# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多租户 RAG 与Agent系统的生产实践中,最致命的事故莫过于数据串租,系统将租户 B 的私有数据作为背景知识,回答了租户 A 的提问。
针对这个问题,本文将深入分析串租发生的根源,并展示如何利用Milvus 的 Partition Key 能力进行物理隔离,同时引入AutoRAG 自动评测框架,实现一整套完整的多租隔离验证机制。
串租的根本原因,通常有两种:
第一,运行时风险(缺少租户过滤的物理边界):查询时如果缺少严格的租户过滤,由于向量空间的连续性,如果 A 和 B 的文档语义相似,又没有 tenant_id 过滤,检索结果就可能跨租户混排。
第二,验证缺失风险(缺乏持续监控):即使代码中加了过滤逻辑,也不能默认它一直有效。模型、数据、索引、检索参数、Pipeline 配置都会变。每次变更后,如果没有自动化评测,就很难知道边界是否还在继续生效。
也是因此,解决以上问题,需要我们从检索执行层(Milvus )以及评测流程(AutoRAG)两手抓起。方法论总结如下:

在多租户场景中,本文重点使用 Milvus 的 Partition Key。
更多多租户场景的Milvus实战,可以参考Milvus多租户实践:你的技术选型扛得住一夜爆火吗?
在 Partition Key模式下,将 tenant_id 字段设为分区键后,Milvus 会在写入时对该值做 Hash 路由,数据落到对应物理分区;只要查询时携带过滤表达式,系统就会先收敛到对应分区,再做向量相似度搜索。
目前,单个 Collection 支持最多 4096 个物理分区(默认 16 个),足以覆盖绝大多数多租户规模。
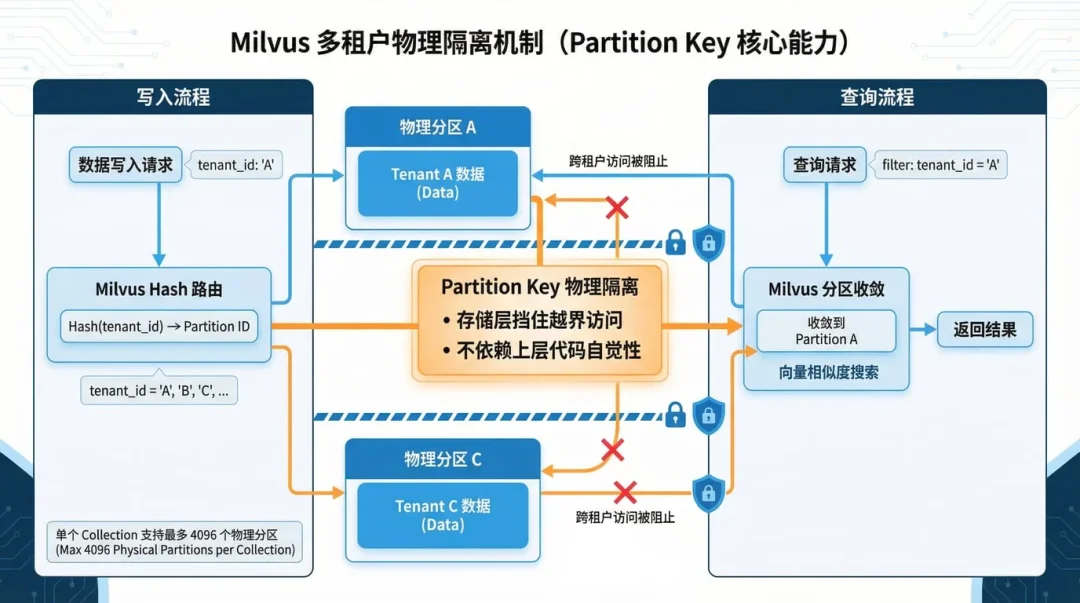
值得注意的是,Partition Key 不是权限系统,它不会自动替你判断当前用户属于哪个租户。真正的安全边界仍然依赖业务层从认证上下文中取出 tenant_id,并在每次查询时强制注入过滤条件。
也就是说:如果写入时有 tenant_id 可以哈希路由到对应物理分区,不带 tenant_id 过滤时,会默认访问所有分区里的数据。
AutoRAG 是一个RAG 流水线自动评测与优化框架,其核心架构分为三层:
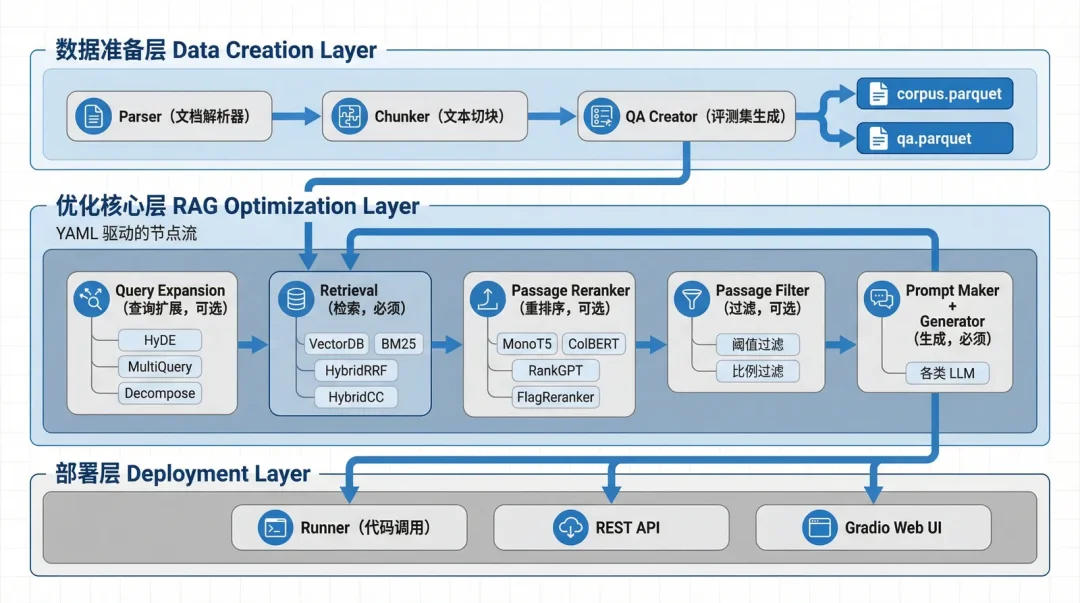
数据准备层(Data Creation):Parser 解析文档 → Chunker 切块 → QA Creator 生成评测集,输出标准的 corpus.parquet 和 qa.parquet。
优化核心层(RAG Optimization):通过 YAML 串联 Query Expansion、Retrieval、Reranker、Filter、Prompt Maker 和 Generator 等节点,并自动枚举最优组合:
部署层(Deployment):评测产出的最优 Pipeline 可直接部署为 Runner(代码调用)、REST API 或 Gradio Web UI。
基于以上架构,AutoRAG有两个核心能力:
第一个是 Pipeline 优化。
用户可以在 YAML 里声明候选模块,比如检索器、重排器、生成器。AutoRAG 会自动枚举组合,评测不同配置,并找出效果最好的 Pipeline。
第二个是可重复评测。
评测流程配置好之后,每次换模型、改数据、调参数,都需要重新执行,并用同一套指标横向对比。
本文主要用到的是第二个能力:把“多租户场景下检索结果是否可信”变成可以重复运行的评测流程。
另外,值得一提的是,Milvus 在 AutoRAG 的 Retrieval 节点中是原生一等公民。AutoRAG 的 vectordb 配置里,db_type: milvus 开箱即用,不需要任何适配代码。在 AutoRAG 的评测流水线里,Milvus 也可以直接作为检索后端参与评测,没有额外集成成本。
Step 1:准备环境
python3 -m venv .venv
source .venv/bin/activate
pip install -U pip
pip install "autorag>=0.3""pymilvus>=2.4.0""openai""pandas""pyarrow"
export OPENAI_API_KEY=sk-... #自行准备OpenAI_API_KEY
export MILVUS_URI=http://127.0.0.1:19530 # Milvus Standalone 服务地址
export MILVUS_TOKEN="root:Milvus"
部署 Milvus
# 下载docker-compose.yml
wget https://github.com/milvus-io/milvus/releases/download/v2.6.8/milvus-standalone-docker-compose.yml -O docker-compose.yml
# 启动Milvus(检查端口映射:19530:19530)
docker-compose up -d
# 验证服务启动
docker ps | grep milvus
# 应该看到3个容器:milvus-standalone, milvus-etcd, milvus-minio
Step 2:准备 AutoRAG 标准格式数据
为了精准验证隔离是否生效,我们需要设计一种“相同提问( q1 和 q2 是文字完全相同的查询)、不同租户、不同答案”的高难度测试集。如果系统隔离失效,全库检索必然会将两个租户的答案混淆。
⚠️ 说明1:AutoRAG 对输入字段有严格的命名约定(如 doc_id、retrieval_gt 等),写错会导致解析报错。
说明 2:以下 Step 2-4 中的 Python 代码块,各自保存为对应的 .py 文件后,在激活的虚拟环境中用 python3 文件名.py 执行。

retrieval_gt 是检索标注字段,记录每条问题期望命中的 doc_id 列表,AutoRAG 用它计算 Recall / Precision。没有这个字段,评测无法运行。
import os
import pandas as pd
os.makedirs("./data", exist_ok=True)
corpus = pd.DataFrame([
{"doc_id": "a-1", "contents": "A租户的报销规则:差旅上限为内部标准。", "metadata": {"tenant_id": "tenant_a"}, "tenant_id": "tenant_a"},
{"doc_id": "a-2", "contents": "A租户合同模板要求法务审批。", "metadata": {"tenant_id": "tenant_a"}, "tenant_id": "tenant_a"},
{"doc_id": "b-1", "contents": "B租户的报销规则:海外差旅需要二级审批。", "metadata": {"tenant_id": "tenant_b"}, "tenant_id": "tenant_b"},
{"doc_id": "b-2", "contents": "B租户合同模板要求采购会签。", "metadata": {"tenant_id": "tenant_b"}, "tenant_id": "tenant_b"},
])
qa = pd.DataFrame([
{
"qid":"q1",
"query": "报销规则里差旅审批要求是什么?",
"retrieval_gt": [["a-1"]], # List[List[str]]:期望命中的 doc_id 集合
"generation_gt": ["A租户内部标准。"], # List[str]:可接受的参考答案
"tenant_id": "tenant_a",
},
{
"qid": "q2",
"query": "报销规则里差旅审批要求是什么?", # 与 q1 文字完全相同的查询
"retrieval_gt": [["b-1"]],
"generation_gt": ["B租户海外差旅需二级审批。"],
"tenant_id": "tenant_b",
},
])
corpus.to_parquet("./data/corpus.parquet", index=False)
qa.to_parquet("./data/qa.parquet",index=False)
Step 3:创建 Collection 并设置 Partition Key
import os
from pymilvus import MilvusClient, DataType
client = MilvusClient(
uri=os.getenv("MILVUS_URI", "http://127.0.0.1:19530"),
token=os.getenv("MILVUS_TOKEN", ""),
)
COLLECTION = "kb_multi_tenant_pk"
if client.has_collection(COLLECTION):
client.drop_collection(COLLECTION)
schema = client.create_schema(auto_id=False, enable_dynamic_field=False)
schema.add_field("pk",DataType.VARCHAR, is_primary=True,max_length=64)
schema.add_field("tenant_id", DataType.VARCHAR, is_partition_key=True, max_length=64)
schema.add_field("doc_id", DataType.VARCHAR, max_length=64)
schema.add_field("contents", DataType.VARCHAR, max_length=2048)
# text-embedding-3-small 默认输出1536维度
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=1536)
idx = client.prepare_index_params()
idx.add_index(field_name="embedding", index_type="AUTOINDEX", metric_type="COSINE")
client.create_collection(
collection_name=COLLECTION,
schema=schema,
index_params=idx,
num_partitions=16, # Partition Key 模式下的物理分区数,默认 16,最大 4096
)
print(f"✅ Collection '{COLLECTION}' created,Partition Key → tenant_id")
Step 4:生成 Embedding,写入 Milvus
这一步是数据进入检索层的实际入口,也是 tenant_id 被绑定到向量上的时机。
import os
import pandas as pd
from openai import OpenAI
from pymilvus import MilvusClient
openai_client = OpenAI()
client = MilvusClient(
uri=os.getenv("MILVUS_URI", "http://127.0.0.1:19530"),
token=os.getenv("MILVUS_TOKEN", ""),
)
COLLECTION = "kb_multi_tenant_pk"
defembed(texts: list[str], model: str = "text-embedding-3-small") -> list[list[float]]:
resp = openai_client.embeddings.create(input=texts, model=model)
return [item.embedding for item in resp.data]
corpus_df= pd.read_parquet("./data/corpus.parquet")
embeddings = embed(corpus_df["contents"].tolist())
rows = [
{
"pk": row["doc_id"],
"tenant_id": row["tenant_id"],# Partition Key 字段,决定物理路由
"doc_id": row["doc_id"],
"contents": row["contents"],
"embedding": emb,
}
for (_, row), emb inzip(corpus_df.iterrows(), embeddings)
]
client.insert(collection_name=COLLECTION, data=rows)
client.flush(collection_name=COLLECTION)
print(f"✅ Inserted {len(rows)} documents into Milvus")
Step 5:配置 AutoRAG,执行评测
说明:AutoRAG 的 YAML 解析基于标准 PyYAML,不会自动展开${ENV_VAR} 形式的环境变量。运行下方脚本先生成含真实值的配置文件,再执行评测命令。
import os
milvus_uri = os.getenv("MILVUS_URI", "http://127.0.0.1:19530")
milvus_token = os.getenv("MILVUS_TOKEN", "")
collection_name = os.getenv("AUTORAG_COLLECTION", "kb_autorag_eval")
config = f"""
vectordb:
- name: milvus_tenant_store
db_type: milvus
embedding_model: openai_embed_3_small
collection_name: {collection_name}
uri: {milvus_uri}
token: {milvus_token}
node_lines:
- node_line_name: retrieve_node_line
nodes:
- node_type: semantic_retrieval
strategy:
metrics: [retrieval_recall, retrieval_precision, retrieval_f1]
top_k: 5
modules:
- module_type: vectordb
vectordb: milvus_tenant_store
"""
os.makedirs("./config", exist_ok=True)
withopen("./config/autorag_milvus_tenant.yaml", "w") as f:
f.write(config.strip())
print("✅ Config written to ./config/autorag_milvus_tenant.yaml")
(这里要先讲清楚 AutoRAG 在测什么。AutoRAG 这一步主要测租户内部的检索质量:在某个租户自己的语料范围内,Recall、Precision、F1 是否达标。它不是在证明 Partition Key 的隔离边界。YAML 里没有配置 tenant 过滤,AutoRAG 会搜全库。)
接着,在终端中执行以下 Shell 脚本,切分数据集并跑通自动化评测:
# 按租户拆分评测集,保证评测数据不跨租户污染
python3 -<< 'EOF'
import pandas as pd
qa= pd.read_parquet('./data/qa.parquet')
corpus = pd.read_parquet('./data/corpus.parquet')
for tid in ["tenant_a", "tenant_b"]:
qa[qa["tenant_id"]== tid].to_parquet(f"./data/qa_{tid}.parquet", index=False)
corpus[corpus["tenant_id"] == tid].to_parquet(f"./data/corpus_{tid}.parquet", index=False)
EOF
# 分别对两个租户执行评测,结果落到各自的 benchmark 目录
# 注意:每个租户使用独立 collection,避免评测数据相互污染
for TENANT in tenant_a tenant_b; do
AUTORAG_COLLECTION=kb_autorag_eval_${TENANT} python3 step5_write_config.py
autorag evaluate \
--config ./config/autorag_milvus_tenant.yaml \
--qa_data_path ./data/qa_${TENANT}.parquet \
--corpus_data_path ./data/corpus_${TENANT}.parquet \
--project_dir ./benchmark/${TENANT}
done
评测完成后,可以在 benchmark/tenant_a/*/retrieve_node_line/semantic_retrieval/summary.csv 中看到量化的检索质量。在此标准测试下,租户内部的检索表现优秀:
这说明在当前评测集内,检索能命中目标文档。但它还不能单独证明不会串租。隔离边界需要下一步直接查询 Milvus 来验证。
AutoRAG 评测产出的 Recall / Precision / F1 反映的是租户内部的检索质量。
但在执行 AutoRAG CLI 评测时,为了兼容其底层机制、避免评测时的状态复用导致跨租户污染,我们在评测期为不同租户初始化独立的评测 Collection,以此确保评测结论的绝对纯净和可信。
但要验证隔离是否生效,我们必须在单 Collection 架构下进行双重对撞测试。用同一条查询,分别携带 tenant_a 和 tenant_b 的过滤条件直接测试 Milvus,确认结果集没有任何交叉,同时对比去掉过滤后的混排结果。
import os
from openai import OpenAI
from pymilvus import MilvusClient
COLLECTION = "kb_multi_tenant_pk"
client = MilvusClient(
uri=os.getenv("MILVUS_URI", "http://127.0.0.1:19530"),
token=os.getenv("MILVUS_TOKEN", ""),
)
openai_client = OpenAI()
def embed(texts: list[str], model: str = "text-embedding-3-small") -> list[list[float]]:
resp = openai_client.embeddings.create(input=texts, model=model)
return [item.embedding for item in resp.data]
query = "报销规则里差旅审批要求是什么?"
query_vector = embed([query])[0]
# ✅ 带 tenant 条件查询
for tid in ["tenant_a", "tenant_b"]:
results = client.search(
collection_name=COLLECTION,
data=[query_vector],
filter=f'tenant_id == "{tid}"',
limit=5,
output_fields=["doc_id", "tenant_id", "contents"],
)
print(f"
=== 查询租户: {tid} ===")
for hit in results[0]:
e = hit["entity"]
print(f" doc={e['doc_id']} tenant={e['tenant_id']} score={hit['distance']:.4f}")
print(f" → {e['contents'][:40]}...")
# ❌ 无过滤,语义相似度跨租户返回
print("
=== ⚠️ 无 tenant 过滤(危险示范)===")
results_nf = client.search(
collection_name=COLLECTION,
data=[query_vector],
limit=5,
output_fields=["doc_id", "tenant_id", "contents"],
)
for hit in results_nf[0]:
e = hit["entity"]
print(f" doc={e['doc_id']} tenant={e['tenant_id']} score={hit['distance']:.4f}")
输出类似:
=== 查询租户: tenant_a ===
doc=a-1 tenant=tenant_a score=0.6015
→ A租户的报销规则:差旅上限为内部标准。...
doc=a-2 tenant=tenant_a score=0.3933
→ A租户合同模板要求法务审批。...
=== 查询租户: tenant_b ===
doc=b-1 tenant=tenant_b score=0.6914
→ B租户的报销规则:海外差旅需要二级审批。...
doc=b-2 tenant=tenant_b score=0.2637
→ B租户合同模板要求采购会签。...
=== ⚠️ 无 tenant 过滤(危险示范)===
doc=b-1 tenant=tenant_b score=0.6914 ← 两个租户的文档混排
doc=a-1 tenant=tenant_a score=0.6015
doc=a-2 tenant=tenant_a score=0.3933
doc=b-2 tenant=tenant_b score=0.2637
结论一目了然:带过滤的查询,两边结果严格互无交集,物理隔离完全生效;而不带过滤时,两个租户的数据立刻发生混排,证明串租风险确实存在,存储层的 Partition Key 是非常有必要存在的。
要将这套方案推进到生产环境,业务层还必须增加两道校验
1. 写入时强校验 tenant_id,字段缺失直接拒绝
defvalidate_and_insert(doc: dict):
ifnot doc.get("tenant_id"):
raise ValueError(
f"doc_id={doc.get('doc_id')} 缺少 tenant_id,拒绝入库。"
"不允许事后补填——无tenant_id 的向量进入集合后无法补救。"
)
client.insert(collection_name=COLLECTION, data=[doc])
依赖“约定大家都会填”是串租的根源之一。缺字段时的静默写入比报错更危险。
2. 查询时 tenant_id 必须来自认证上下文,不接受客户端传参
#❌ 错误:相信客户端传进来的值,可以被伪造
tenant_id = request.params.get("tenant_id")
filter_expr = f'tenant_id == "{tenant_id}"'
# ✅ 正确:从服务端验证过的Token 中提取,不可伪造
tenant_id = auth_token.claims["tenant_id"]
filter_expr = f'tenant_id == "{tenant_id}"'
results = client.search(
collection_name=COLLECTION,
data=[query_vector],
filter=filter_expr, # 过滤条件由系统注入,不经过客户端
limit=top_k,
output_fields=["doc_id", "contents"],
)
作为后台网关,检索所使用的 tenant_id 必须来自服务端解析验证后的 Token 上下文(如 JWT),严禁接收客户端直接传参(如 POST /search?tenant_id=xxx),防止黑客通过篡改参数进行越权水平攻击。
在实践中,我们建议将多租户的设计与校验分为三层
这样,多租户隔离就不再只是代码里的一个约定,而是一套可以重复运行、可以对比结果、可以接入 CI 的工程检查。

Zilliz黄金写手:尹珉
文章来自于"Zilliz",作者 "尹珉"。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
