
Nature: AI医生MIRA首次“全流程上岗”
Nature: AI医生MIRA首次“全流程上岗”2026年6月17日,Nature 刊登了一项里程碑式的研究,来自海德堡大学医院的研究团队开发了一个名为MIRA(Medical Intelligence for Reasoning and Action) 的自主医疗AI智能体。
来自主题: AI技术研报
7959 点击 2026-06-29 10:20
 搜索
搜索
2026年6月17日,Nature 刊登了一项里程碑式的研究,来自海德堡大学医院的研究团队开发了一个名为MIRA(Medical Intelligence for Reasoning and Action) 的自主医疗AI智能体。

近期Radical AI 的 CEO Joseph Krause接受了一次深度访谈,在访谈中,他揭开了现在资本热炒的 “AI for Science” 的虚假外衣。如果你以为搞材料研发只要像生物制药一样,用大模型在云端“跑个分”就能大力出奇迹,那这期节目会给你狠狠上一课,你会发现,真正的材料学 AI 护城河,离我们简单的想象差了十万八千里。
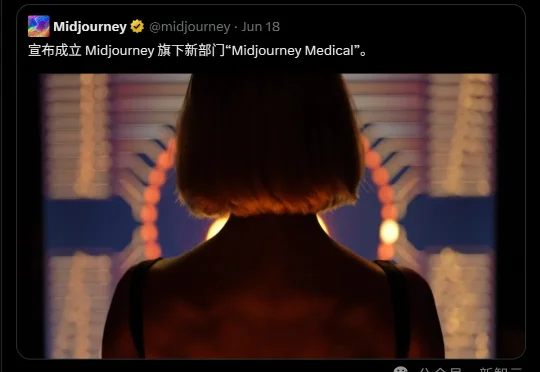
AI画图巨头突然杀入医疗圈!60秒泡个澡就能完成全身扫描,0.5毫米精度碾压CT和MRI,4PFlops的算力怪兽,让医疗行业今夜无眠。最惊人的是,Midjourney的终极目标竟是延长人类寿命,消灭全球30%的死亡。

搞AI绘画的Midjourney,要干上Spa了???
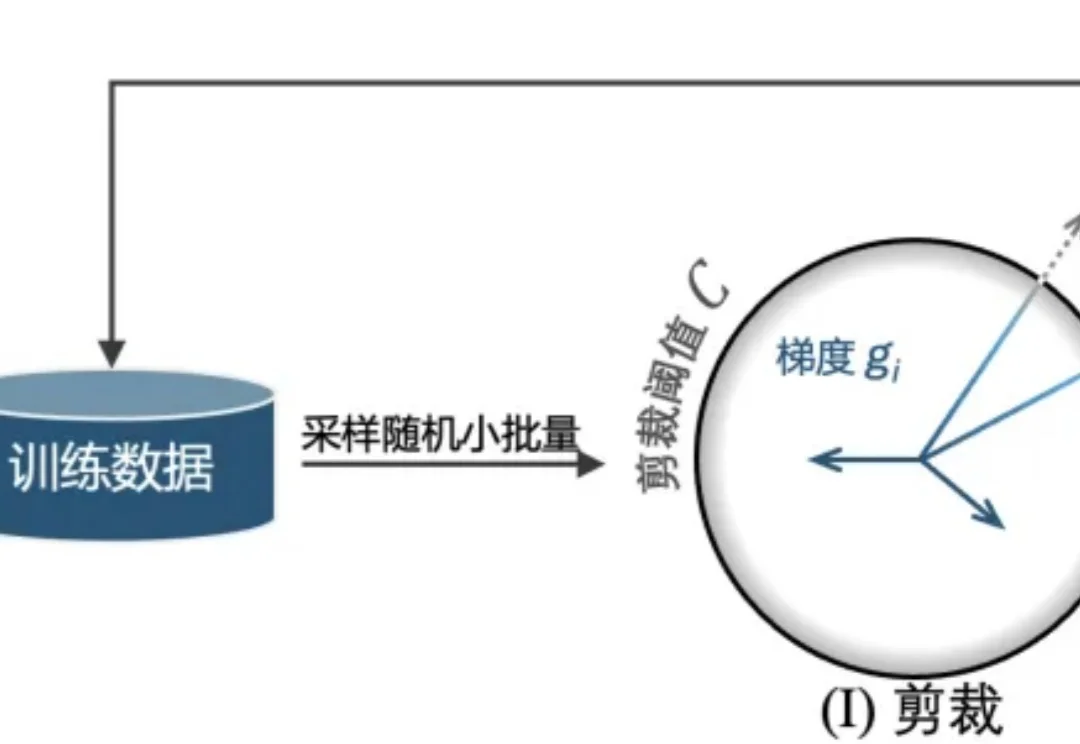
近日,来自英国南安普顿大学(University of Southampton)和广州大学的研究者团队提出 SlaClip,一种用于差分隐私随机梯度下降(DP-SGD)[1] 的自适应梯度剪裁方法。
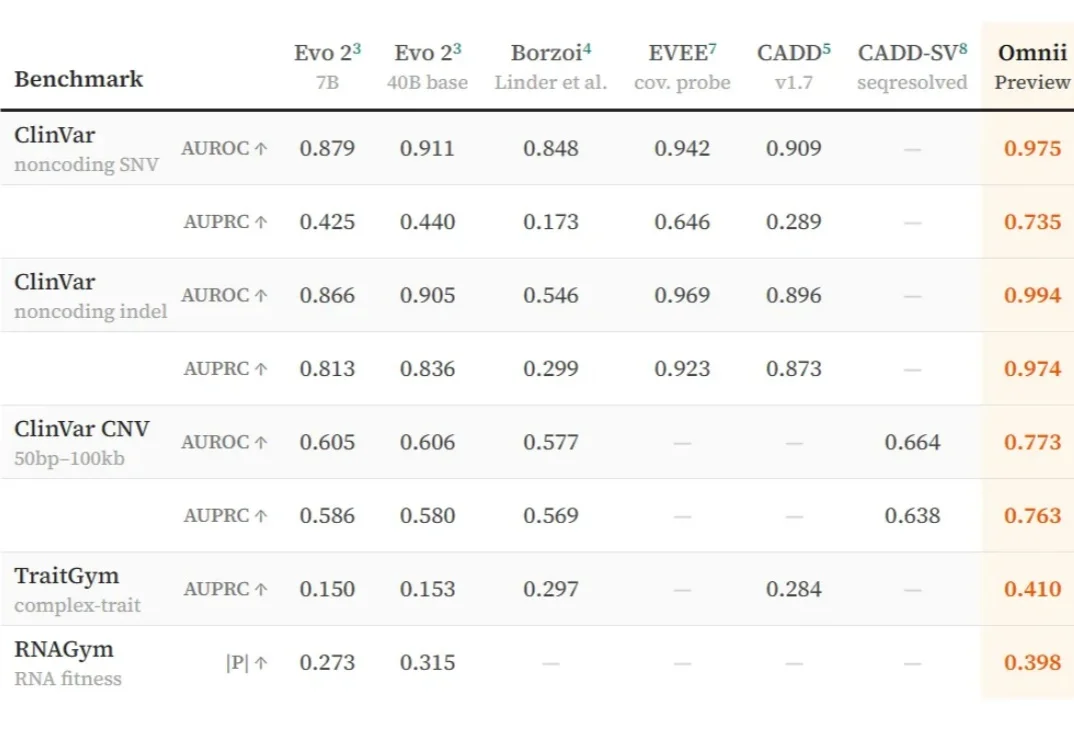
最大生物学AI模型Evo2的幕后团队,要把所有生物信息整合到一套AI里!

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。

就在昨天,外媒The Information爆料——前阿里巴巴千问大模型负责人林俊旸创办的AI实验室已经完成首轮融资,融资总额达数亿美元,投后估值达20亿美元!其中,红杉中国、高榕资本各投1亿美元领投,互联网巨头腾讯狂掷2000万美元跟投。
如果把一个商业化产品、一个科技公司的底层系统比作一棵树,那任意挑出一个项目,层层抽丝剥茧之后,你一定会发现,最早的年轮,一定与开源有关。
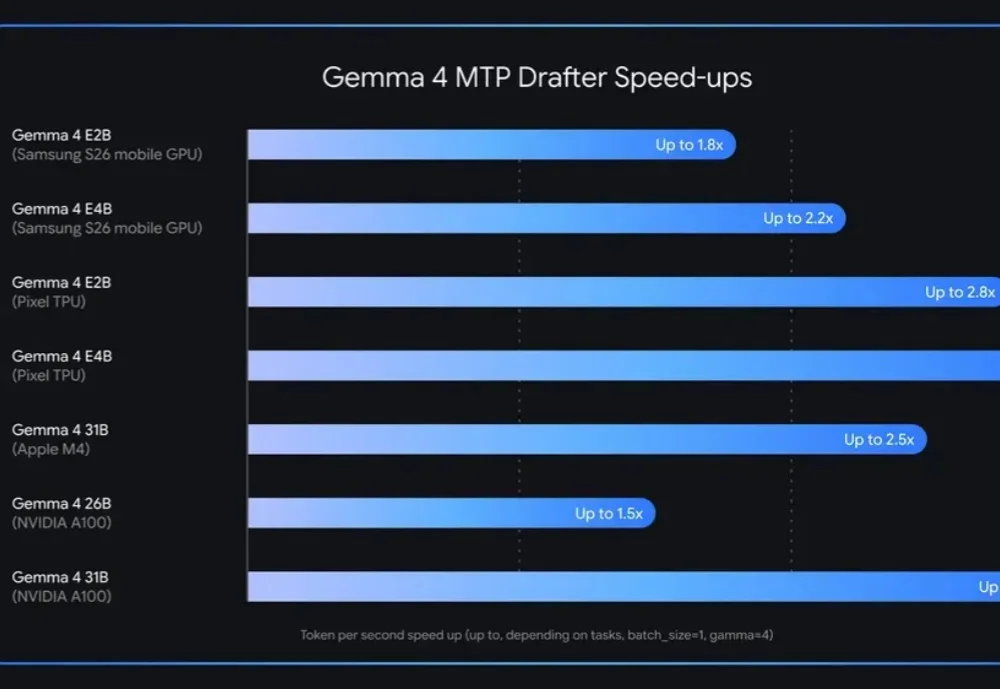
谷歌刚刚给Gemma 4家族更新了一项关键能力:Multi-Token Prediction(MTP)推测解码架构,推理速度最高提升3倍,输出质量不变。