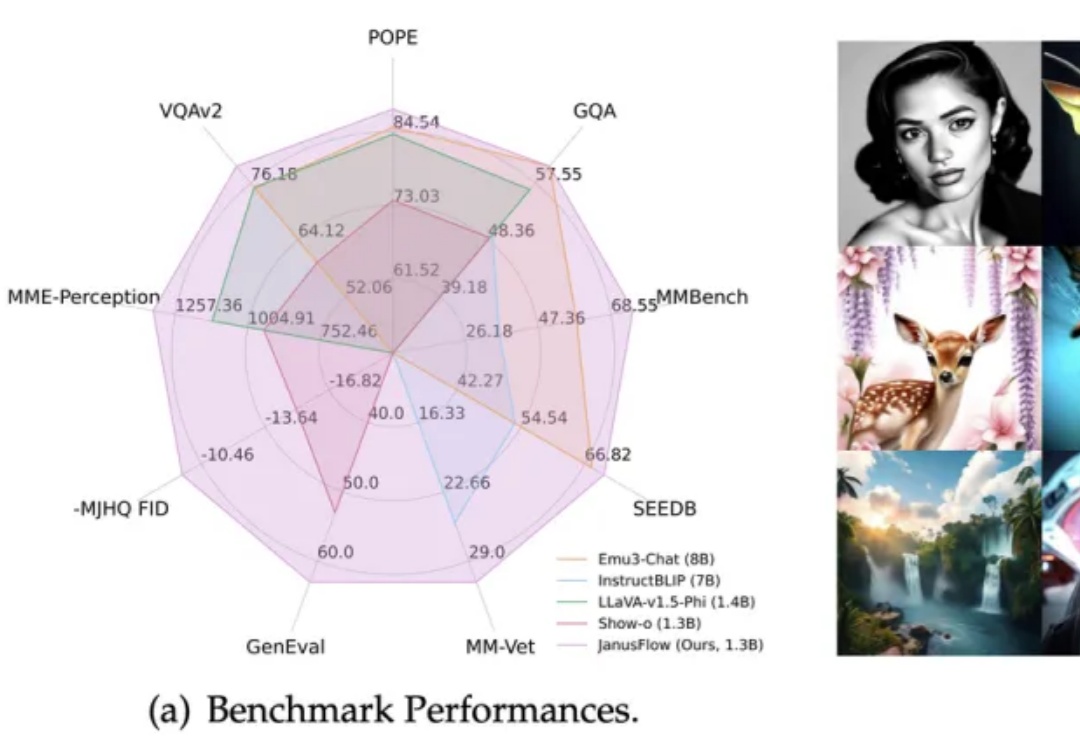
DeepSeek等团队新作JanusFlow: 1.3B大模型统一视觉理解和生成
DeepSeek等团队新作JanusFlow: 1.3B大模型统一视觉理解和生成在多模态AI领域,基于预训练视觉编码器与MLLM的方法(如LLaVA系列)在视觉理解任务上展现出卓越性能。
来自主题: AI技术研报
10284 点击 2024-11-22 15:54
 搜索
搜索
在多模态AI领域,基于预训练视觉编码器与MLLM的方法(如LLaVA系列)在视觉理解任务上展现出卓越性能。

时隔5年,巴黎圣母院终于完成修复,将在12月7日重新开放。在这场耗资数亿欧元的浩大工程中,3D建模等关键AI技术发挥了关键作用,让历经800多年沧桑的教堂与现代科技完美融合。
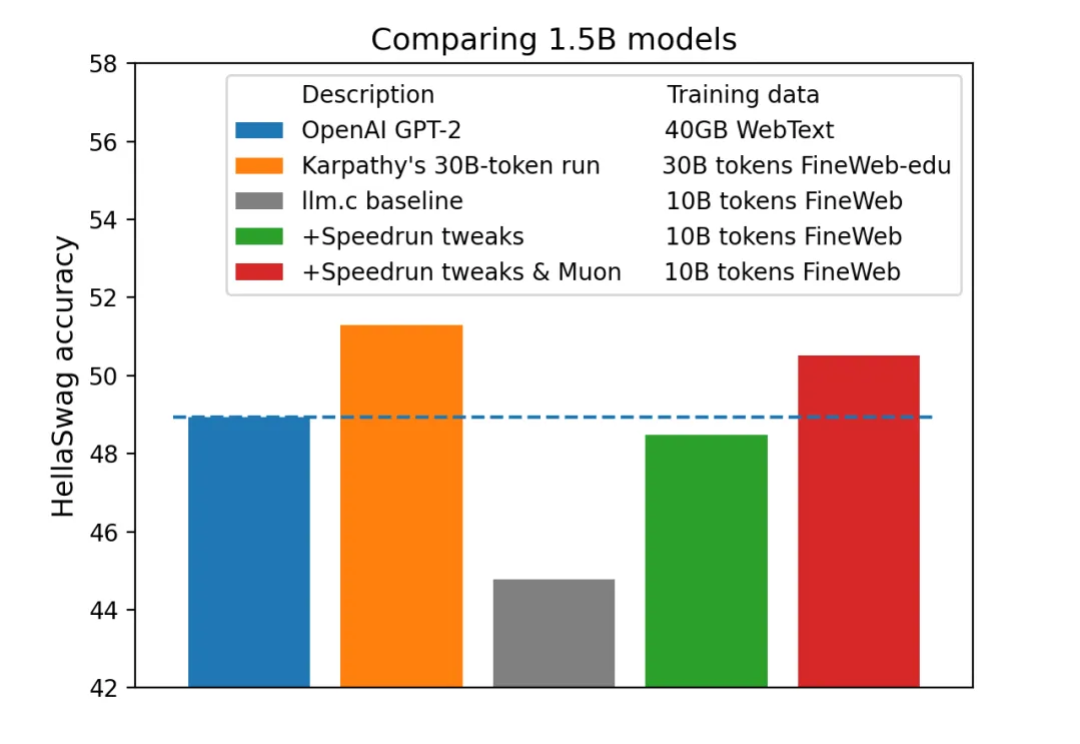
今年 4 月,AI 领域大牛 Karpathy 一个仅用 1000 行代码即可在 CPU/fp32 上实现 GPT-2 训练的项目「llm.c」曾经引发机器学习社区的热烈讨论。
李飞飞谈到的空间智能,被这家中国独角兽补上关键一环。
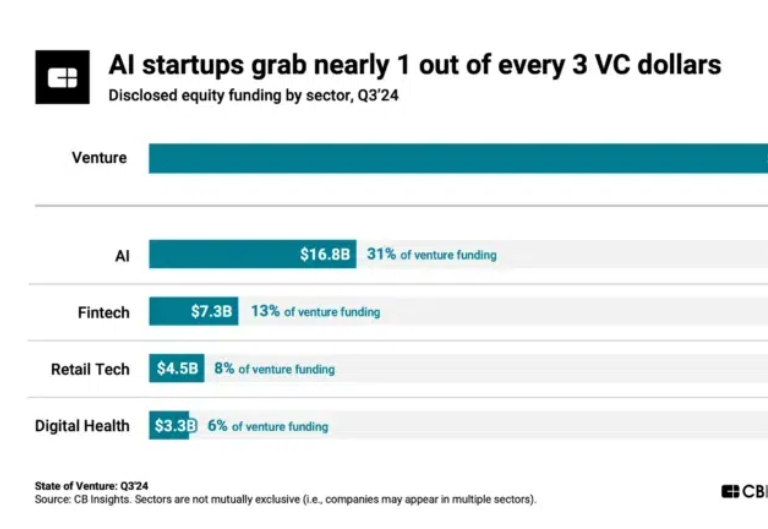
据全球知名创投研究机构 CB Insights 发布的统计数据显示,2024 年第三季度,接近 1/3(31%)的风险投资流入了 AI 初创企业。另根据 Crunchbase 的数据,AI 公司在 2024 年第三季度筹集了 190 亿美元,占所有风险投资的 28%。2024 年第三季度还完成了有史以来最大的风险投资交易:OpenAI 募集了 66 亿美元的巨额资金。

人类离电影《黑客帝国》的场景,似乎又近了一步。
5年,5000万个神经网络,这个世界从未被扫描过的角落,我们都能看到了。宝可梦GO团队,竟然抢先实现了李飞飞的「空间智能」?而「Pokémon Go」的玩家可能没想到,自己居然在训练着一个巨大的AI模型。

顶不住了,真的顶不住。 AI顶会NeurIPS公布了今年「高中组」论文的获奖结果。
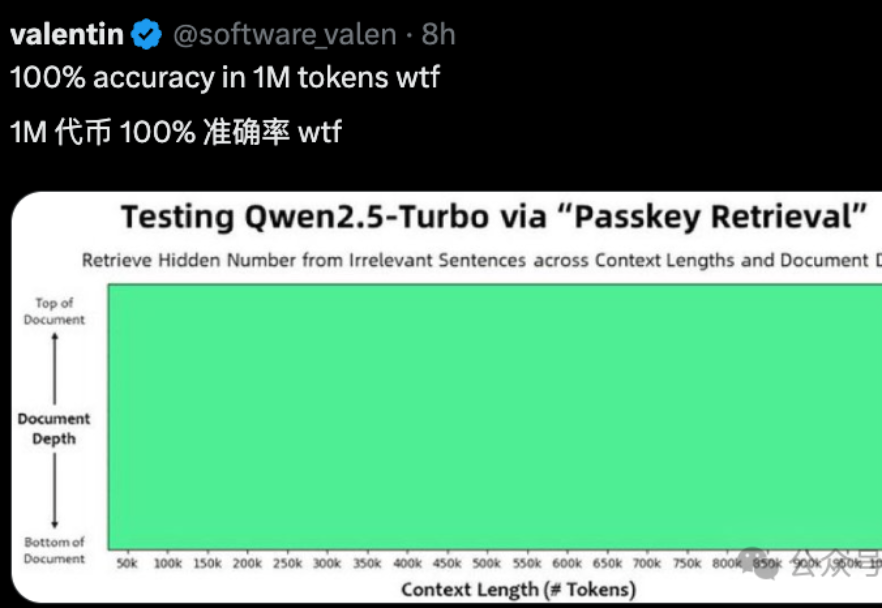
国产大模型,最近有点卷。
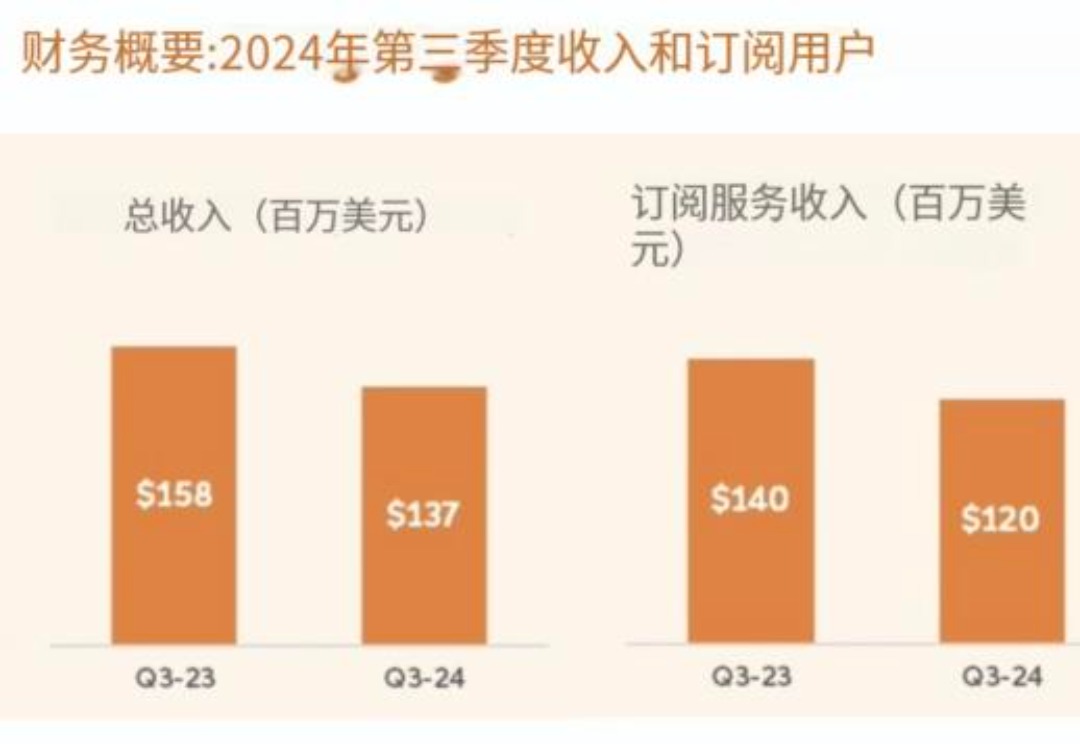
近日,Chegg在向美国证券交易委员会提交的文件中宣布将再裁员441人,自去年以来,这家公司已经裁员两次,去年6月裁员约80人,今年6月裁员319人。自ChatGPT发布以来,Chegg失去了超过50万的付费订阅用户,股价从2021年初的高点下跌了99%。