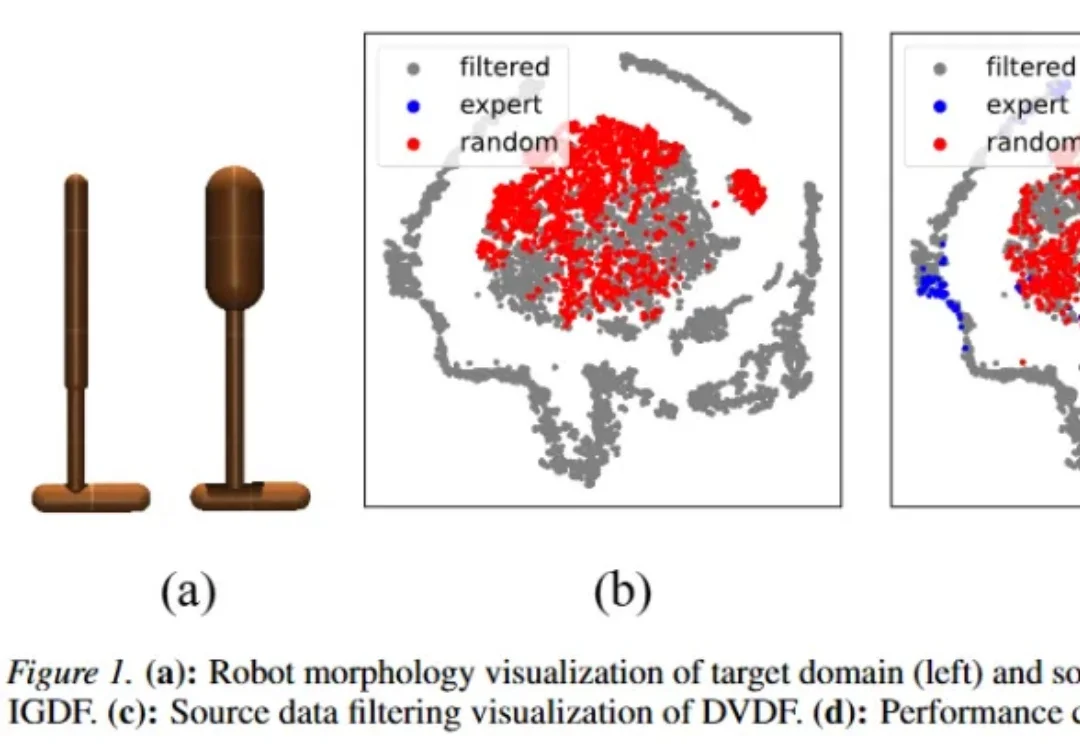
重构跨域RL框架!理论驱动「双重对齐」让跨域迁移「质变」
重构跨域RL框架!理论驱动「双重对齐」让跨域迁移「质变」在现实世界中通过强化学习训练智能体,往往需要大量在线试错与环境探索,这不仅成本高昂,还可能带来显著安全风险:机器人可能因试错而损坏,自动驾驶的在线探索可能危及行车安全,而持续采集交互数据本身也代价巨大。
来自主题: AI技术研报
8600 点击 2026-04-03 09:25
 搜索
搜索
在现实世界中通过强化学习训练智能体,往往需要大量在线试错与环境探索,这不仅成本高昂,还可能带来显著安全风险:机器人可能因试错而损坏,自动驾驶的在线探索可能危及行车安全,而持续采集交互数据本身也代价巨大。