这种设计让视觉推理过程变得更加紧凑,也更接近人类在脑中进行视觉操作的方式。
为了让模型真正学会使用这些 Funtional Tokens,研究团队采用了 SFT + RL 两阶段训练流程:
研究团队构建了 ATLAS-178K 数据集,覆盖 40 多种视觉推理任务,并将复杂视觉操作映射为统一的 Funtional Token 表达。
在监督微调阶段,模型学习的不只是最终答案,而是包含 Funtional Tokens 的推理轨迹。这一步类似于示范教学:遇到画线,可能需要 <|Line|>;遇到空间区域操作,可能需要 <|Shape|>;遇到方向关系,可能需要 <|Arrow|>;遇到标注,可能需要 <|Text|>。
仅仅让模型学会生成 Funtional Token 还不够。因为如果奖励设计不当,模型很容易走向另一个极端:为了拿奖励而疯狂堆 Token。比如本来只需要一条辅助线,它却连续输出十几个视觉动作 Token,看起来很努力,但实际并没有帮助解题。
为了解决这个问题,ATLAS 在强化学习阶段设计了专门的 Reward:既奖励答对问题,也奖励合理使用 Funtional Token;同时惩罚过长输出和 Token Spam,避免模型为了刷奖励而滥用视觉动作。这使得模型不再是简单地多用 Token,而是学会在真正需要视觉操作时使用 Token。
ATLAS 中还有一个关键技术点:Latent-Anchored GRPO,简称 LA-GRPO。问题来自 Funtional Token 的稀疏性。在一整段视觉推理输出中,绝大多数 Token 仍然是普通文本,Funtional Token 只占很小比例。普通 GRPO 使用 Sequence-level Reward,虽然能整体优化模型,但对于这些极少数关键 Token 来说,梯度信号很容易被大量普通文本 Token 稀释,这就是论文中提到的 Gradient Dilution 问题。
ATLAS 的解决方式是:在 GRPO 的基础上,额外对 Funtional Token 位置进行 Token-level Anchor。如果某条推理轨迹最终答对了,并且其中某个 Funtional Token 起到了关键作用,那么 LA-GRPO 会更直接地强化这个 Token 的生成概率。这就像在训练中告诉模型:不是所有词都一样重要。真正触发视觉操作的那个 word,需要被更精准地学习。
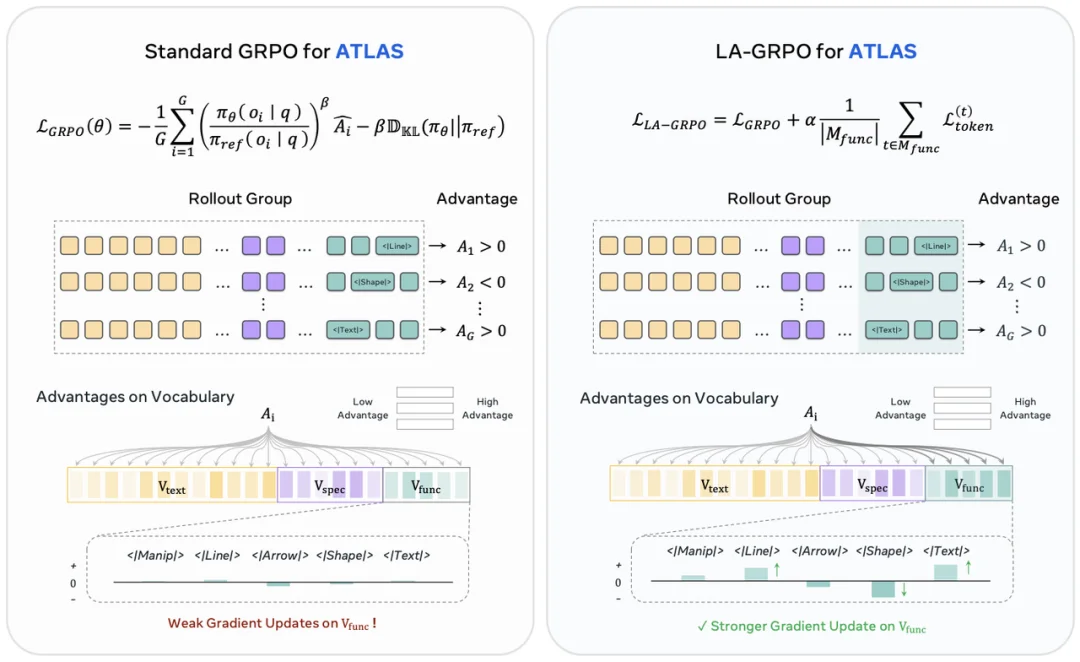
LA-GRPO:针对稀疏 Funtional Tokens 增强梯度更新,缓解 Gradient Dilution
研究团队在多个视觉推理基准上验证了 ATLAS 的效果。实验结果显示,ATLAS 在多个具有挑战性的视觉推理任务上取得了有竞争力的表现。尤其是在复杂几何推理、空间关系、多视角理解、计数和细粒度视觉判断等任务中,Funtional Token 能帮助模型更有效地组织视觉推理过程,同时非常高效。
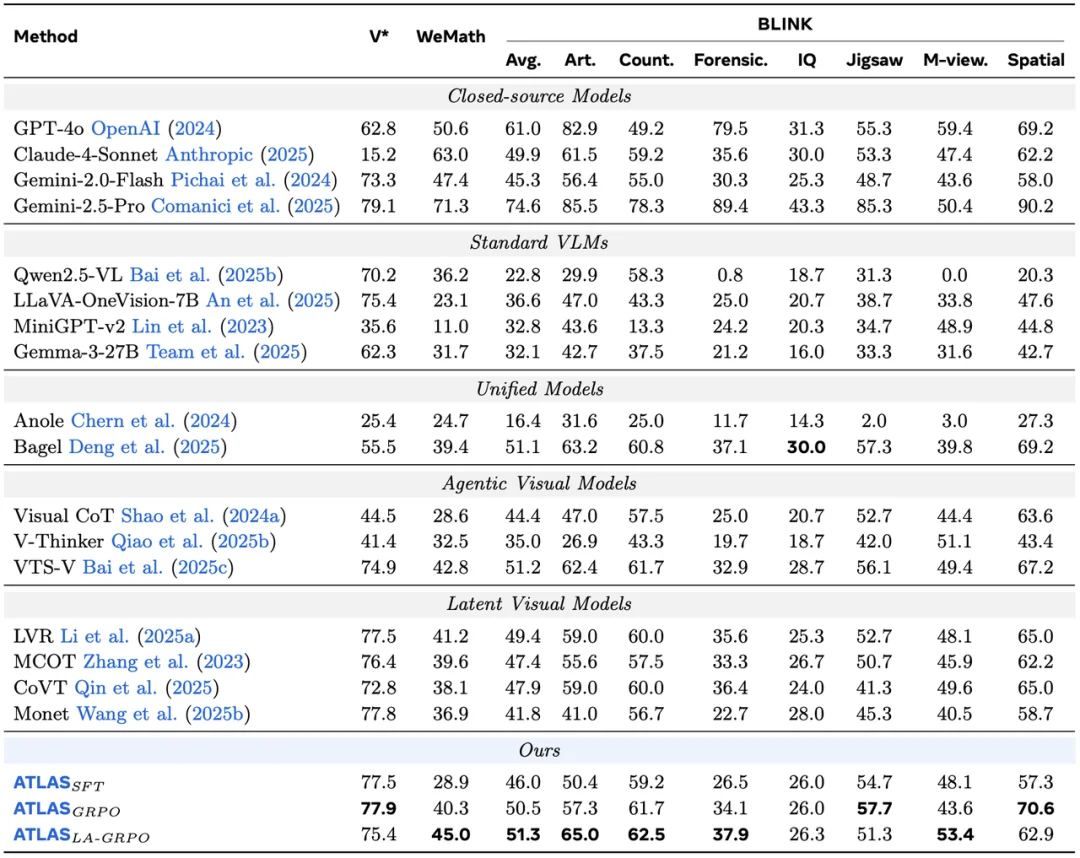
ATLAS 基准测试结果
更重要的是,ATLAS 的提升并不是通过更复杂的外部系统换来的。它不需要额外工具执行,不需要显式生成中间图像,也不需要破坏标准自回归训练流程。Funtional Token 仍然只是词表中的普通 Token,可以自然兼容现有的 SFT 和 RL 训练框架,可高效扩展至大规模训练。

ATLAS 效率分析
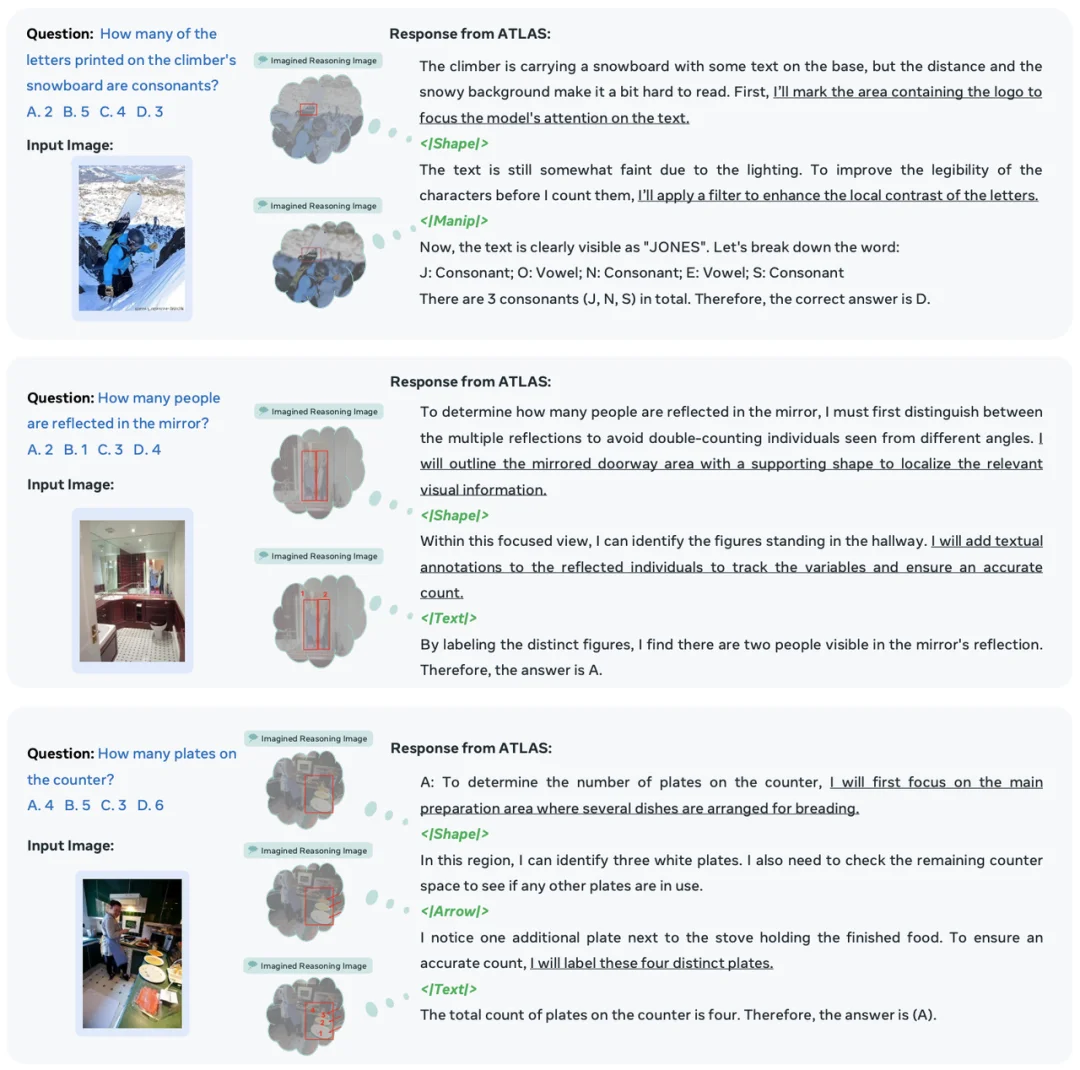
ATLAS 定性样例:Funtional Tokens 帮助模型定位、过滤和标注视觉证据
文章来自于微信公众号 “Z Potentials”,作者 “Z Potentials”


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
