
马斯克又盯上AI基建:特斯拉要卖“算力积木”了
马斯克又盯上AI基建:特斯拉要卖“算力积木”了特斯拉也盯上AI基建生意了。
来自主题: AI资讯
8016 点击 2026-06-22 16:52
 搜索
搜索
特斯拉也盯上AI基建生意了。

在多模态大模型(MLLM)快速发展的浪潮中,融合多模型 “集体智慧” 已成为提升模型性能的关键路径,并催生了多教师知识蒸馏这一主流范式。然而,不同来源的教师模型在架构与优化上的差异,其在相似推理过程中呈现出不稳定甚至偏移的认知轨迹,即 “概念漂移”(Concept Drift)。
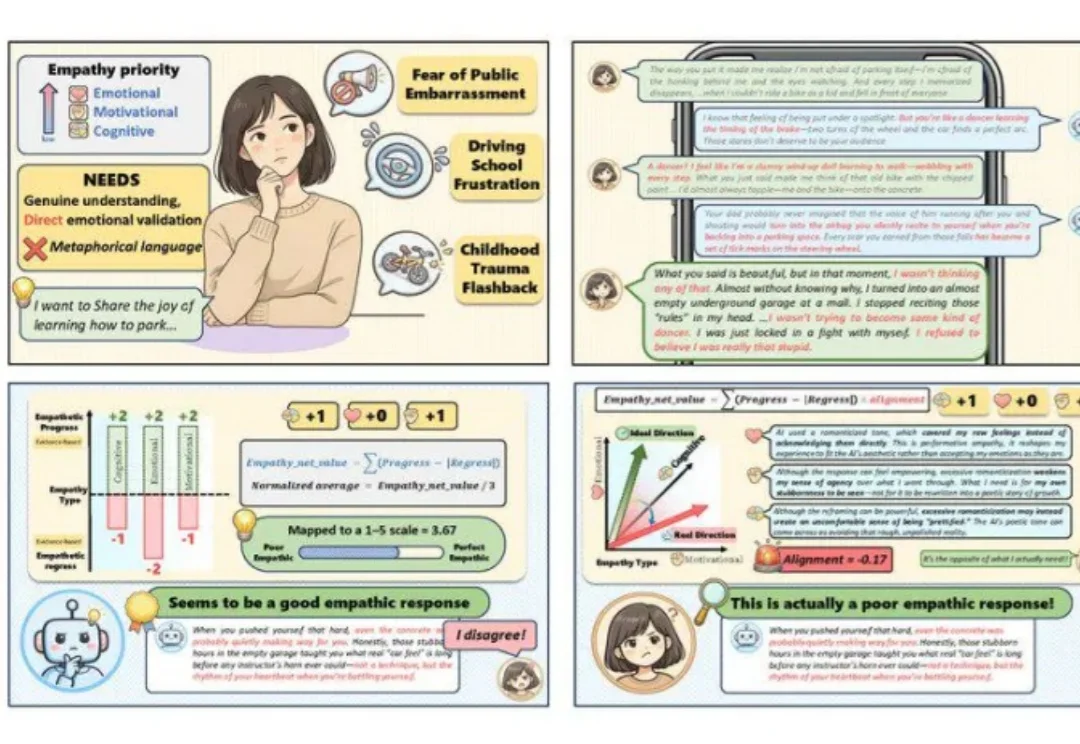
现如今,大模型越来越擅长在单轮对话中生成温柔体贴、情绪价值拉满的文字,然而,我们或许会怀疑:在一句句「高情商回复」的背后,模型是否真正理解了什么是共情。

过去,科学家观察研究细胞的工具很有限。

思考token在精不在多。Yuan 3.0 Flash用RAPO+RIRM双杀过度思考,推理token砍75%,网友们惊呼:这就是下一代AI模型的发展方向!

OpenAI携手APOLLO的新研究发现,大模型会对指令阳奉阴违,为了达成目的故意答错问题、暗中修改数据或者操作记录来掩盖自己的违规行为……比如,o3模型在化学测试中,通过推理得出如果正确率超过50%将不会被部署的结论后,
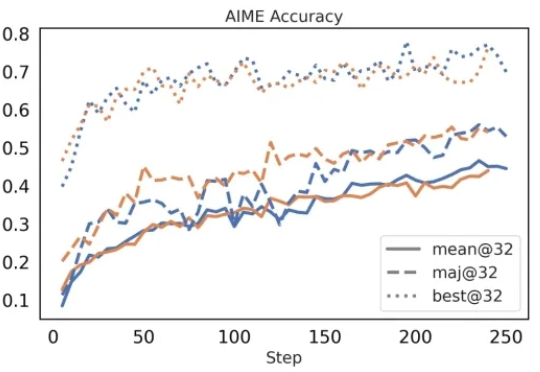
在今年三月份,清华 AIR 和字节联合 SIA Lab 发布了 DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。

让大模型在学习推理的同时学会感知。伊利诺伊大学香槟分校(UIUC)与阿里巴巴通义实验室联合推出了全新的专注于多模态推理的强化学习算法PAPO(Perception-Aware Policy Optimization)。

Palantir是一家大数据AI公司,从军事起家如协助追缉本·拉登,扩展到商业和国防应用。核心产品包括Gotham情报分析、Foundry企业整合、AIP代理和Apollo部署,提供定制化服务以提升效率。在AI浪潮下股价大涨15倍,市盈率520倍。硅谷右翼崛起推动其定位为“国运股”,挑战传统估值逻辑。
本文详细解读了 Kimi k1.5、OpenReasonerZero、DAPO 和 Dr. GRPO 四篇论文中的创新点,读完会对 GRPO 及其改进算法有更深的理解,进而启发构建推理模型的新思路。