用AI读懂施工图纸,Meta前AI科学家创业,融资10M,杨立昆押注 | 附8个DEMO
用AI读懂施工图纸,Meta前AI科学家创业,融资10M,杨立昆押注 | 附8个DEMO1天前,2026年4月,Primepoint完成了$10M种子轮融资。对一家成立仅两年、团队不足10人的公司而言,这个数字不算小。更值得关注的是投资人结构:深度学习先驱Yann LeCun亲自下注,多家专注建筑科技的头部VC联合跟投。
来自主题: AI资讯
9159 点击 2026-04-20 15:14
 搜索
搜索
1天前,2026年4月,Primepoint完成了$10M种子轮融资。对一家成立仅两年、团队不足10人的公司而言,这个数字不算小。更值得关注的是投资人结构:深度学习先驱Yann LeCun亲自下注,多家专注建筑科技的头部VC联合跟投。
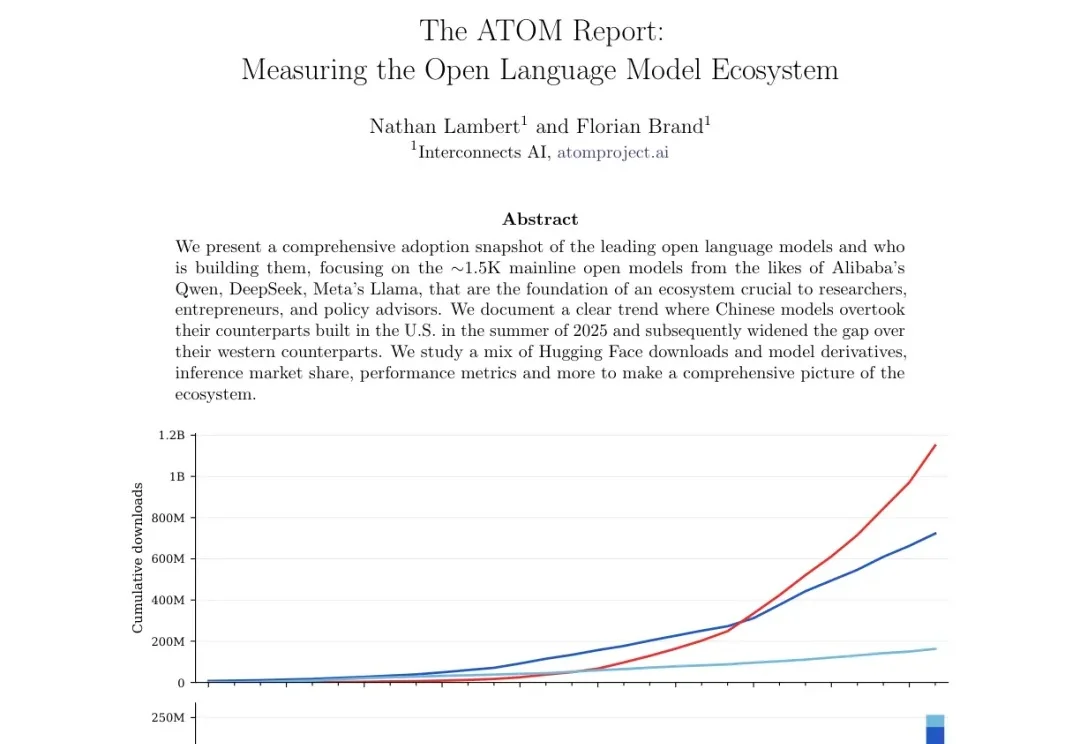
2026 年 4 月,Nathan Lambert 和 Florian Brand 发布了 The ATOM Report,一份关于开源语言模型生态的综合采纳度快照。这份报告追踪了约 1500 个主线开源模型的下载量、衍生模型、推理市场份额和性能数据,覆盖 2023 年 11 月到 2026 年 3 月
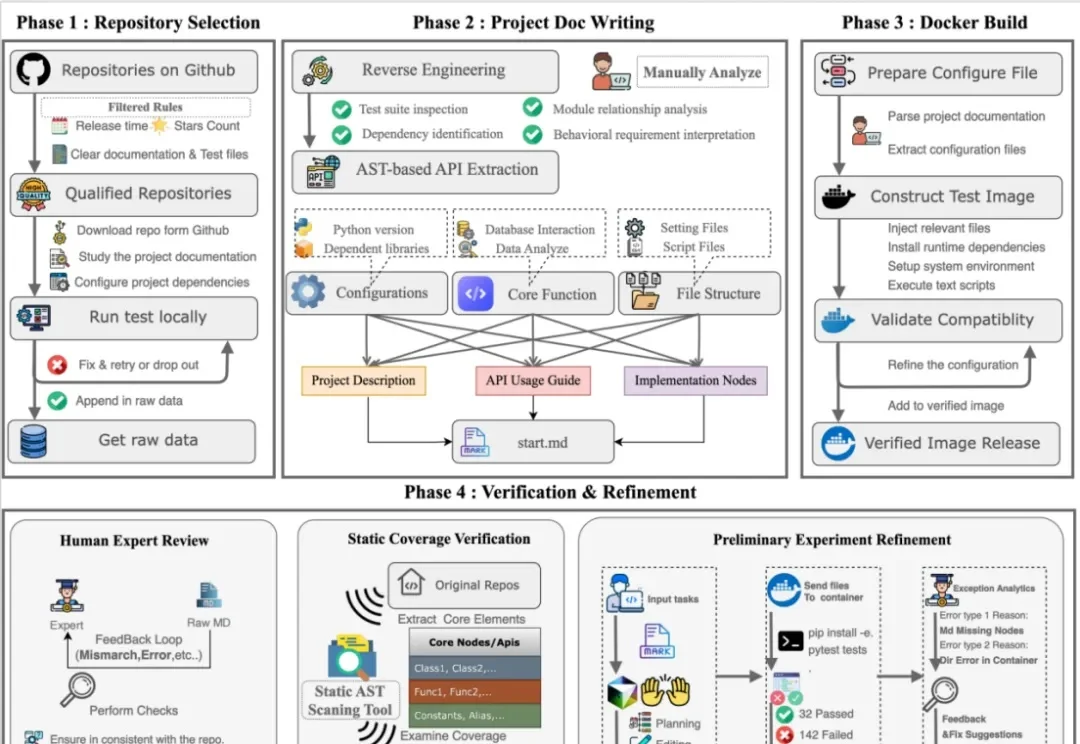
在 AI 编程领域,大家似乎正处于一个认知错觉的顶点:随着 Coding Agents 独立完成任务的难度和范围逐渐增加,Coding 领域的 AGI 似乎就可以实现?
《晚点 LatePost》独家获悉,快手旗下视频生成大模型可灵 AI 的月活跃用户(MAU)在今年 1 月突破 1200 万。

2025 年 9 月,The Information 报道 Anthropic 曾讨论在接下来一年内投入超过 10 亿美元用于 RL 环境建设。Epoch AI 最近发了一篇报告,采访了 18 位来自 RL 环境初创公司、neolab(Cursor 这类应用型 AI 公司)和前沿实验室的从业者
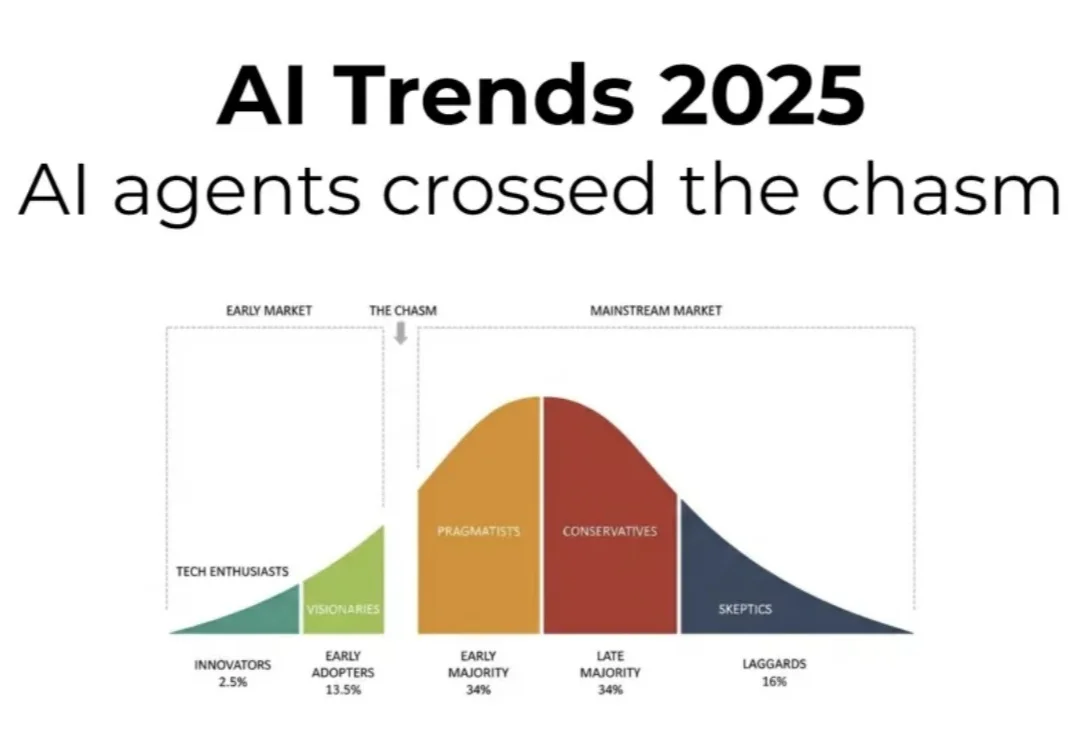
2025 年,AI 智能体“跨过了鸿沟”,开始被更广泛、务实的用户群体采用,不再只是少数发烧友或愿景家在用。
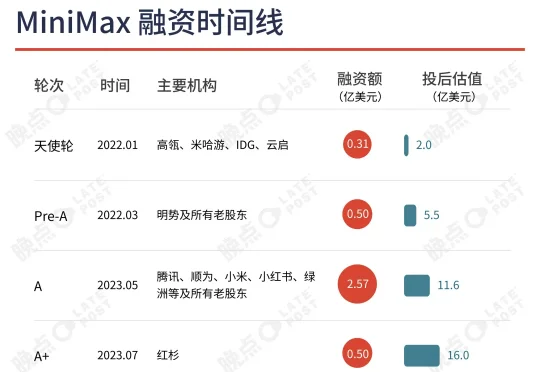
在今天(1 月 9 日)早上前往港交所敲钟前,MiniMax 创始人闫俊杰对《晚点 LatePost》分享了他此刻的想法:希望我们后续能有机会对整个行业智能水平的提升做出更大的贡献。我们初步探索了一条纯草根 AI 创业的路径,尽管后面还是非常挑战,如果能对 AI 创新创业生态的发展有启发我们会感到很光荣。
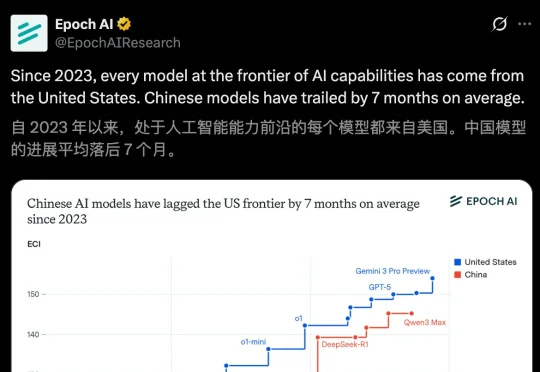
一张来自Epoch AI图表给出了一个冷静却尖锐的结论:中国AI平均落后7个月。一张图揭示真相:自2023年以来,前沿AI全部来自美国!最近,Epoch AI一份报告指出,中国AI模型的进展平均落后于美国7个月——最小差距为4个月,最大差距为14个月。

Epoch AI年终大盘点来了!出乎意料的是,AI没有停滞,反而变快了。

《晚点 LatePost》独家获悉,火山引擎将成为 2026 年中央广播电视总台春节联欢晚独家 AI 云合作伙伴,字节跳动旗下的智能助手豆包也将配合上线多种互动玩法,抖音曾于 2019 年与 2021 年两次成为春晚的独家互动平台。