当SFT遇上RL:基于样本学习阶段的动态策略优化机制
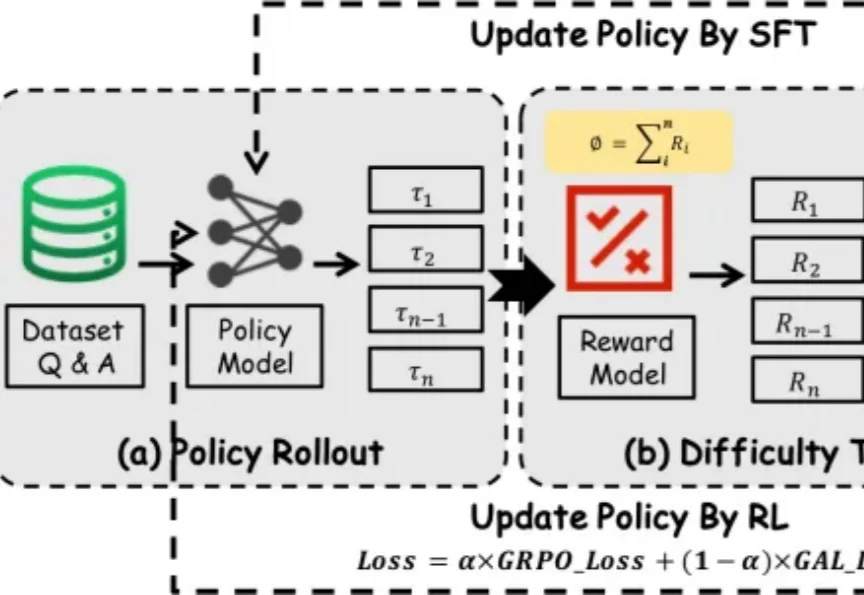
当SFT遇上RL:基于样本学习阶段的动态策略优化机制过去一段时间里,在围绕大模型推理能力增强的研究中,SFT 和 RL 是两类核心后训练范式 —— 前者稳定收敛快,能高效吸收高质量推理数据;后者更具探索性,有望推动模型实现复杂推理和分布外泛化。
来自主题: AI技术研报
6977 点击 2026-05-18 09:53
 搜索
搜索
过去一段时间里,在围绕大模型推理能力增强的研究中,SFT 和 RL 是两类核心后训练范式 —— 前者稳定收敛快,能高效吸收高质量推理数据;后者更具探索性,有望推动模型实现复杂推理和分布外泛化。