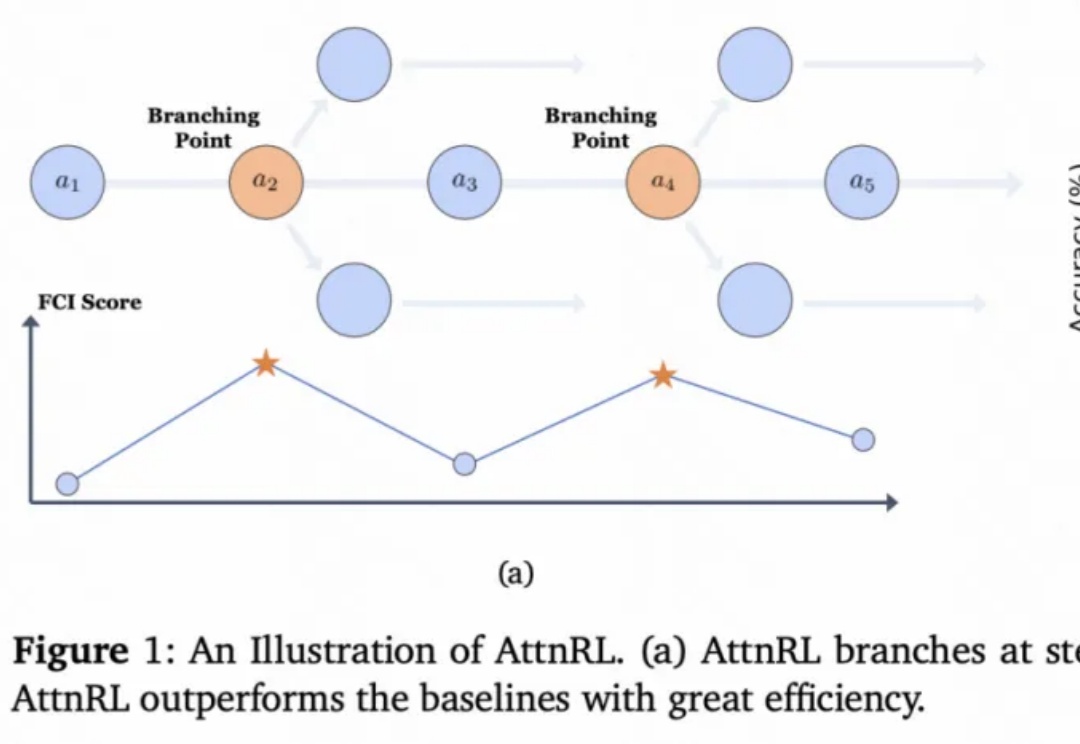
清华、快手提出AttnRL:让大模型用「注意力」探索
清华、快手提出AttnRL:让大模型用「注意力」探索从 AlphaGo 战胜人类棋手,到 GPT 系列展现出惊人的推理与语言能力,强化学习(Reinforcement Learning, RL)一直是让机器「学会思考」的关键驱动力。
来自主题: AI技术研报
8466 点击 2025-10-22 11:46
 搜索
搜索
从 AlphaGo 战胜人类棋手,到 GPT 系列展现出惊人的推理与语言能力,强化学习(Reinforcement Learning, RL)一直是让机器「学会思考」的关键驱动力。