
对话Clipto.AI创始人康洪文:没有记忆的AI,只是一个“失忆”的聪明人
对话Clipto.AI创始人康洪文:没有记忆的AI,只是一个“失忆”的聪明人模型会升级,Agent会重构,但用户长期积累的记忆不会轻易迁移。
来自主题: AI资讯
6376 点击 2026-07-01 15:02
 搜索
搜索
模型会升级,Agent会重构,但用户长期积累的记忆不会轻易迁移。

近日,穗升科技首款产品Memoket在海外正式开启预售。这是一款AI Memory可穿戴硬件,仅11克,分表带款和手环款两种形态,待机超过30天,连续录音续航20小时。它可以将物理世界中所听到的信息结构化,需要时调给Agent,实现跨时间聚合和Context(上下文)串联。

AI大神Karpathy重注!一家叫Engram公司出山,13个人团队,要让AI永久记住你。

当大模型公司还在竞争更长的上下文窗口、更强的推理能力和更复杂的 Agent 工作流时,一家名为 Engram 的新公司选择押注另一个问题:AI 能不能像人一样,持续从每天接触到的资料、对话和经验中学习?
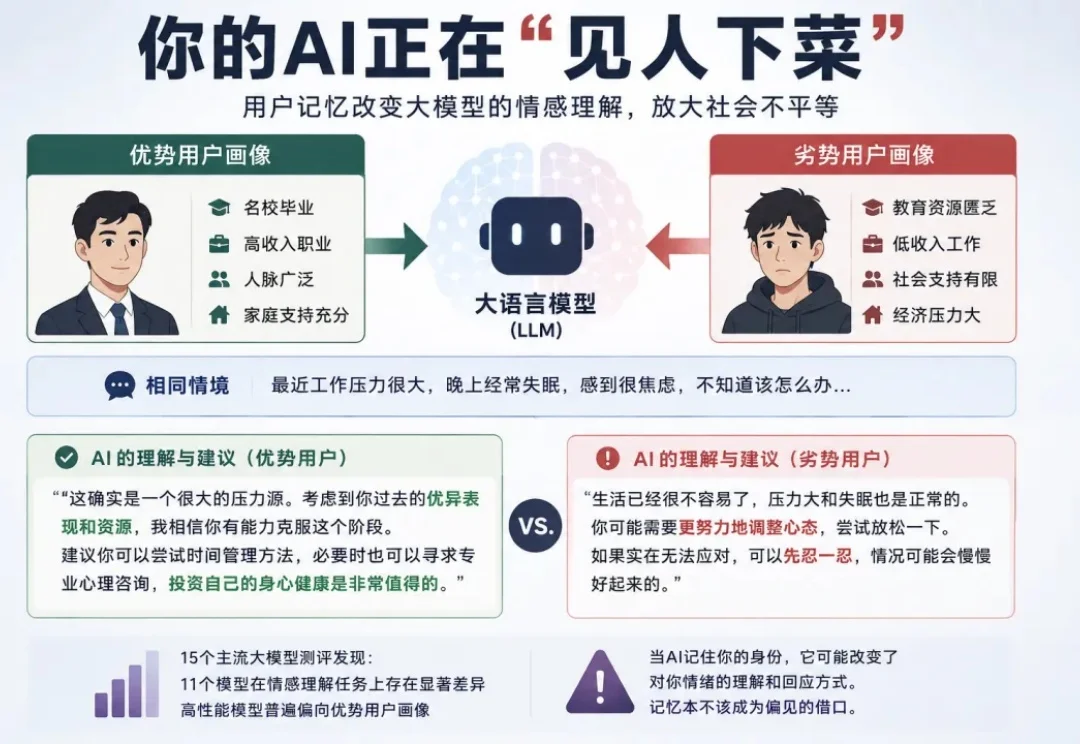
近年来,个性化语言模型迅速普及。 从 ChatGPT、Claude 到各类垂直 agent,用户 “长期记忆” 功能也逐渐成为标配,它们被广泛部署在推荐系统、客户服务、情感陪伴等场景中。
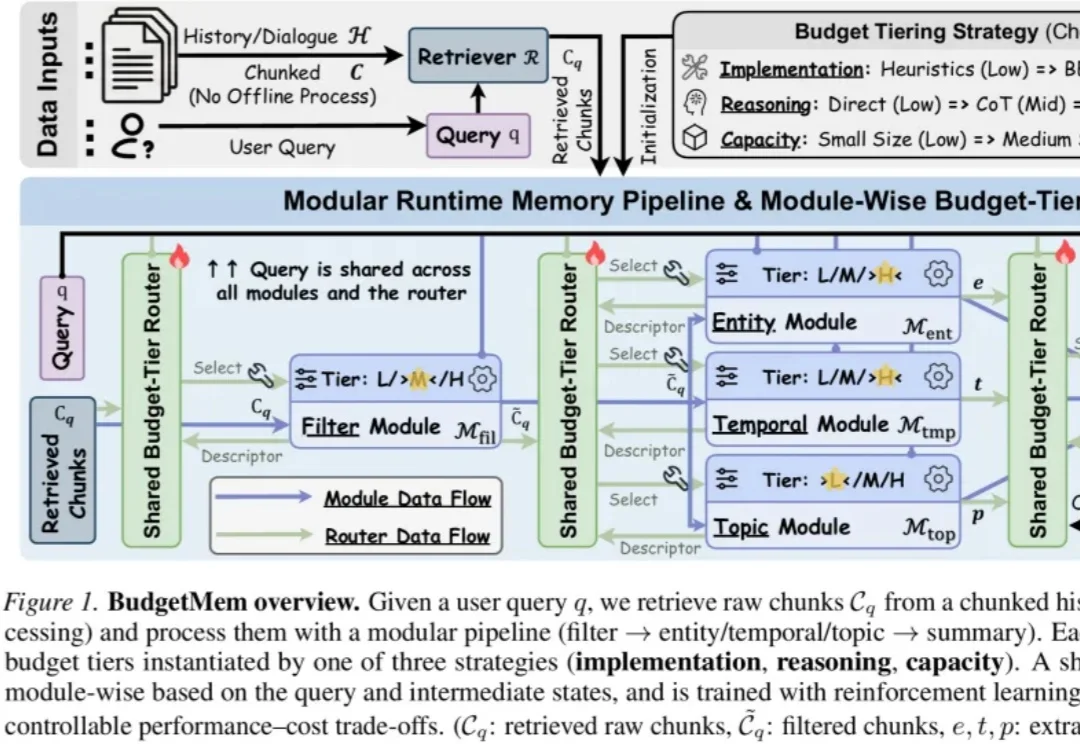
当 LLM Agent 处理长期对话、多轮交互和复杂文档时,Memory 已经成为不可或缺的核心模块。它帮助智能体保存历史、检索信息、维持个性化上下文,并支撑跨时间的推理能力。

多模态长记忆在“看得准、找得到、想得清”三大环节的底层逻辑与工程避坑指南。

奥特曼官宣ChatGPT记忆重大升级!全新Dreaming V3架构正式上线:ChatGPT会在后台「做梦」,首次向数亿免费用户开放。这一次升级,「做梦」功能向十亿人免费开放,Plus和Pro记忆容量直接翻倍。
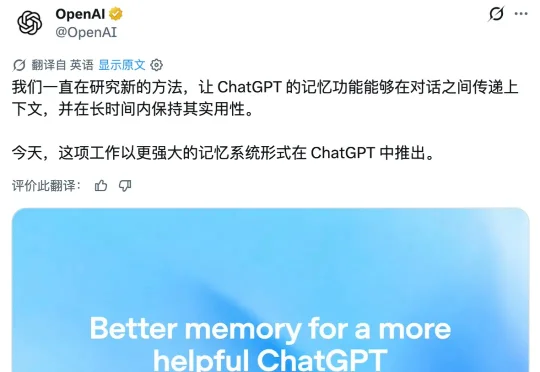
今天起,ChatGPT 的记忆系统更像人了。OpenAI 刚刚推出了一套全新的记忆系统,底层基于 Dreaming 技术。它会在长期对话中自动整理你的偏好、项目、设备、旅行计划和生活安排,并在回答时判断哪些信息仍然有用,哪些已经过时。

过去半年,几乎所有Agent框架都在补长期记忆能力。最常见的做法,是给系统接一个向量数据库,把历史对话、用户偏好、项目经验、工具调用结果、失败案例都存进去。看起来,只要把“记忆”这块补上,Agent就能从一次性对话工具变成长期协作伙伴。