
Google尚未实现AGI,它的前员工号称搞定了
Google尚未实现AGI,它的前员工号称搞定了2025 年 12 月的第二周,一则颇为吸睛的消息从东京传出:一家名为 Integral AI 的初创公司宣布,他们已经成功测试出“世界上第一个具备 AGI 能力的模型”。AGI,即 Artificial General Intelligence(通用人工智能),向来被视为 AI 领域的终极圣杯。
来自主题: AI资讯
8891 点击 2025-12-11 16:06
 搜索
搜索
2025 年 12 月的第二周,一则颇为吸睛的消息从东京传出:一家名为 Integral AI 的初创公司宣布,他们已经成功测试出“世界上第一个具备 AGI 能力的模型”。AGI,即 Artificial General Intelligence(通用人工智能),向来被视为 AI 领域的终极圣杯。
今年 10 月,专注构建世界模型的 General Intuition 完成了高达 1.34 亿美元的种子轮融资。这笔融资由硅谷传奇投资人 Vinod Khosla 领投,这是他自 2019 年首次投资 OpenAI 以来开出的最大单笔种子轮投资,也标志着他在 LLM 之后对下一代智能范式做出的一次重大下注。
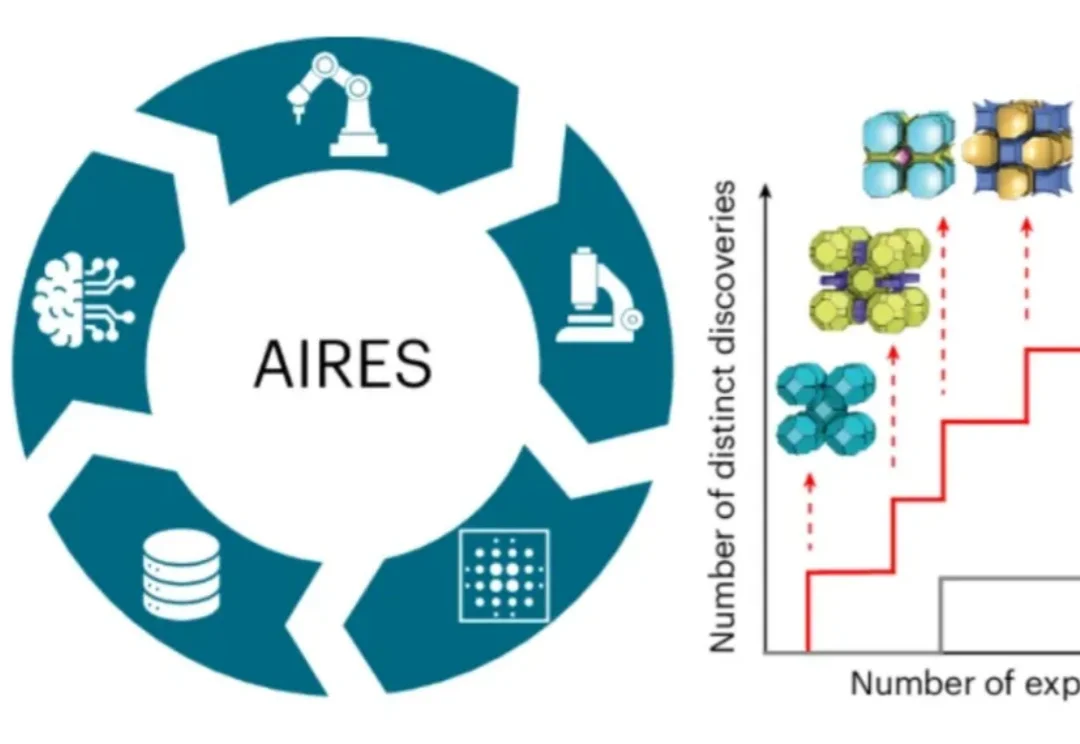
近日,师从新晋诺贝尔化学奖得主奥马尔·亚吉(Omar M. Yaghi)、目前在美国加州大学伯克利分校读博的荣自超,带领一个跨国际的研究团队,打造出名为AIRES (algorithmic iterative reticular synthesis)的机器学习指导的高通量实验平台,
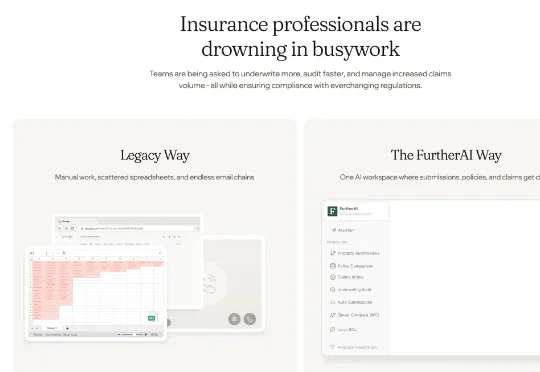
一家名为 FurtherAI 的创业公司宣布完成了 2500 万美元的 A 轮融资,由硅谷顶级风投 Andreessen Horowitz 领投。这是保险 AI 领域有史以来最大的 A 轮融资之一。更令人惊讶的是,这轮融资距离他们 500 万美元的种子轮仅仅过去了六个月。

据知情人士透露,开发客户服务人工智能的德国初创公司Parloa正在寻求新一轮融资,估值将较今年5月大幅提升。这家在德国和纽约设有办公室的公司,已与包括General Catalyst在内的投资者进行了洽谈,寻求筹集约2亿美元的新资金。知情人士称,Parloa正在讨论的潜在估值区间约为20亿至30亿美元。
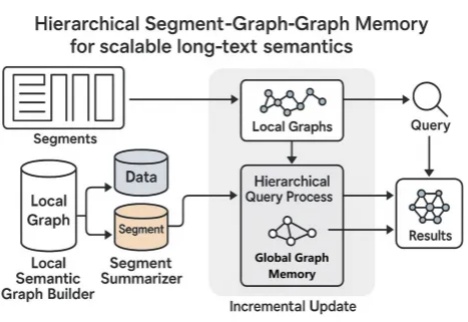
当你阅读《红楼梦》《哈利·波特》《百年孤独》等长篇小说时,读着读着可能就忘记前面讲了什么,有时还会搞混人物关系。AI 在阅读长文章的时候也存在类似问题,当文章太长时它也会卡主,要么读得特别慢,要么记不住前面的内容。

大家好,我是袋鼠帝。 今天想跟大家聊聊最近很火的一个新概念:GEO
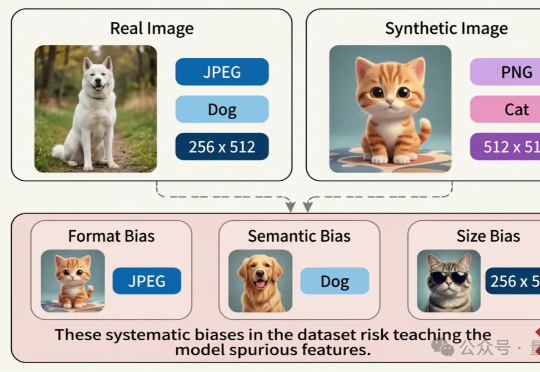
近日,腾讯优图实验室联合华东理工大学、北京大学等研究团队在A生成图像检测(AI-Generated Image Detection)泛化问题上展开研究,提出Dual Data Alignment(双重数据对齐,DDA)方法,从数据层面系统性抑制“偏差特征”,显著提升检测器在跨模型、跨数据域场景下的泛化能力。
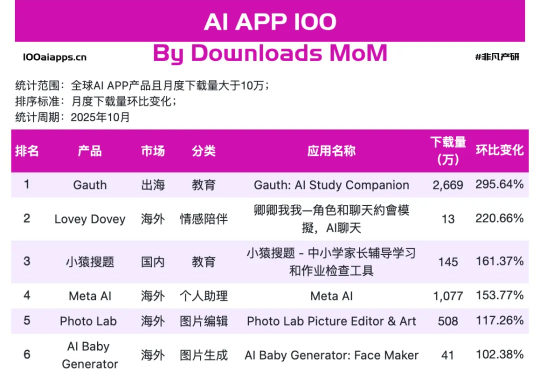
但当我们把视线从焦点模型上,挪到手机里AI应用真实数据上,就会发现一幅不同的画面。可以看到在非凡产研 10 月 AI App 增速榜上,跑得最快的那 17 个,并不是万事皆可聊的通用助手,而是一群看上去有点普通、甚至有点土气的小应用,其中Gauth、Starry、Knowunity、AI Baby Generator已经连续两个月上榜了。

「Vibe Coding 肯定是有 PMF 的,但 Vibe Coding 产品其实还没找到自己的 PMF。」AI Coding 明星产品 Lovable 的增长负责人 Elena Vera,在一次采访中明确说道。来自 The Information 数据,以 Cursor、Claude Code 为代表的 AI Coding 工具的累计营收,已经突破了 31 亿美元。