# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
DAG框架利用时间与通道双重相关网络,有效整合历史与未来外生变量信息,提升时间序列预测准确性。通过发现并注入相关关系,充分利用未来协变量,显著优于现有方法。
时间序列预测在经济学、交通、智能运维等多个领域具有关键作用。然而在实际应用中,仅关注内生变量(即目标变量)往往难以保证预测精度。引入外生变量(即协变量)能够提供额外的预测信息,从而提升预测准确性。
但现有外生变量时间序列预测方法(TSFX)存在两个主要缺陷:
1)未能充分利用未来外生变量;
2)忽略内生变量与外生变量间的相关关系,导致预测性能未达最优。
为了更好地利用外生变量(特别是未来外生变量),华东师范大学的研究人员提出通用框架 DAG,通过双相关网络在时间维度和通道维度上实现外生变量时间序列预测。

论文链接:https://arxiv.org/pdf/2509.14933
代码链接:https://github.com/decisionintelligence/DAG
开源数据集链接:https://drive.google.com/file/d/1K2AvogpOpSz1PiQ53dPchzGv_PqlCWAK/view
协变量预测排行榜以及测评结果链接:https://decisionintelligence.github.io/OpenTS/leaderboards/#covariate_forecasting
具体来说,该研究首先提出时间相关模块,其包含相关发现模块(用于捕捉历史外生变量如何影响未来外生变量)和相关注入模块(将发现的相关关系融入基于历史内生变量的未来内生变量预测过程)。
随后提出通道相关模块,采用类似设计原理:通过相关发现模块建模历史外生变量对历史内生变量的影响,并借助相关注入模块将发现的相关关系用于增强基于未来外生变量的未来内生变量预测。
在多组数据集上的大量实验表明,DAG框架实现了最先进的预测性能。
当前基于深度学习的时间序列预测方法大多聚焦于单变量或多变量,并依赖于学习单个内生变量(即预测目标)内部的时间依赖关系,或多个内生变量之间的依赖关系。
然而,除了内生变量本身外,许多实际场景还涉及另一类对预测精度有显著影响的信息——外生变量(即协变量)。特别是在未来外生变量可用的情况下,有效利用这类辅助信息有可能显著提升预测性能。
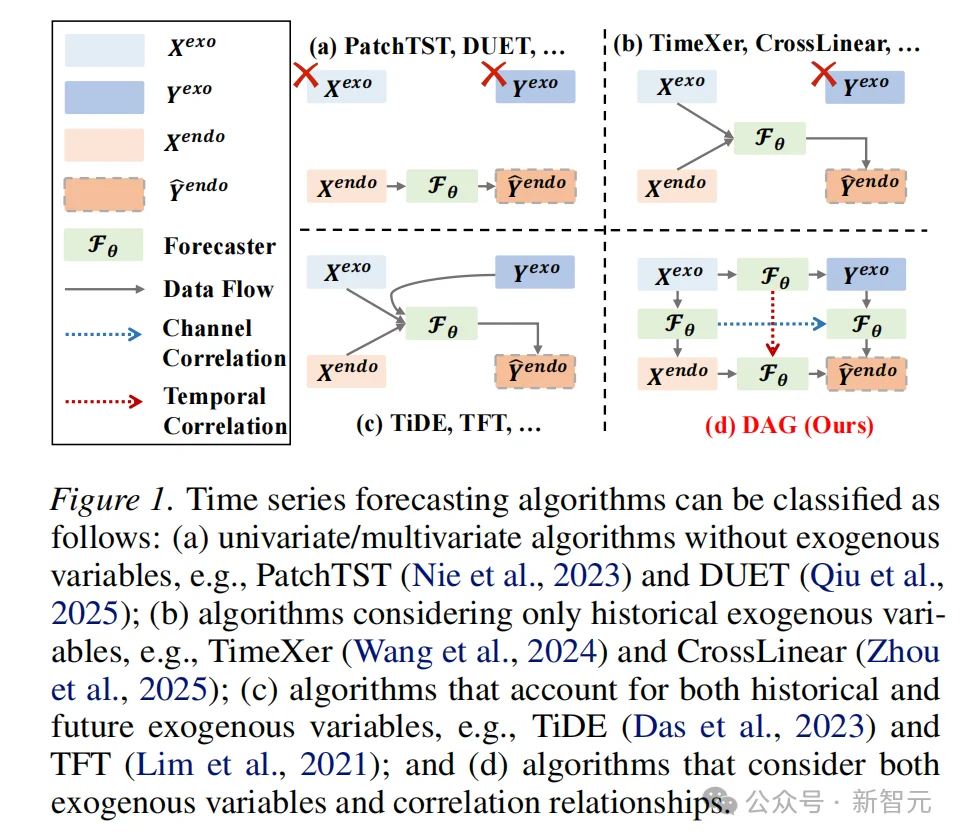
从时间角度看,协变量可以分为两类:
尽管未来外生变量具有很高的预测价值,但现有深度学习方法仍未得到充分利用。如图 1 所示,现有的「外生变量感知」预测方法大致可以分为两类:
进一步的分析(如图 2 所示)表明,利用已知的未来协变量进行预测涉及时间维度和通道维度上的相关依赖关系:
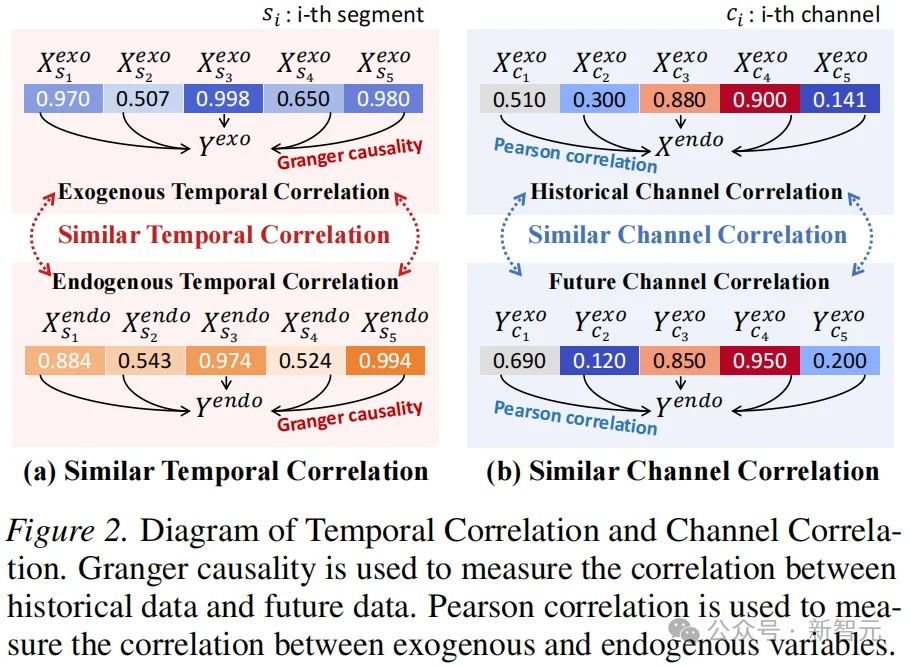
这种「双重相关结构」仍是一个尚未得到充分研究但极其关键的特征,而现有方法对其关注不足。
对此,研究人员提出了一个通用框架DAG,其核心思想是利用时间维度和通道维度上的双重相关网络,在结合外生变量的时间序列预测任务中实现高质量的未来内生变量预测。
核心贡献
DAG框架的模型结构如下图所示:
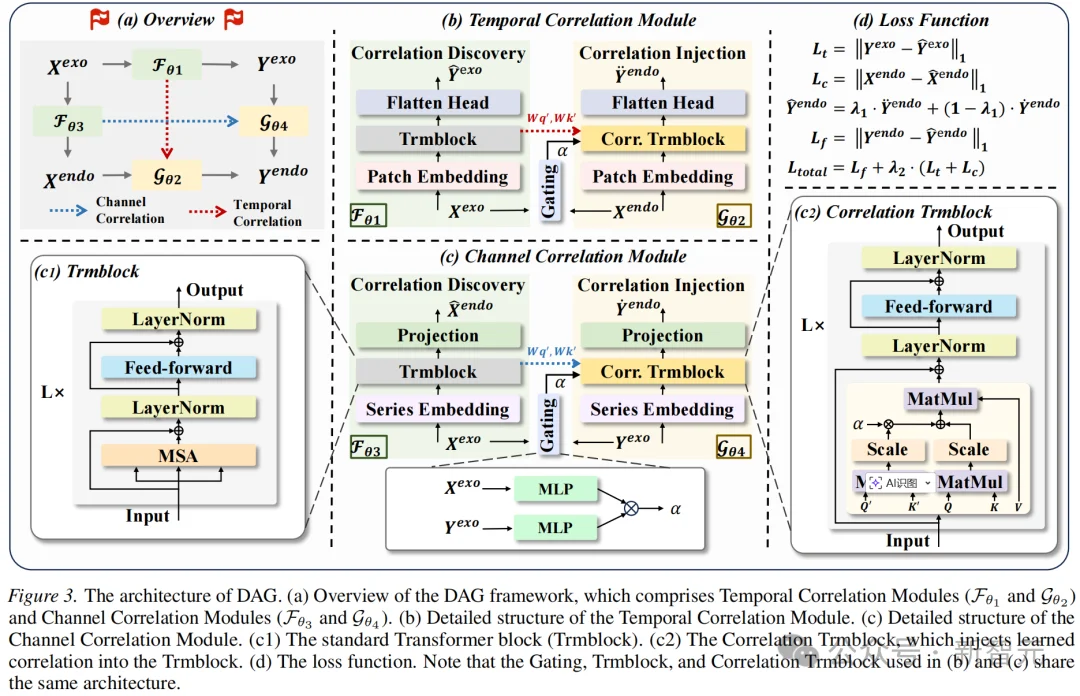
时间相关模块
历史外生变量对未来外生变量的影响,在结构上与历史内生变量演化为未来内生变量的过程具有相似性。因而,此模块设计了时间相关发现模块,用于揭示历史与未来外生变量之间的相关关系,并设计了时间相关注入模块将所发现的相关关系注入到基于历史内生变量预测未来内生变量的建模过程中以提升预测精度。
时间相关发现模块采用了 分块表示策略提取历史外生变量与未来外生变量的相关关系。具体而言,将每个历史外生变量划分为多个patch,并将每个patch投影为一个时间token:
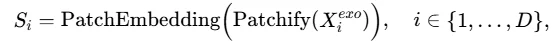
接着,该模块采用标准Transformer Block 来建模不同 patch 对未来外生变量的影响权重:
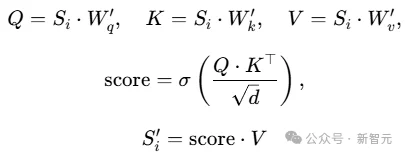
为增强鲁棒性,此模块并非直接将生成的注意力分数传递给时间相关注入模块,而是提取并传递MSA中生成注意力分数的可学习参数:查询矩阵Wq′和键矩阵Wk′。这些参数作为时间相关表示被注入。

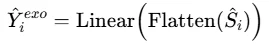
未来外生变量的预测损失被用作训练过程中的时间相关损失:
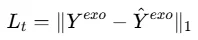
与时间相关发现模块的处理方式一致,此模块首先对历史内生变量进行分块表示:
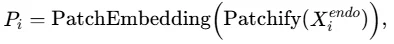

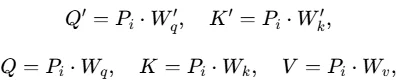
引入可学习加权因子α融合两组注意力分数,得到最终融合注意力分数:
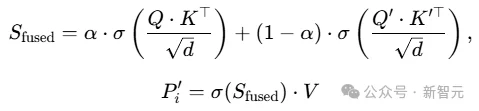
门控计算α:
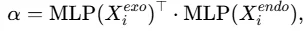
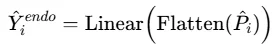
通道相关模块
类似于时间维度上的处理,通道相关模块旨在建模并注入沿变量(通道)维度的相关关系。
该模块关注历史外生变量如何影响历史内生变量,以及如何将这种相关模式迁移以利用未来外生变量增强未来内生变量的预测。

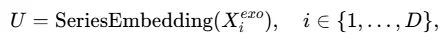
随后输入标准Transformer block:
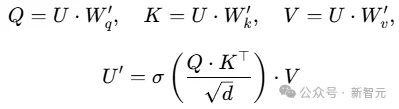
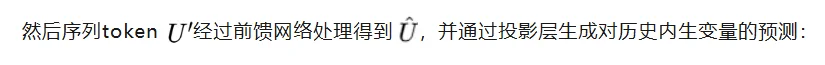
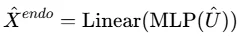

训练过程中,历史内生变量的预测损失用作通道相关损失:
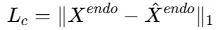
该模块使用未来外生变量预测未来内生变量,同时注入先前提取的通道级相关表示。首先,未来外生变量采用同样的序列嵌入策略进行编码:
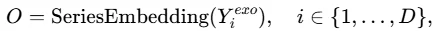
随后使用类似的Correlation Transformer block来建模通道依赖,同时注入学习到的相关信息:
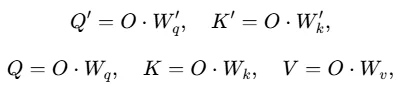
引入门控机制计算可学习权重α:
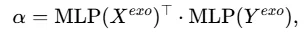
融合注意力分数:
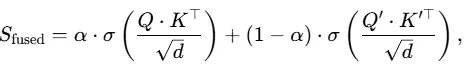
融合后的token表示:
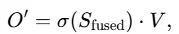

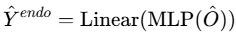
损失函数与输出
DAG的训练目标由三部分组成:
为了得到未来内生变量的最终预测,使用融合权重λ1对两种候选预测进行加权融合:
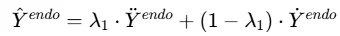

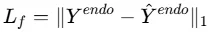
最终,总损失函数将预测损失与相关建模损失结合:
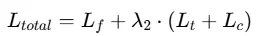
其中,λ2为相关权重,用于平衡训练过程中相关建模的贡献。
整体性能
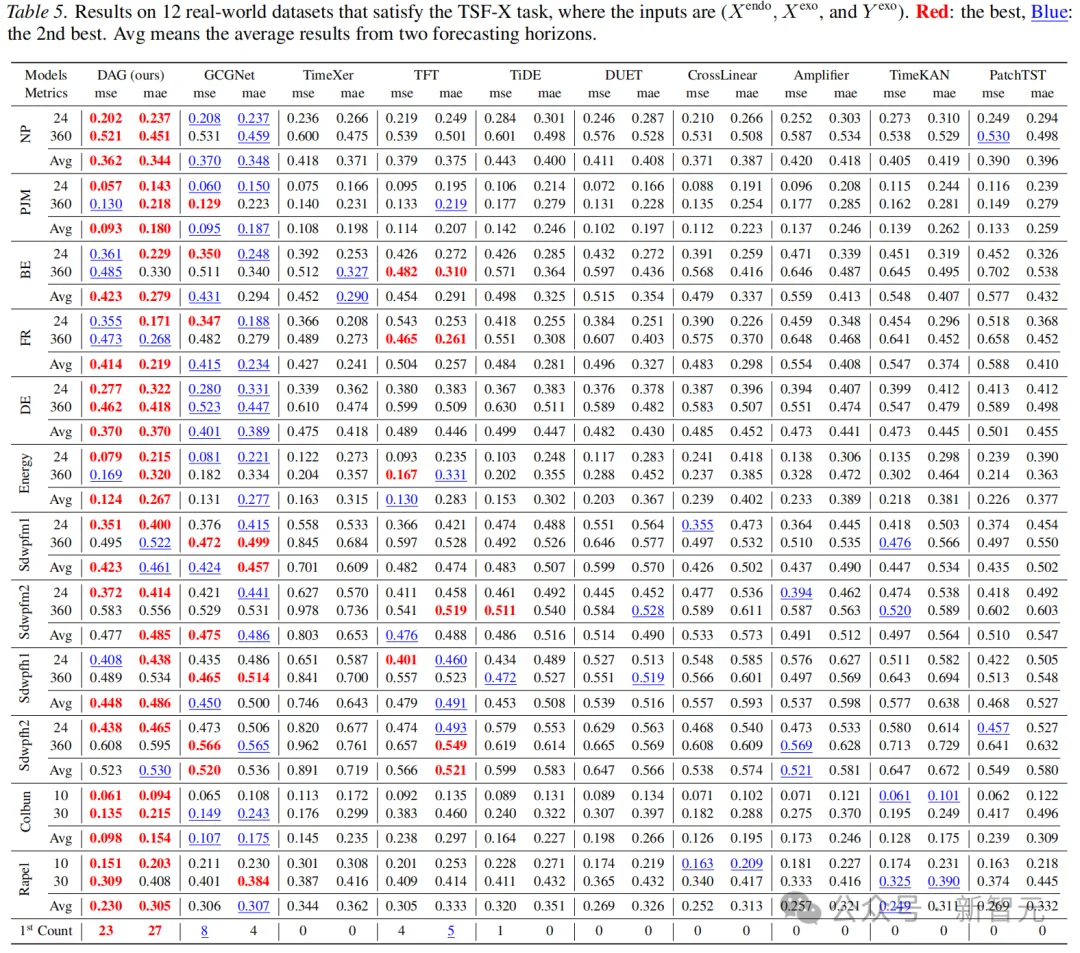
DAG模型主要在12个满足 TSFX 条件的真实世界数据集上进行了长短期预测实验,并与9个常用基线方法进行了对比,这些方法包括:支持未来外生变量的方法(如 GCGNet、TimeXer、TFT、TiDE)以及原本不支持未来外生变量的方法(如 DUET、CrossLinear、Amplifier、TimeKAN、PatchTST)。
对于不支持未来协变量的方法,研究通过MLP融合进行改造,以加入未来外生变量。为保证公平性,所有实验均使用相同的输入数据。
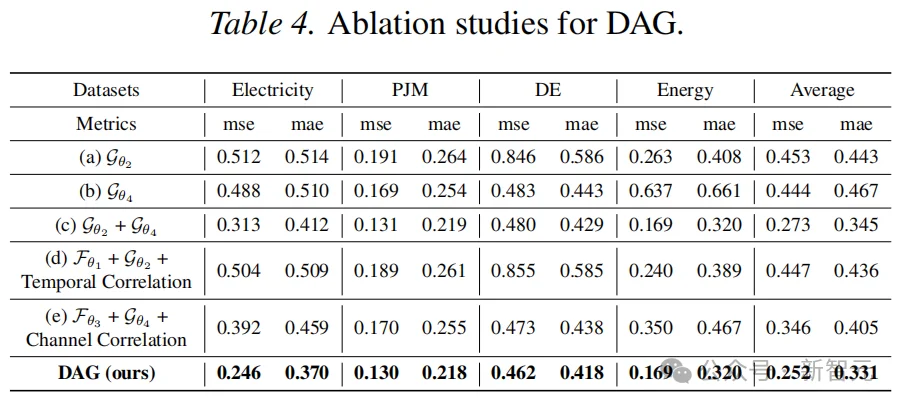
消融实验

观察到以下几点:

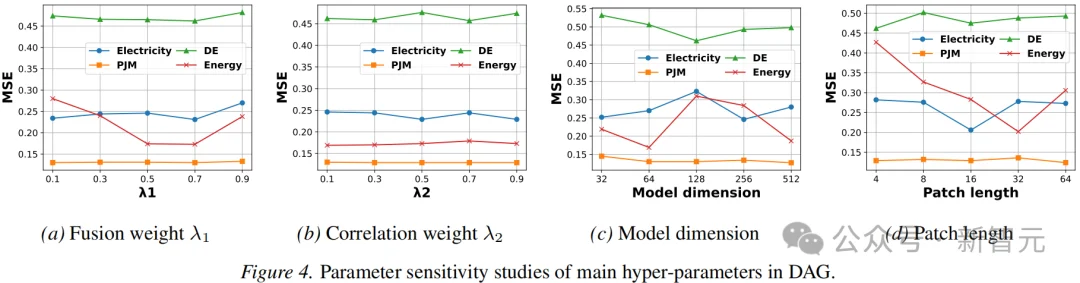
参数敏感性
对DAG的参数敏感性进行研究后有以下发现:
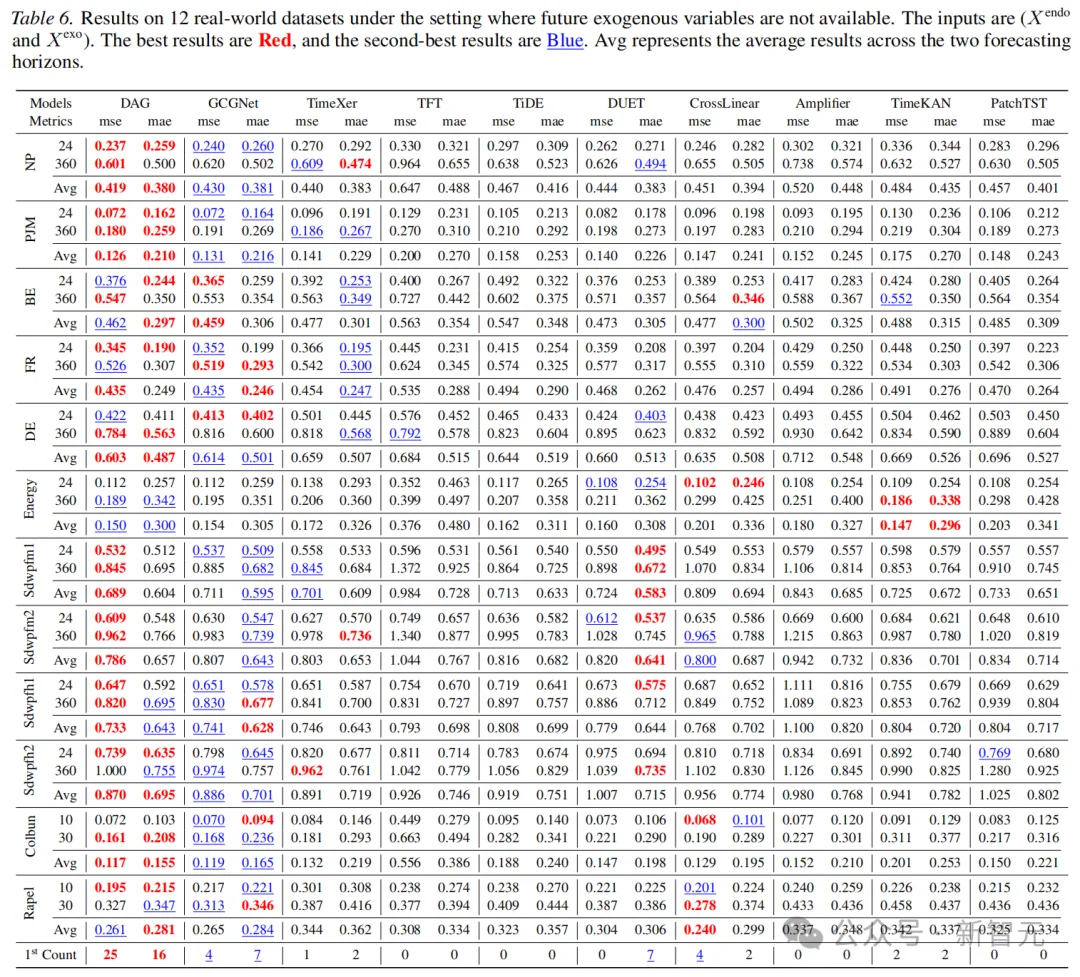
不使用未来协变量情况
考虑到有些数据集无法获取未来外生变量,该研究对 DAG 进行了只使用历史外生变量的实验。
实验结果显示,DAG依然表现出色。TimeXer、CrossLinear 等方法也表现良好;DUET表现不错,而PatchTST表现较差。
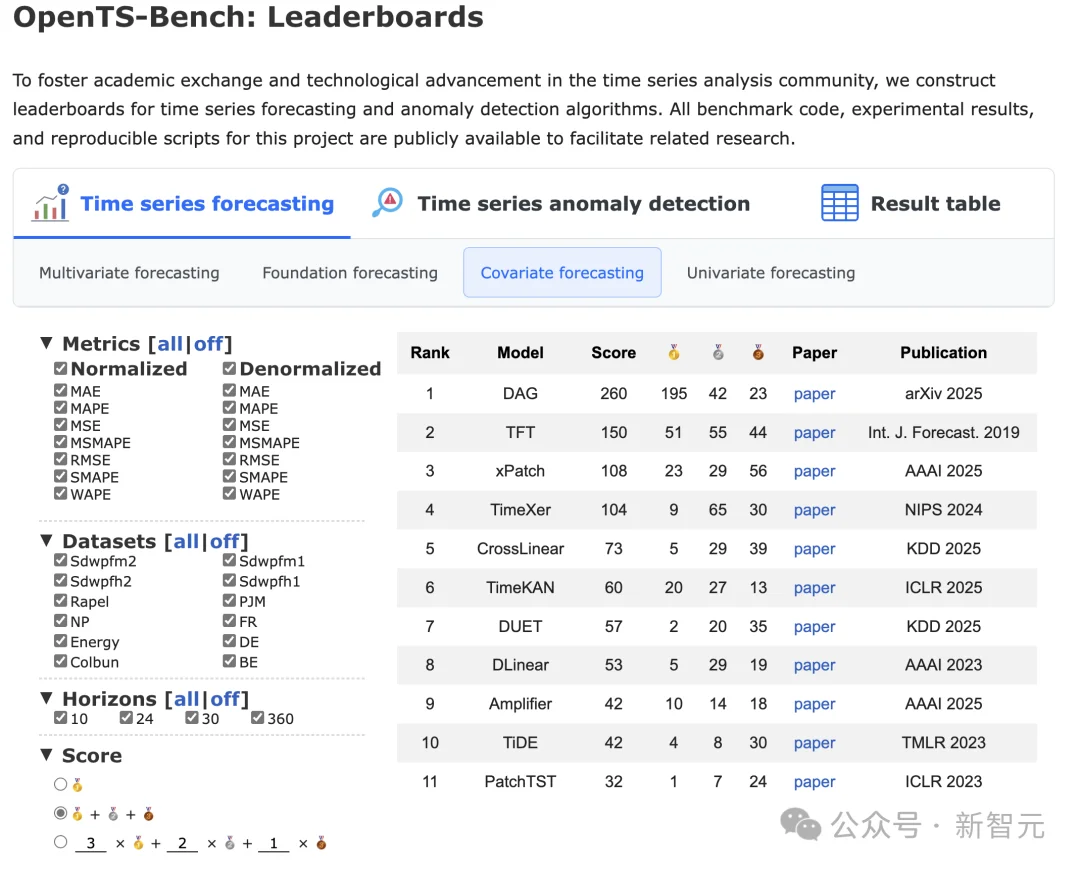
协变量预测排行榜以及测评结果链接:https://decisionintelligence.github.io/OpenTS/leaderboards/#covariate_forecasting
研究人员提出了一个通用框架DAG,该框架沿时间和通道维度利用双重相关网络进行含外生变量的时间序列预测,尤其充分利用未来外生变量信息。
框架引入了时间相关模块,包括一个时间相关发现模块,用于建模历史外生变量如何影响未来外生变量;
随后通过相关注入模块将这些关系整合进未来内生变量的预测中。
此外,还引入了通道相关模块,该模块通过通道相关发现模块建模历史外生变量对历史内生变量的影响,并通过注入这些关系提升基于未来外生变量的未来内生变量预测精度。

论文第一作者邱翔飞,现为华东师范大学23级硕博连读生,师从胡吉林,杨彬教授,主要研究方向为时序分析与测评,时序大模型。在NeurIPS,ICML,VLDB,KDD等CCF A类会议及期刊发表录用论文22篇,其中以第一作者(含共同一作)身份发表14篇,截止目前谷歌学术引用1300+,H指数15。一作论文TFB获得VLDB 2024最佳论文奖提名,DUET荣登KDD 2025 Paper Digest最具影响力论文。入选中国科协青年科技人才培育工程博士生专项,荣获CCF优秀大学生学术秀(硕士组)冠军。
邱翔飞所在的决策智能实验室依托华东师范大学,数据科学与工程学院,具有一支国际化,高水平导师团队,一人入选国家级领军人才,两人入选国家级青年人才。主要研究方向涵盖人工智能、机器学习和数据管理。通过对复杂异构数据(例如时间序列、时空数据、图、图像和分子结构等)进行高精度、高效率、自动的、高鲁棒性、可解释的分析和管理,助力不同行业的数字化转型和不同应用领域的决策支持。
参考资料:
https://arxiv.org/pdf/2509.14933
文章来自于"新智元",作者 "LRST"。


