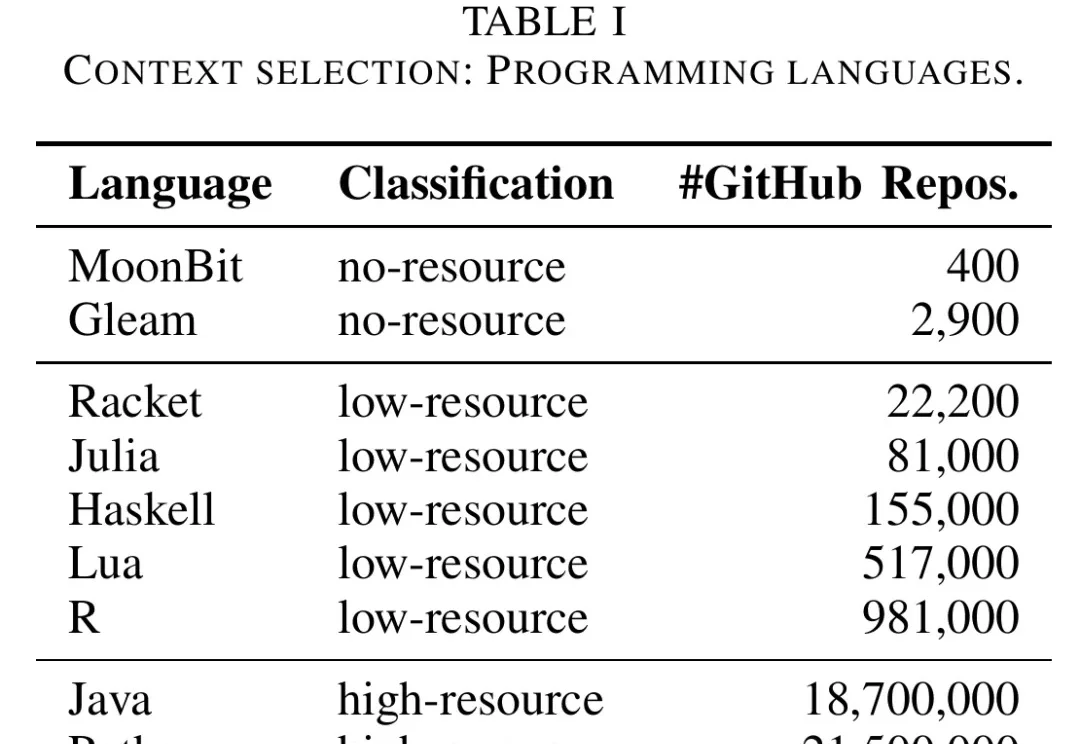
冷门新语言AI写不动?IEEE论文:从零到及格线,MoonBit给出完整训练路线
冷门新语言AI写不动?IEEE论文:从零到及格线,MoonBit给出完整训练路线对于Python、Java、JavaScript这些语言,大模型通常能给出相当成熟的答案。
来自主题: AI技术研报
5709 点击 2026-07-01 15:03
 搜索
搜索
对于Python、Java、JavaScript这些语言,大模型通常能给出相当成熟的答案。

当整个 AI 圈都在翘首以盼 Sam Altman 和前苹果首席设计官 Jony Ive 能联手掏出一部 AI 时代的 iPhone 时,OpenAI 今天却猝不及防地公布了一个键盘。
昨晚,美国开源AI初创公司Reflection AI宣布,已与SpaceXAI签署算力协议,将获得Colossus 2数据中心的额外算力支持,用于训练和迭代更强的开放模型。另据TechCrunch报道,Reflection AI将从2026年7月1日起,每月支付1.5亿美元(约合人民币10.2亿元),

Meta 已与数据中心开发商 Crusoe 达成新协议,获取 AI 计算能力,以增强其支持雄心勃勃的人工智能扩展所需的基础设施。据知情人士透露,Meta 已签约从 Crusoe 的两个数据中心购买计算容量。这些设施分别位于德克萨斯州柴尔德里斯和密苏里州沃伦顿,由于讨论内容未公开,上述人士要求匿名。

刚刚,在维也纳落幕的机器人顶会ICRA 2026上,最佳论文奖(自动化方向)颁给了一支中国团队。
最新开源的Unlimited OCR,总参数3B,实际激活仅500M——放在大模型时代几乎是个零头。但就是这个小到离谱的模型,在OmniDocBench v1.5上拿下93.23%的综合分,v1.6更是达到93.92%,直接刷新了端到端SOTA。

大模型再强,也读不懂你公司那一柜子的合同、发票和扫描件。在"纸张世界"和"LLM世界"之间,缺一座桥——而百度开源的 PaddleOCR,可能就是当下最稳的那座。
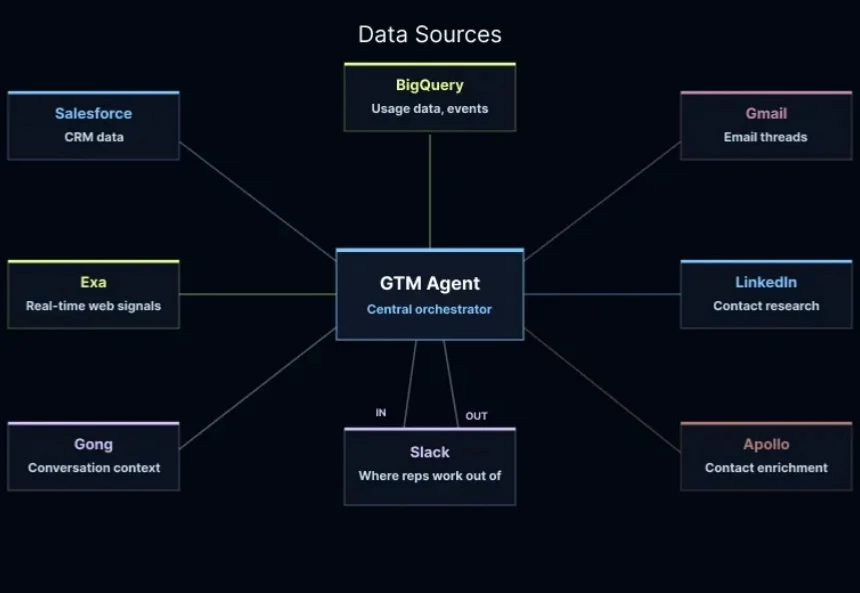
你有没有想过,销售这件事可能会被彻底重新定义?不是那种换个 CRM 系统或者学几个销售话术的小改进,而是从根本上改变销售人员的日常工作方式。

最近几个月,海外主流社交平台X、YouTube、Instagram、LinkedIn、Facebook等的头部内容创作者,开始高频地提及同一个名字——AhaCreator 3.0。从科技博主、消费电子达人,到跨境电商品牌主理人,再到拥有百万粉丝的内容创作者,越来越多人在自己的内容中分享使用体验。
最近刷资讯的时候,我看到好几个海外大V都在推一个叫 AhaCreator 的产品,是一个 AI 达人接单平台,视频播放量和互动数据都还挺不错。