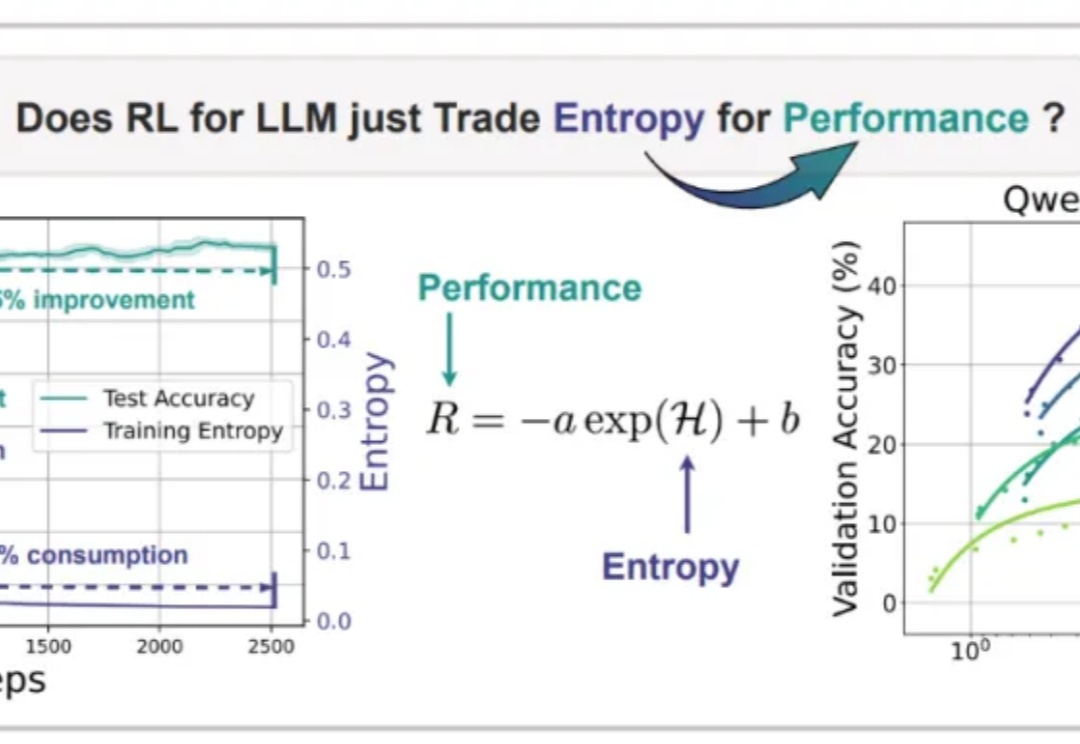
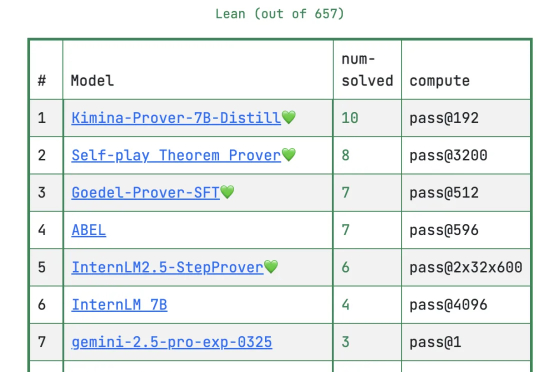
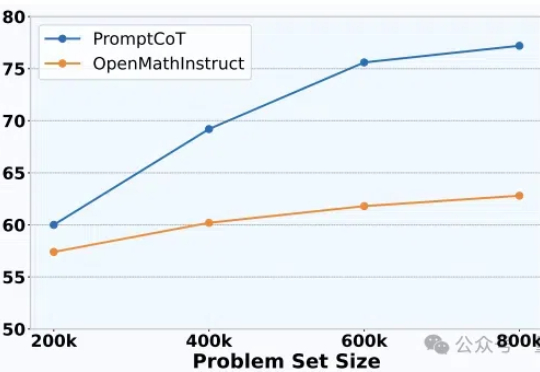
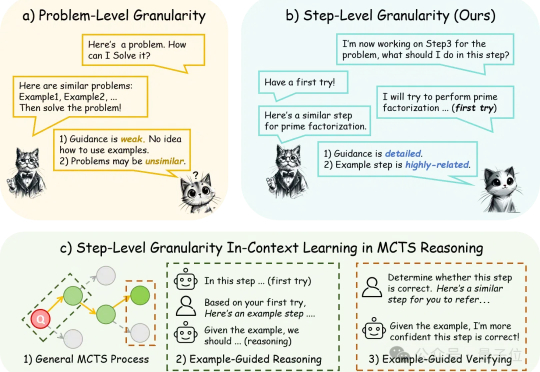
野生DeepSeek火了,速度碾压官方版,权重开源
野生DeepSeek火了,速度碾压官方版,权重开源没等来 DeepSeek 官方的 R2,却迎来了一个速度更快、性能不弱于 R1 的「野生」变体!这两天,一个名为「DeepSeek R1T2」的模型火了!这个模型的速度比 R1-0528 快 200%,比 R1 快 20%。除了速度上的显著优势,它在 GPQA Diamond(专家级推理能力问答基准)和 AIME 24(数学推理基准)上的表现均优于 R1,但未达到 R1-0528 的水平。
来自主题: AI资讯
9762 点击 2025-07-04 22:18